Learning from SAM: Harnessing a Foundation Model for Sim2Real Adaptation by Regularization
2309.15562
0
0
📈
Abstract
Domain adaptation is especially important for robotics applications, where target domain training data is usually scarce and annotations are costly to obtain. We present a method for self-supervised domain adaptation for the scenario where annotated source domain data (e.g. from synthetic generation) is available, but the target domain data is completely unannotated. Our method targets the semantic segmentation task and leverages a segmentation foundation model (Segment Anything Model) to obtain segment information on unannotated data. We take inspiration from recent advances in unsupervised local feature learning and propose an invariance-variance loss over the detected segments for regularizing feature representations in the target domain. Crucially, this loss structure and network architecture can handle overlapping segments and oversegmentation as produced by Segment Anything. We demonstrate the advantage of our method on the challenging YCB-Video and HomebrewedDB datasets and show that it outperforms prior work and, on YCB-Video, even a network trained with real annotations. Additionally, we provide insight through model ablations and show applicability to a custom robotic application.
Create account to get full access
Overview
- This paper presents a method for self-supervised domain adaptation in semantic segmentation, targeting robotics applications where annotated target data is scarce.
- The key idea is to leverage a segmentation foundation model (Segment Anything Model) to obtain segment information on unannotated target data, and then use an invariance-variance loss to regularize feature representations.
- The method is demonstrated on challenging robotics datasets and outperforms prior work, even matching the performance of a network trained on real annotations.
Plain English Explanation
When it comes to robotics applications, getting the right training data can be a real challenge. Often, the target domain data (the specific environment the robot will be operating in) has very few annotations, meaning the ground truth information needed to train a machine learning model is scarce and expensive to obtain.
One way to address this is through domain adaptation, which aims to adapt a model trained on a source domain (like synthetic data) to perform well on the target domain. In this paper, the researchers present a novel self-supervised domain adaptation method for the task of semantic segmentation, which involves dividing an image into meaningful regions or "segments."
The key insight is to use a powerful segmentation foundation model called the Segment Anything Model to automatically identify segments in the unannotated target domain data. The researchers then use an "invariance-variance" loss function to train the model to learn features that are consistent across these automatically detected segments, while also allowing the model to differentiate between distinct segments.
This approach is particularly clever because it can handle the messy reality of real-world data, where segments may overlap or be over-segmented (broken into too many pieces). By designing the loss function and network architecture to be robust to these issues, the researchers are able to effectively adapt the model to the target domain, even without any labeled data.
When tested on challenging robotics datasets like YCB-Video and HomebrewedDB, the researchers' method outperformed previous domain adaptation approaches and, on YCB-Video, even matched the performance of a model trained on real annotations. This is a significant achievement, as it demonstrates the power of this self-supervised domain adaptation technique to bridge the gap between source and target domains without requiring costly manual labeling.
Technical Explanation
The core of the researchers' approach is to leverage a pre-trained Segment Anything Model to obtain segment-level information on the unannotated target domain data. This segment information is then used to define an "invariance-variance" loss function, which aims to regularize the feature representations learned by the model.
The invariance component of the loss encourages the model to learn features that are consistent across segments within the same image, while the variance component encourages the model to differentiate between distinct segments. This loss structure is designed to be robust to the challenges of real-world data, such as overlapping segments and oversegmentation, as produced by the Segment Anything Model.
The researchers evaluate their method on the YCB-Video and HomebrewedDB datasets, which are designed to simulate challenging robotics scenarios. They demonstrate that their self-supervised domain adaptation approach outperforms previous state-of-the-art methods, and on YCB-Video, even matches the performance of a model trained on real-world annotations.
Through model ablations, the researchers provide insights into the key components of their method, such as the importance of the invariance-variance loss and the robustness to segmentation quality. They also showcase the applicability of their approach to a custom robotic application, further demonstrating its practical relevance.
