A Watermark for Large Language Models
2301.10226
4
88
💬
Abstract
Potential harms of large language models can be mitigated by watermarking model output, i.e., embedding signals into generated text that are invisible to humans but algorithmically detectable from a short span of tokens. We propose a watermarking framework for proprietary language models. The watermark can be embedded with negligible impact on text quality, and can be detected using an efficient open-source algorithm without access to the language model API or parameters. The watermark works by selecting a randomized set of green tokens before a word is generated, and then softly promoting use of green tokens during sampling. We propose a statistical test for detecting the watermark with interpretable p-values, and derive an information-theoretic framework for analyzing the sensitivity of the watermark. We test the watermark using a multi-billion parameter model from the Open Pretrained Transformer (OPT) family, and discuss robustness and security.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper proposes a method to embed watermarks into the output of large language models, which can help mitigate potential harms from misuse.
- The watermark is invisible to humans but can be algorithmically detected, allowing the source of the text to be identified.
- The watermarking process has a negligible impact on the quality of the generated text and can be detected using an open-source algorithm without access to the model itself.
Plain English Explanation
The paper describes a way to "watermark" the text generated by large language models, such as GPT-3 or OpenAI's language models. A watermark is a hidden signal that can be detected, similar to how a watermark can be seen in certain types of paper.
The key idea is to subtly modify the language model's output in a way that is unnoticeable to humans, but can be detected by a special algorithm. This allows the source of the text to be traced back to the original language model, even if the text is shared or used elsewhere.
For example, imagine a scenario where someone tries to pass off text generated by a large language model as their own original writing. The watermarking system proposed in this paper could help identify that the text was actually generated by the language model, preventing the deception.
The watermarking process works by randomly selecting certain words in the generated text and slightly biasing the language model to use those words. This creates a statistical pattern in the text that can be detected by an analysis algorithm, but does not significantly affect the quality or readability of the output.
The paper tests this watermarking approach on a large, multi-billion parameter language model and discusses its robustness and security against attempts to remove or bypass the watermark. Overall, this research offers a promising way to trace the origin of text generated by powerful language models, which could help address potential misuse or abuse.
Technical Explanation
The paper proposes a watermarking framework for proprietary language models, where a randomized set of "green" tokens are softly promoted during the text generation process. This creates a statistical pattern in the output that can be detected by an efficient open-source algorithm, without requiring access to the language model's API or internal parameters.
The watermarking process works by selecting a set of green tokens before each word is generated, and then increasing the probability of those green tokens being used during the sampling process. This has a negligible impact on the overall quality and fluency of the generated text, as the language model is still free to choose the most appropriate words based on the context.
The paper introduces a statistical test for detecting the watermark, which provides interpretable p-values to quantify the confidence in the watermark detection. An information-theoretic framework is also developed to analyze the sensitivity of the watermark and understand the trade-offs between watermark strength and text quality.
The researchers evaluate the watermarking approach using a multi-billion parameter language model from the Open Pretrained Transformer (OPT) family. They discuss the robustness of the watermark against various attacks, such as fine-tuning the language model or attempting to remove the watermark, and explore the security implications of the proposed framework.
Critical Analysis
The paper presents a compelling approach for watermarking the output of large language models, which could be a valuable tool for addressing concerns about the potential misuse of these powerful AI systems. The authors have carefully designed the watermarking process to have a minimal impact on the quality of the generated text, and the proposed detection algorithm is efficient and does not require access to the language model's internal structure.
However, the paper does acknowledge some limitations and areas for further research. For example, the authors note that the watermark may be vulnerable to more sophisticated attacks, such as those that attempt to learn the watermarking pattern or generate text on specific topics to avoid detection.
Additionally, while the proposed watermarking framework is designed to be robust and efficient, there may be concerns about the broader implications of embedding hidden signals into language model outputs, and the potential for misuse or abuse of the watermarking technology itself.
Overall, this research represents an important step forward in addressing the challenges posed by large language models, and the watermarking approach could be a valuable tool for enhancing the reliability and trustworthiness of these AI systems. However, continued research and careful consideration of the potential risks and limitations will be essential as this technology continues to evolve.
Conclusion
The paper presents a novel watermarking framework for proprietary language models, which can help mitigate potential harms from the misuse of these powerful AI systems. The proposed watermarking approach embeds an invisible signal into the generated text that can be algorithmically detected, allowing the source of the text to be identified.
The watermarking process has a negligible impact on the quality of the generated text and can be detected using an efficient open-source algorithm, without requiring access to the language model's internal structure. This research offers a promising solution for enhancing the reliability and trustworthiness of large language models, and could have important implications for addressing concerns about the potential misuse of these AI systems.
