Matching Anything by Segmenting Anything

0

Sign in to get full access
Overview
- This paper introduces a new approach for "Matching Anything by Segmenting Anything" (MASA), which extends the capabilities of the Segment Anything Model (SAM) to enable matching between any visual elements, not just those that can be explicitly segmented.
- The key idea is to use SAM as a foundation and build upon it to create a more general matching framework that can be applied to a wider range of visual recognition tasks.
- The proposed MASA model achieves state-of-the-art performance on several matching benchmarks, demonstrating its ability to handle diverse visual elements and tasks.
Plain English Explanation
The paper presents a new computer vision technique called "Matching Anything by Segmenting Anything" (MASA). This builds upon an existing model called the Segment Anything Model (SAM), which can identify and segment specific objects in an image.
The researchers found that SAM's capabilities could be expanded beyond just segmentation. They developed a way to use SAM as a foundation to create a more general matching framework. This allows the model to compare and match any visual elements in an image, not just the ones that can be explicitly segmented.
For example, with the MASA model, you could not only identify and outline a person in an image, but also match that person to another person in a different image, even if the two people look quite different. The model is able to find the underlying similarities between visual elements, rather than just being limited to segmentation.
The researchers show that MASA achieves excellent results on various benchmarks for visual matching tasks. This demonstrates the power and flexibility of their approach, which can be applied to a wide range of real-world computer vision problems.
Technical Explanation
The paper introduces the "Matching Anything by Segmenting Anything" (MASA) framework, which builds upon the capabilities of the Segment Anything Model (SAM) to enable matching between any visual elements, not just those that can be explicitly segmented.
The key idea is to leverage SAM as a versatile foundation and extend it to create a more general matching system. This is achieved by training MASA to learn a rich feature representation that can capture the underlying similarities between diverse visual elements, rather than just focusing on segmentation.
The MASA architecture consists of several novel components:
- An enhanced encoder that learns richer visual features by combining SAM's feature backbone with additional task-specific layers.
- A matching module that takes the encoded features from two input images and outputs a similarity score indicating how well the visual elements match.
- A multi-task training scheme that jointly optimizes MASA for both segmentation and matching tasks, allowing the model to learn complementary capabilities.
The researchers evaluate MASA on a variety of matching benchmarks, including zero-shot segmentation, adapting to novel domains, and matching everything by segmenting anything. The results demonstrate that MASA achieves state-of-the-art performance, outperforming previous approaches and showcasing its ability to handle diverse visual recognition tasks.
Critical Analysis
The paper presents a well-designed and impressive extension of the Segment Anything Model (SAM) to enable more general visual matching capabilities. The MASA framework addresses an important limitation of SAM, which was primarily focused on segmentation tasks.
One potential caveat is that the training process for MASA is more complex, as it involves jointly optimizing for both segmentation and matching objectives. This could make the model more challenging to train, especially for practitioners without extensive deep learning expertise. The authors do not provide detailed insights into the training stability and convergence of their approach.
Additionally, while the paper demonstrates strong performance on various benchmarks, it would be valuable to see how MASA performs on real-world applications, such as image retrieval or cross-modal alignment tasks. Evaluating the model's robustness and generalization to more diverse and challenging visual scenarios could further validate its practical utility.
Exploring the learning from SAM and sim2real transfer aspects of MASA could also yield interesting insights and broaden its applicability.
Overall, the MASA framework is a significant advancement in visual recognition capabilities, and the authors have made a valuable contribution to the field of computer vision. Further research and real-world deployments could help unlock the full potential of this approach.
Conclusion
The "Matching Anything by Segmenting Anything" (MASA) framework presented in this paper represents an important step forward in visual recognition capabilities. By extending the Segment Anything Model (SAM) to enable more general matching between diverse visual elements, the researchers have created a versatile tool that can be applied to a wide range of computer vision tasks.
The key innovation of MASA is its ability to learn rich feature representations that capture the underlying similarities between visual elements, rather than just focusing on explicit segmentation. This allows the model to perform matching and alignment across a variety of visual inputs, going beyond the limitations of traditional segmentation-based approaches.