Critical Analysis
One potential limitation of the researchers' approach is its reliance on the Segment Anything Model, which may not always produce perfect segmentation results. While the invariance-variance loss is designed to be robust to segmentation quality, it's possible that in some cases, the automatically generated segment information could introduce noise or bias into the training process.
Additionally, the researchers only evaluate their method on a few specific datasets, and it's unclear how well it would generalize to a wider range of robotics scenarios or other domain adaptation tasks. Further testing on a broader range of applications would be helpful to better understand the method's strengths and limitations.
That said, the researchers' key insight – leveraging a powerful segmentation foundation model to enable self-supervised domain adaptation – is a clever and potentially impactful approach. By reducing the need for costly manual annotations, this method could significantly improve the accessibility and practicality of deploying machine learning models in real-world robotics applications.
Overall, this paper represents an interesting and promising contribution to the field of domain adaptation, with potential implications for enhancing weakly supervised semantic segmentation and other multi-modal learning scenarios where annotated data is scarce.
Conclusion
This paper presents a novel self-supervised domain adaptation method for semantic segmentation in robotics applications, where annotated target domain data is typically scarce. By leveraging a powerful segmentation foundation model to obtain segment information on unannotated target data, and then using an invariance-variance loss to regularize feature representations, the researchers demonstrate significant performance gains over prior domain adaptation approaches.
The key strength of this method is its ability to effectively bridge the gap between source and target domains without requiring costly manual annotations, which is a common challenge in real-world robotics deployments. While the approach has some limitations and requires further testing, it represents an important step forward in making machine learning more accessible and practical for robotics applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Improving the Generalization of Segmentation Foundation Model under Distribution Shift via Weakly Supervised Adaptation
Haojie Zhang, Yongyi Su, Xun Xu, Kui Jia
0
0
The success of large language models has inspired the computer vision community to explore image segmentation foundation model that is able to zero/few-shot generalize through prompt engineering. Segment-Anything(SAM), among others, is the state-of-the-art image segmentation foundation model demonstrating strong zero/few-shot generalization. Despite the success, recent studies reveal the weakness of SAM under strong distribution shift. In particular, SAM performs awkwardly on corrupted natural images, camouflaged images, medical images, etc. Motivated by the observations, we aim to develop a self-training based strategy to adapt SAM to target distribution. Given the unique challenges of large source dataset, high computation cost and incorrect pseudo label, we propose a weakly supervised self-training architecture with anchor regularization and low-rank finetuning to improve the robustness and computation efficiency of adaptation. We validate the effectiveness on 5 types of downstream segmentation tasks including natural clean/corrupted images, medical images, camouflaged images and robotic images. Our proposed method is task-agnostic in nature and outperforms pre-trained SAM and state-of-the-art domain adaptation methods on almost all downstream tasks with the same testing prompt inputs.