While the paper acknowledges some limitations and areas for further research, the watermarking approach represents a significant step forward in the ongoing efforts to develop safe and responsible AI technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
Learnable Linguistic Watermarks for Tracing Model Extraction Attacks on Large Language Models
Minhao Bai, Kaiyi Pang, Yongfeng Huang
0
0
In the rapidly evolving domain of artificial intelligence, safeguarding the intellectual property of Large Language Models (LLMs) is increasingly crucial. Current watermarking techniques against model extraction attacks, which rely on signal insertion in model logits or post-processing of generated text, remain largely heuristic. We propose a novel method for embedding learnable linguistic watermarks in LLMs, aimed at tracing and preventing model extraction attacks. Our approach subtly modifies the LLM's output distribution by introducing controlled noise into token frequency distributions, embedding an statistically identifiable controllable watermark.We leverage statistical hypothesis testing and information theory, particularly focusing on Kullback-Leibler Divergence, to differentiate between original and modified distributions effectively. Our watermarking method strikes a delicate well balance between robustness and output quality, maintaining low false positive/negative rates and preserving the LLM's original performance.
5/3/2024
💬
On the Reliability of Watermarks for Large Language Models
John Kirchenbauer, Jonas Geiping, Yuxin Wen, Manli Shu, Khalid Saifullah, Kezhi Kong, Kasun Fernando, Aniruddha Saha, Micah Goldblum, Tom Goldstein
0
0
As LLMs become commonplace, machine-generated text has the potential to flood the internet with spam, social media bots, and valueless content. Watermarking is a simple and effective strategy for mitigating such harms by enabling the detection and documentation of LLM-generated text. Yet a crucial question remains: How reliable is watermarking in realistic settings in the wild? There, watermarked text may be modified to suit a user's needs, or entirely rewritten to avoid detection. We study the robustness of watermarked text after it is re-written by humans, paraphrased by a non-watermarked LLM, or mixed into a longer hand-written document. We find that watermarks remain detectable even after human and machine paraphrasing. While these attacks dilute the strength of the watermark, paraphrases are statistically likely to leak n-grams or even longer fragments of the original text, resulting in high-confidence detections when enough tokens are observed. For example, after strong human paraphrasing the watermark is detectable after observing 800 tokens on average, when setting a 1e-5 false positive rate. We also consider a range of new detection schemes that are sensitive to short spans of watermarked text embedded inside a large document, and we compare the robustness of watermarking to other kinds of detectors.
5/3/2024
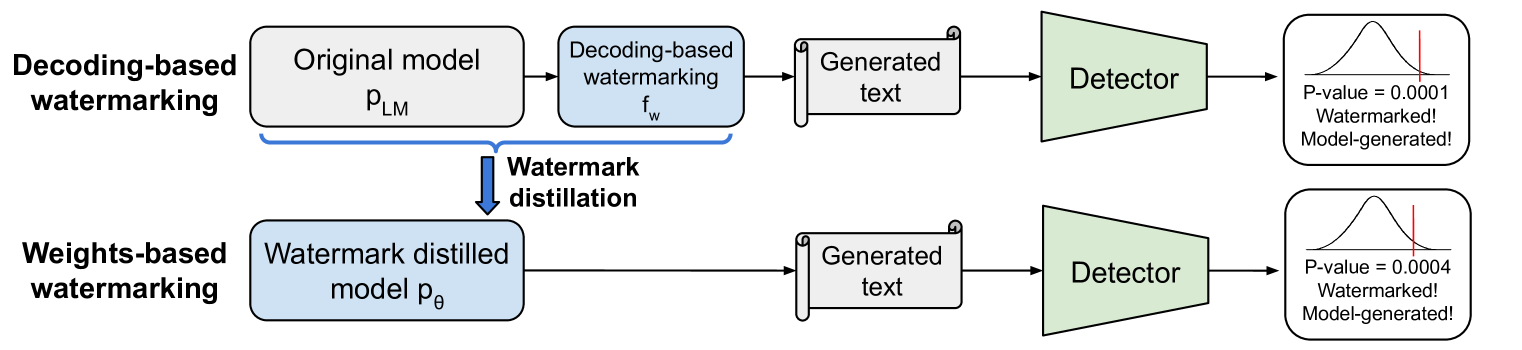
On the Learnability of Watermarks for Language Models
Chenchen Gu, Xiang Lisa Li, Percy Liang, Tatsunori Hashimoto
0
0
Watermarking of language model outputs enables statistical detection of model-generated text, which can mitigate harms and misuses of language models. Existing watermarking strategies operate by altering the decoder of an existing language model. In this paper, we ask whether language models can directly learn to generate watermarked text, which would have significant implications for the real-world deployment of watermarks. First, learned watermarks could be used to build open models that naturally generate watermarked text, enabling watermarking for open models, where users can control the decoding procedure. Second, if watermarking is used to determine the provenance of generated text, an adversary can hurt the reputation of a victim model by spoofing its watermark and generating damaging watermarked text. To investigate the learnability of watermarks, we propose watermark distillation, which trains a student model to behave like a teacher model that uses decoding-based watermarking. We test our approach on three decoding-based watermarking strategies and various hyperparameter settings, finding that models can learn to generate watermarked text with high detectability. We also find limitations to learnability, including the loss of watermarking capabilities under fine-tuning on normal text and high sample complexity when learning low-distortion watermarks.