The strong performance of MASA on multiple benchmarks suggests that this framework has the potential to drive progress in various real-world applications, such as image retrieval, cross-modal alignment, and even multimodal reasoning. As the field of computer vision continues to advance, techniques like MASA that can adapt to diverse visual tasks will be increasingly valuable.
Further research and real-world deployments of MASA could yield exciting new insights and applications, helping to unlock the full potential of this innovative approach to visual recognition.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Matching Anything by Segmenting Anything
Siyuan Li, Lei Ke, Martin Danelljan, Luigi Piccinelli, Mattia Segu, Luc Van Gool, Fisher Yu
The robust association of the same objects across video frames in complex scenes is crucial for many applications, especially Multiple Object Tracking (MOT). Current methods predominantly rely on labeled domain-specific video datasets, which limits the cross-domain generalization of learned similarity embeddings. We propose MASA, a novel method for robust instance association learning, capable of matching any objects within videos across diverse domains without tracking labels. Leveraging the rich object segmentation from the Segment Anything Model (SAM), MASA learns instance-level correspondence through exhaustive data transformations. We treat the SAM outputs as dense object region proposals and learn to match those regions from a vast image collection. We further design a universal MASA adapter which can work in tandem with foundational segmentation or detection models and enable them to track any detected objects. Those combinations present strong zero-shot tracking ability in complex domains. Extensive tests on multiple challenging MOT and MOTS benchmarks indicate that the proposed method, using only unlabeled static images, achieves even better performance than state-of-the-art methods trained with fully annotated in-domain video sequences, in zero-shot association. Project Page: https://matchinganything.github.io/
Read more6/7/2024

0
Segment-Anything Models Achieve Zero-shot Robustness in Autonomous Driving
Jun Yan, Pengyu Wang, Danni Wang, Weiquan Huang, Daniel Watzenig, Huilin Yin
Semantic segmentation is a significant perception task in autonomous driving. It suffers from the risks of adversarial examples. In the past few years, deep learning has gradually transitioned from convolutional neural network (CNN) models with a relatively small number of parameters to foundation models with a huge number of parameters. The segment-anything model (SAM) is a generalized image segmentation framework that is capable of handling various types of images and is able to recognize and segment arbitrary objects in an image without the need to train on a specific object. It is a unified model that can handle diverse downstream tasks, including semantic segmentation, object detection, and tracking. In the task of semantic segmentation for autonomous driving, it is significant to study the zero-shot adversarial robustness of SAM. Therefore, we deliver a systematic empirical study on the robustness of SAM without additional training. Based on the experimental results, the zero-shot adversarial robustness of the SAM under the black-box corruptions and white-box adversarial attacks is acceptable, even without the need for additional training. The finding of this study is insightful in that the gigantic model parameters and huge amounts of training data lead to the phenomenon of emergence, which builds a guarantee of adversarial robustness. SAM is a vision foundation model that can be regarded as an early prototype of an artificial general intelligence (AGI) pipeline. In such a pipeline, a unified model can handle diverse tasks. Therefore, this research not only inspects the impact of vision foundation models on safe autonomous driving but also provides a perspective on developing trustworthy AGI. The code is available at: https://github.com/momo1986/robust_sam_iv.
