Learning Causal Domain-Invariant Temporal Dynamics for Few-Shot Action Recognition

0

Sign in to get full access
Overview
- This paper introduces a novel method for few-shot action recognition, which aims to recognize new actions with limited training data.
- The key idea is to learn domain-invariant temporal dynamics that capture the underlying patterns of actions, allowing the model to generalize to new domains and tasks.
- The proposed approach leverages meta-learning techniques to rapidly adapt the model to new action categories with just a few examples.
Plain English Explanation
The ability to recognize and classify different actions, such as walking, jumping, or waving, is an important task in computer vision and has many real-world applications, like video understanding and human-robot interaction. However, traditional machine learning models often struggle with
To address this challenge, the researchers in this paper developed a new method that learns domain-invariant temporal dynamics - the underlying patterns in how actions unfold over time, regardless of the specific context or environment. By capturing these fundamental dynamics, the model can more effectively generalize to recognize new actions, even with limited training data.
The approach uses meta-learning techniques, which allow the model to quickly adapt to new action categories by leveraging its prior knowledge and experience. This means the model can be efficiently trained on a diverse set of action categories, and then rapidly learn to recognize new actions with just a few examples.
The key innovation is the ability to learn these generalizable temporal dynamics, rather than relying solely on visual appearance or low-level features that can vary significantly across different domains or camera viewpoints. This makes the model more robust and versatile for real-world action recognition tasks.
Technical Explanation
The paper proposes a novel framework for few-shot action recognition called Domain-Invariant Temporal Dynamics (DITD). At the core of the approach is a temporal encoder that learns to capture the underlying dynamics of actions, independent of the specific domain or dataset.
The temporal encoder takes in a sequence of video frames and outputs a compact representation that encodes the essential temporal patterns of the action, without being overly sensitive to superficial visual details. This domain-invariant representation is then used as input to a meta-learning module, which allows the model to rapidly adapt to recognize new action categories given only a few examples.
The meta-learning component is implemented using a prototypical network, which learns to compare the temporal representation of a new action instance to learned "prototypes" of the known action categories. By comparing to these prototypes, the model can classify the new action with high accuracy, even with very limited training data.
The researchers evaluate DITD on several few-shot action recognition benchmarks, including HMDB51, UCF101, and Something-Something-V2. The results demonstrate that DITD outperforms previous few-shot action recognition methods by a significant margin, showcasing the benefits of learning domain-invariant temporal dynamics.
Critical Analysis
The paper presents a compelling approach to the challenge of few-shot action recognition, with a well-designed architecture and compelling empirical results. However, there are a few potential limitations and areas for further research that could be explored:
-
The experiments in the paper focus on relatively short, trimmed video clips. It would be interesting to see how the DITD model performs on longer, more realistic video sequences with more complex temporal dynamics and potential occlusions or camera motion.
-
The paper does not provide much insight into the specific temporal patterns or features that the model learns to capture. A deeper analysis of the learned representations could yield additional insights and guide future improvements to the approach.
-
While the meta-learning component allows for rapid adaptation to new action categories, the paper does not explore the model's ability to continually learn and expand its repertoire of recognized actions over time. Incorporating continual learning capabilities could further enhance the model's practical usefulness.
-
The experiments are primarily focused on recognizing actions in isolation. Extending the approach to spatio-temporal action localization tasks could broaden the applicability of the method.
Overall, the DITD framework represents an important step forward in few-shot action recognition, with the potential to enable more robust and versatile action understanding systems. Further research building on this foundation could lead to even more powerful and adaptable models for real-world video analysis tasks.
Conclusion
This paper introduces a novel approach for few-shot action recognition called Domain-Invariant Temporal Dynamics (DITD). The key idea is to learn a temporal encoder that can capture the underlying dynamics of actions in a way that is robust to variations in the specific domain or visual context.
By leveraging meta-learning techniques, the DITD model can rapidly adapt to recognize new action categories with just a few examples, significantly outperforming previous few-shot action recognition methods. This advance has the potential to enable more flexible and adaptable video understanding systems, with applications in areas like human-robot interaction, video surveillance, and sports analysis.
While the paper presents promising results, there are also opportunities for further research to address limitations and expand the capabilities of the approach. Exploring the model's performance on longer, more complex videos, analyzing the learned temporal representations in greater depth, and incorporating continual learning and spatio-temporal localization capabilities could all lead to important next steps in this line of work.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning Causal Domain-Invariant Temporal Dynamics for Few-Shot Action Recognition
Yuke Li, Guangyi Chen, Ben Abramowitz, Stefano Anzellott, Donglai Wei
Few-shot action recognition aims at quickly adapting a pre-trained model to the novel data with a distribution shift using only a limited number of samples. Key challenges include how to identify and leverage the transferable knowledge learned by the pre-trained model. We therefore propose CDTD, or Causal Domain-Invariant Temporal Dynamics for knowledge transfer. To identify the temporally invariant and variant representations, we employ the causal representation learning methods for unsupervised pertaining, and then tune the classifier with supervisions in next stage. Specifically, we assume the domain information can be well estimated and the pre-trained image decoder and transition models can be well transferred. During adaptation, we fix the transferable temporal dynamics and update the image encoder and domain estimator. The efficacy of our approach is revealed by the superior accuracy of CDTD over leading alternatives across standard few-shot action recognition datasets.
Read more6/6/2024
0
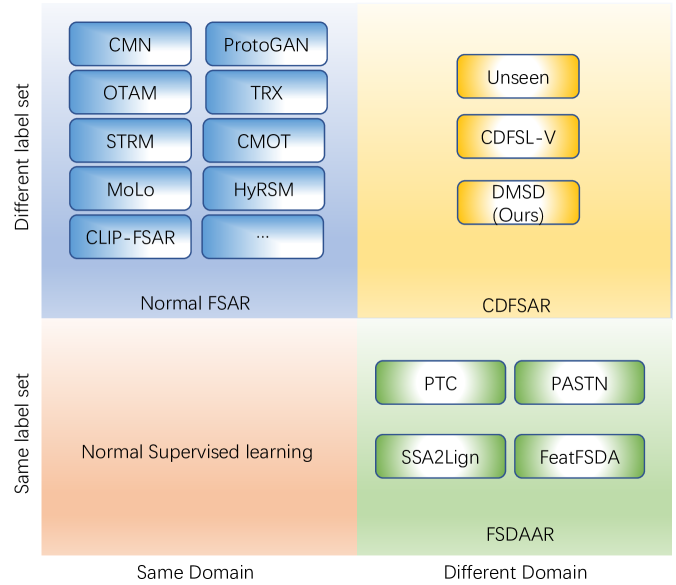
DMSD-CDFSAR: Distillation from Mixed-Source Domain for Cross-Domain Few-shot Action Recognition
Fei Guo, YiKang Wang, Han Qi, Li Zhu, Jing Sun
Few-shot action recognition is an emerging field in computer vision, primarily focused on meta-learning within the same domain. However, challenges arise in real-world scenario deployment, as gathering extensive labeled data within a specific domain is laborious and time-intensive. Thus, attention shifts towards cross-domain few-shot action recognition, requiring the model to generalize across domains with significant deviations. Therefore, we propose a novel approach, ``Distillation from Mixed-Source Domain, tailored to address this conundrum. Our method strategically integrates insights from both labeled data of the source domain and unlabeled data of the target domain during the training. The ResNet18 is used as the backbone to extract spatial features from the source and target domains. We design two branches for meta-training: the original-source and the mixed-source branches. In the first branch, a Domain Temporal Encoder is employed to capture temporal features for both the source and target domains. Additionally, a Domain Temporal Decoder is employed to reconstruct all extracted features. In the other branch, a Domain Mixed Encoder is used to handle labeled source domain data and unlabeled target domain data, generating mixed-source domain features. We incorporate a pre-training stage before meta-training, featuring a network architecture similar to that of the first branch. Lastly, we introduce a dual distillation mechanism to refine the classification probabilities of source domain features, aligning them with those of mixed-source domain features. This iterative process enriches the insights of the original-source branch with knowledge from the mixed-source branch, thereby enhancing the model's generalization capabilities. Our code is available at URL: url{https://xxxx/xxxx/xxxx.git}
Read more7/9/2024