5/3/2024
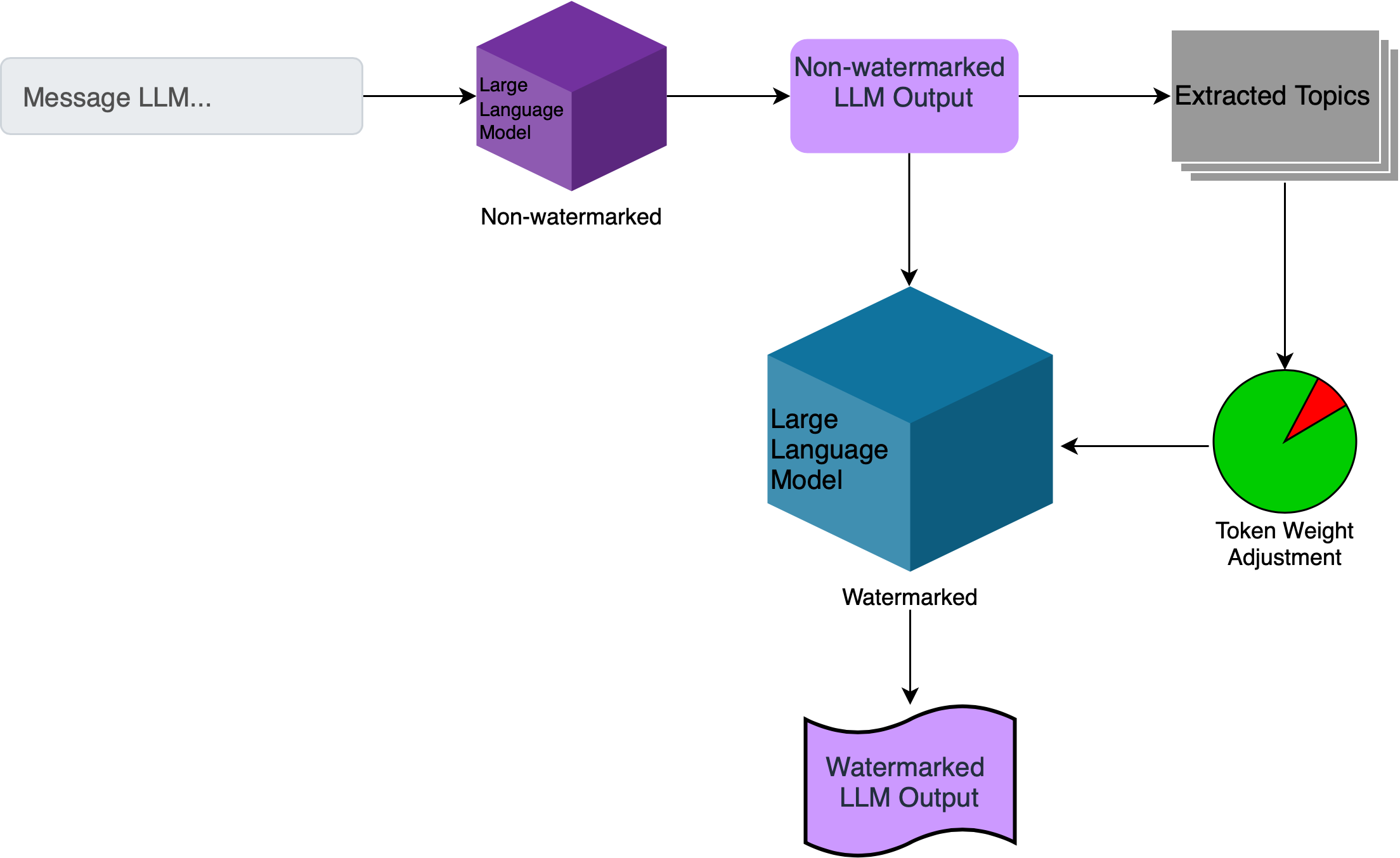
Topic-based Watermarks for LLM-Generated Text
Alexander Nemecek, Yuzhou Jiang, Erman Ayday
0
0
Recent advancements of large language models (LLMs) have resulted in indistinguishable text outputs comparable to human-generated text. Watermarking algorithms are potential tools that offer a way to differentiate between LLM- and human-generated text by embedding detectable signatures within LLM-generated output. However, current watermarking schemes lack robustness against known attacks against watermarking algorithms. In addition, they are impractical considering an LLM generates tens of thousands of text outputs per day and the watermarking algorithm needs to memorize each output it generates for the detection to work. In this work, focusing on the limitations of current watermarking schemes, we propose the concept of a topic-based watermarking algorithm for LLMs. The proposed algorithm determines how to generate tokens for the watermarked LLM output based on extracted topics of an input prompt or the output of a non-watermarked LLM. Inspired from previous work, we propose using a pair of lists (that are generated based on the specified extracted topic(s)) that specify certain tokens to be included or excluded while generating the watermarked output of the LLM. Using the proposed watermarking algorithm, we show the practicality of a watermark detection algorithm. Furthermore, we discuss a wide range of attacks that can emerge against watermarking algorithms for LLMs and the benefit of the proposed watermarking scheme for the feasibility of modeling a potential attacker considering its benefit vs. loss.
4/17/2024