4/11/2024
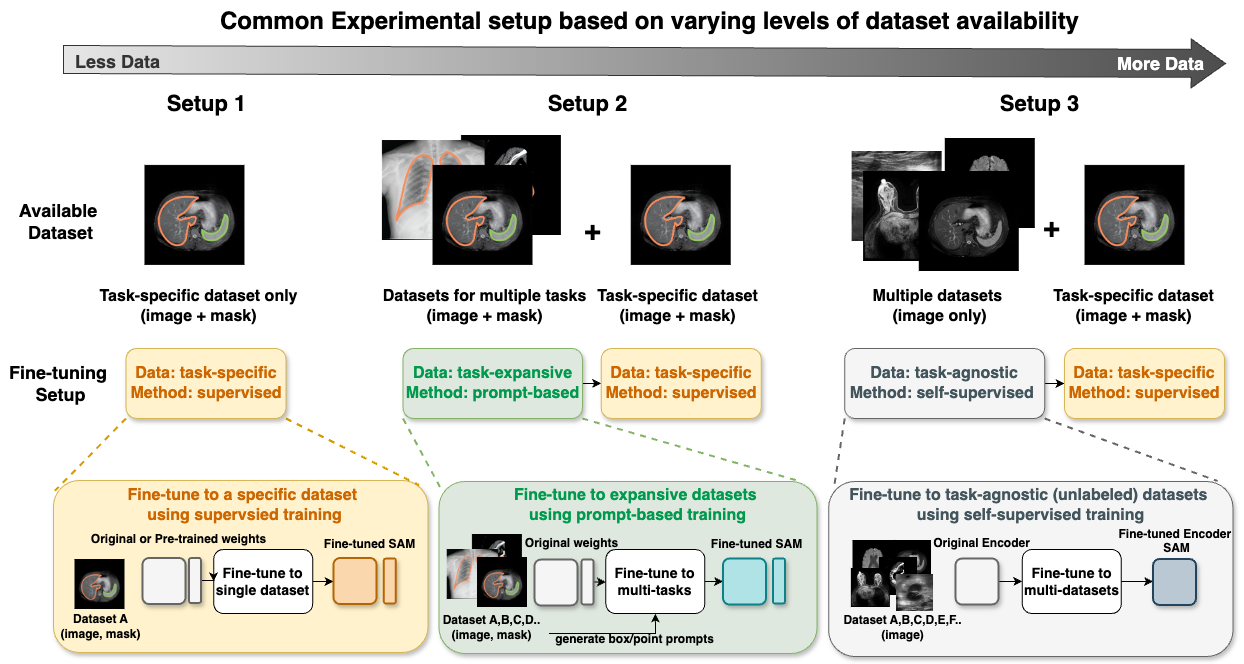
How to build the best medical image segmentation algorithm using foundation models: a comprehensive empirical study with Segment Anything Model
Hanxue Gu, Haoyu Dong, Jichen Yang, Maciej A. Mazurowski
0
0
Automated segmentation is a fundamental medical image analysis task, which enjoys significant advances due to the advent of deep learning. While foundation models have been useful in natural language processing and some vision tasks for some time, the foundation model developed with image segmentation in mind - Segment Anything Model (SAM) - has been developed only recently and has shown similar promise. However, there are still no systematic analyses or best-practice guidelines for optimal fine-tuning of SAM for medical image segmentation. This work summarizes existing fine-tuning strategies with various backbone architectures, model components, and fine-tuning algorithms across 18 combinations, and evaluates them on 17 datasets covering all common radiology modalities. Our study reveals that (1) fine-tuning SAM leads to slightly better performance than previous segmentation methods, (2) fine-tuning strategies that use parameter-efficient learning in both the encoder and decoder are superior to other strategies, (3) network architecture has a small impact on final performance, (4) further training SAM with self-supervised learning can improve final model performance. We also demonstrate the ineffectiveness of some methods popular in the literature and further expand our experiments into few-shot and prompt-based settings. Lastly, we released our code and MRI-specific fine-tuned weights, which consistently obtained superior performance over the original SAM, at https://github.com/mazurowski-lab/finetune-SAM.