0
Multimodal Cross-Domain Few-Shot Learning for Egocentric Action Recognition
Masashi Hatano, Ryo Hachiuma, Ryo Fujii, Hideo Saito
We address a novel cross-domain few-shot learning task (CD-FSL) with multimodal input and unlabeled target data for egocentric action recognition. This paper simultaneously tackles two critical challenges associated with egocentric action recognition in CD-FSL settings: (1) the extreme domain gap in egocentric videos (e.g., daily life vs. industrial domain) and (2) the computational cost for real-world applications. We propose MM-CDFSL, a domain-adaptive and computationally efficient approach designed to enhance adaptability to the target domain and improve inference cost. To address the first challenge, we propose the incorporation of multimodal distillation into the student RGB model using teacher models. Each teacher model is trained independently on source and target data for its respective modality. Leveraging only unlabeled target data during multimodal distillation enhances the student model's adaptability to the target domain. We further introduce ensemble masked inference, a technique that reduces the number of input tokens through masking. In this approach, ensemble prediction mitigates the performance degradation caused by masking, effectively addressing the second issue. Our approach outperformed the state-of-the-art CD-FSL approaches with a substantial margin on multiple egocentric datasets, improving by an average of 6.12/6.10 points for 1-shot/5-shot settings while achieving $2.2$ times faster inference speed. Project page: https://masashi-hatano.github.io/MM-CDFSL/
Read more7/17/2024
0
D$^2$ST-Adapter: Disentangled-and-Deformable Spatio-Temporal Adapter for Few-shot Action Recognition
Wenjie Pei, Qizhong Tan, Guangming Lu, Jiandong Tian
Adapting large pre-trained image models to few-shot action recognition has proven to be an effective and efficient strategy for learning robust feature extractors, which is essential for few-shot learning. Typical fine-tuning based adaptation paradigm is prone to overfitting in the few-shot learning scenarios and offers little modeling flexibility for learning temporal features in video data. In this work we present the Disentangled-and-Deformable Spatio-Temporal Adapter (D$^2$ST-Adapter), which is a novel adapter tuning framework well-suited for few-shot action recognition due to lightweight design and low parameter-learning overhead. It is designed in a dual-pathway architecture to encode spatial and temporal features in a disentangled manner. In particular, we devise the anisotropic Deformable Spatio-Temporal Attention module as the core component of D$^2$ST-Adapter, which can be tailored with anisotropic sampling densities along spatial and temporal domains to learn spatial and temporal features specifically in corresponding pathways, allowing our D$^2$ST-Adapter to encode features in a global view in 3D spatio-temporal space while maintaining a lightweight design. Extensive experiments with instantiations of our method on both pre-trained ResNet and ViT demonstrate the superiority of our method over state-of-the-art methods for few-shot action recognition. Our method is particularly well-suited to challenging scenarios where temporal dynamics are critical for action recognition.
Read more4/23/2024