Read more8/20/2024
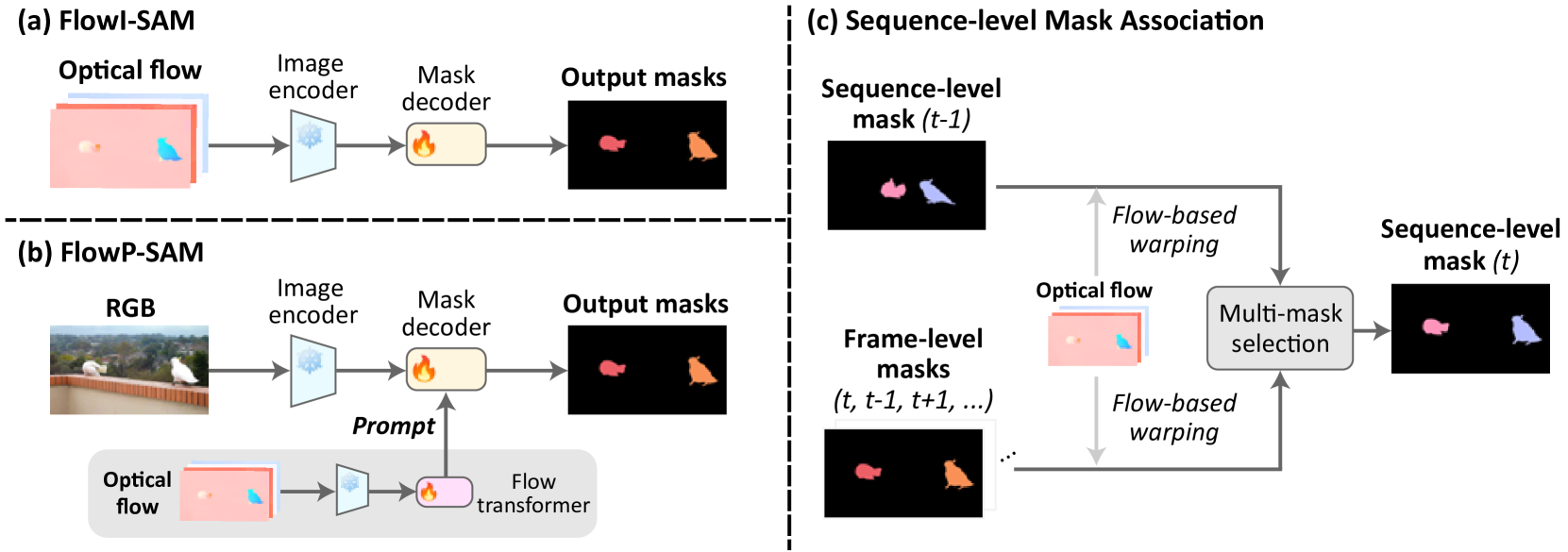
0
Moving Object Segmentation: All You Need Is SAM (and Flow)
Junyu Xie, Charig Yang, Weidi Xie, Andrew Zisserman
The objective of this paper is motion segmentation -- discovering and segmenting the moving objects in a video. This is a much studied area with numerous careful,and sometimes complex, approaches and training schemes including: self-supervised learning, learning from synthetic datasets, object-centric representations, amodal representations, and many more. Our interest in this paper is to determine if the Segment Anything model (SAM) can contribute to this task. We investigate two models for combining SAM with optical flow that harness the segmentation power of SAM with the ability of flow to discover and group moving objects. In the first model, we adapt SAM to take optical flow, rather than RGB, as an input. In the second, SAM takes RGB as an input, and flow is used as a segmentation prompt. These surprisingly simple methods, without any further modifications, outperform all previous approaches by a considerable margin in both single and multi-object benchmarks. We also extend these frame-level segmentations to sequence-level segmentations that maintain object identity. Again, this simple model outperforms previous methods on multiple video object segmentation benchmarks.
Read more4/19/2024
🗣️
0
DMESA: Densely Matching Everything by Segmenting Anything
Yesheng Zhang, Xu Zhao
We propose MESA and DMESA as novel feature matching methods, which utilize Segment Anything Model (SAM) to effectively mitigate matching redundancy. The key insight of our methods is to establish implicit-semantic area matching prior to point matching, based on advanced image understanding of SAM. Then, informative area matches with consistent internal semantic are able to undergo dense feature comparison, facilitating precise inside-area point matching. Specifically, MESA adopts a sparse matching framework and first obtains candidate areas from SAM results through a novel Area Graph (AG). Then, area matching among the candidates is formulated as graph energy minimization and solved by graphical models derived from AG. To address the efficiency issue of MESA, we further propose DMESA as its dense counterpart, applying a dense matching framework. After candidate areas are identified by AG, DMESA establishes area matches through generating dense matching distributions. The distributions are produced from off-the-shelf patch matching utilizing the Gaussian Mixture Model and refined via the Expectation Maximization. With less repetitive computation, DMESA showcases a speed improvement of nearly five times compared to MESA, while maintaining competitive accuracy. Our methods are extensively evaluated on five datasets encompassing indoor and outdoor scenes. The results illustrate consistent performance improvements from our methods for five distinct point matching baselines across all datasets. Furthermore, our methods exhibit promise generalization and improved robustness against image resolution variations. The code is publicly available at https://github.com/Easonyesheng/A2PM-MESA.
Read more8/2/2024