5/14/2024
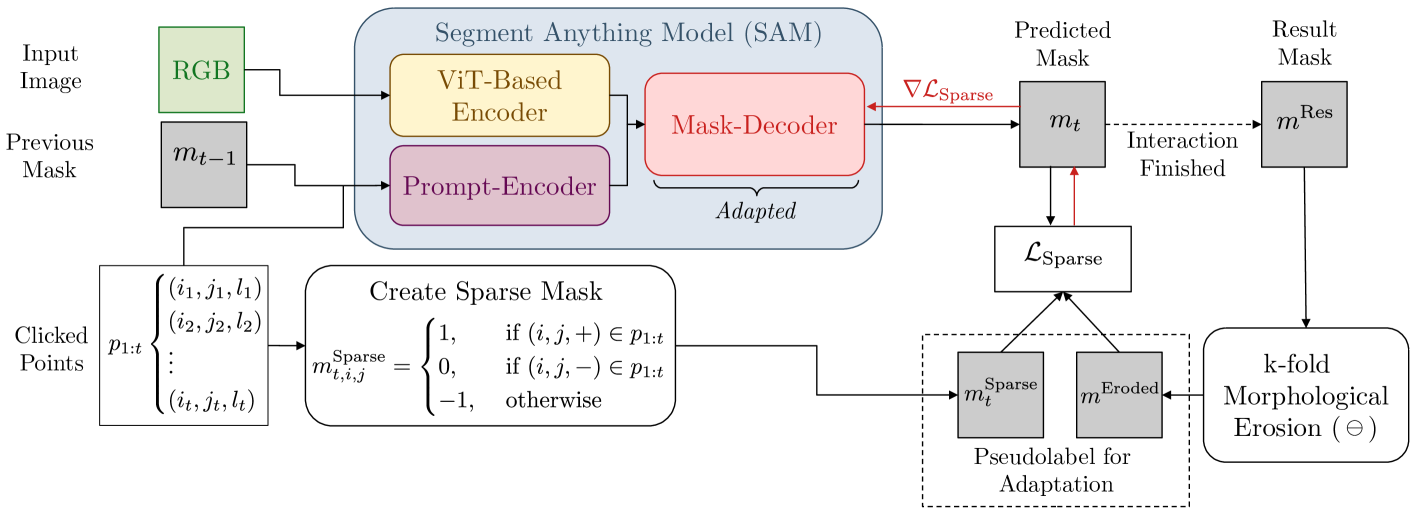
Adapting the Segment Anything Model During Usage in Novel Situations
Robin Schon, Julian Lorenz, Katja Ludwig, Rainer Lienhart
0
0
The interactive segmentation task consists in the creation of object segmentation masks based on user interactions. The most common way to guide a model towards producing a correct segmentation consists in clicks on the object and background. The recently published Segment Anything Model (SAM) supports a generalized version of the interactive segmentation problem and has been trained on an object segmentation dataset which contains 1.1B masks. Though being trained extensively and with the explicit purpose of serving as a foundation model, we show significant limitations of SAM when being applied for interactive segmentation on novel domains or object types. On the used datasets, SAM displays a failure rate $text{FR}_{30}@90$ of up to $72.6 %$. Since we still want such foundation models to be immediately applicable, we present a framework that can adapt SAM during immediate usage. For this we will leverage the user interactions and masks, which are constructed during the interactive segmentation process. We use this information to generate pseudo-labels, which we use to compute a loss function and optimize a part of the SAM model. The presented method causes a relative reduction of up to $48.1 %$ in the $text{FR}_{20}@85$ and $46.6 %$ in the $text{FR}_{30}@90$ metrics.
4/15/2024

Matching Anything by Segmenting Anything
Siyuan Li, Lei Ke, Martin Danelljan, Luigi Piccinelli, Mattia Segu, Luc Van Gool, Fisher Yu
0
0
The robust association of the same objects across video frames in complex scenes is crucial for many applications, especially Multiple Object Tracking (MOT). Current methods predominantly rely on labeled domain-specific video datasets, which limits the cross-domain generalization of learned similarity embeddings. We propose MASA, a novel method for robust instance association learning, capable of matching any objects within videos across diverse domains without tracking labels. Leveraging the rich object segmentation from the Segment Anything Model (SAM), MASA learns instance-level correspondence through exhaustive data transformations. We treat the SAM outputs as dense object region proposals and learn to match those regions from a vast image collection. We further design a universal MASA adapter which can work in tandem with foundational segmentation or detection models and enable them to track any detected objects. Those combinations present strong zero-shot tracking ability in complex domains. Extensive tests on multiple challenging MOT and MOTS benchmarks indicate that the proposed method, using only unlabeled static images, achieves even better performance than state-of-the-art methods trained with fully annotated in-domain video sequences, in zero-shot association. Project Page: https://matchinganything.github.io/
6/7/2024