Learning Mixtures of Gaussians Using Diffusion Models
2404.18869
0
0
🏅
Abstract
We give a new algorithm for learning mixtures of $k$ Gaussians (with identity covariance in $mathbb{R}^n$) to TV error $varepsilon$, with quasi-polynomial ($O(n^{text{poly log}left(frac{n+k}{varepsilon}right)})$) time and sample complexity, under a minimum weight assumption. Unlike previous approaches, most of which are algebraic in nature, our approach is analytic and relies on the framework of diffusion models. Diffusion models are a modern paradigm for generative modeling, which typically rely on learning the score function (gradient log-pdf) along a process transforming a pure noise distribution, in our case a Gaussian, to the data distribution. Despite their dazzling performance in tasks such as image generation, there are few end-to-end theoretical guarantees that they can efficiently learn nontrivial families of distributions; we give some of the first such guarantees. We proceed by deriving higher-order Gaussian noise sensitivity bounds for the score functions for a Gaussian mixture to show that that they can be inductively learned using piecewise polynomial regression (up to poly-logarithmic degree), and combine this with known convergence results for diffusion models. Our results extend to continuous mixtures of Gaussians where the mixing distribution is supported on a union of $k$ balls of constant radius. In particular, this applies to the case of Gaussian convolutions of distributions on low-dimensional manifolds, or more generally sets with small covering number.
Create account to get full access
Overview
- The paper presents a new algorithm for learning mixtures of k Gaussians with identity covariance in ℝⁿ to a TV error ε, with a quasi-polynomial (link) time and sample complexity, under a minimum weight assumption.
- Unlike previous algebraic approaches, this method is analytic and uses the framework of diffusion models, a modern paradigm for generative modeling.
- The authors derive higher-order Gaussian noise sensitivity bounds for the score functions of Gaussian mixtures, allowing them to be inductively learned using piecewise polynomial regression.
- The results also extend to continuous mixtures of Gaussians where the mixing distribution is supported on a union of k balls of constant radius, such as Gaussian convolutions of distributions on low-dimensional manifolds.
Plain English Explanation
The paper presents a new way to learn a type of statistical model called a Gaussian mixture. A Gaussian mixture is a model that represents data as a combination of multiple Gaussian (bell-shaped) distributions. This type of model is useful for capturing complex data distributions, such as the heights of people in a population, which might have multiple peaks corresponding to different gender or age groups.
The authors' approach is different from previous methods, which tended to be more algebraic in nature. Instead, they use a framework called diffusion models, which learn the "score function" (a way of measuring how the data distribution changes as you move through the space). By deriving some mathematical bounds on how the score function behaves for Gaussian mixtures, the authors show that these models can be learned efficiently, with a relatively small number of samples and computations.
Importantly, the authors' results apply not just to discrete Gaussian mixtures, but also to continuous mixtures where the mixing distribution is supported on a union of balls (e.g., data that lies on or near low-dimensional manifolds). This makes the approach quite versatile and applicable to a wide range of real-world data.
Technical Explanation
The key technical contribution of the paper is deriving higher-order Gaussian noise sensitivity bounds for the score functions of Gaussian mixture models. Specifically, the authors show that the score functions of Gaussian mixtures can be approximated by piecewise polynomial functions of relatively low degree (up to polylogarithmic in the dimension and other parameters).
This allows the score functions to be learned efficiently using regression techniques, which the authors then combine with known convergence results for diffusion-based generative models. The result is a quasi-polynomial time and sample complexity algorithm for learning Gaussian mixtures to a specified TV (total variation) error tolerance ε, under a minimum weight assumption on the mixture components.
The authors also extend their results to the case of continuous Gaussian mixtures, where the mixing distribution is supported on a union of k balls of constant radius. This includes important special cases like Gaussian convolutions of distributions on low-dimensional manifolds or more generally, sets with small covering number.
Critical Analysis
The authors provide strong theoretical guarantees for their approach, showing that it can efficiently learn a broad class of Gaussian mixture models. However, as with any theoretical work, there are some caveats and limitations to consider:
- The minimum weight assumption on the mixture components may be restrictive in practice, as it requires a certain level of "balance" in the mixture weights.
- The quasi-polynomial time and sample complexity, while an improvement over previous methods, may still be prohibitive for very high-dimensional or large-scale problems.
- The extension to continuous Gaussian mixtures is interesting, but the authors do not provide experimental results for this case, so the practical implications are less clear.
Additionally, while the authors highlight the advantages of their analytic, diffusion-based approach compared to more algebraic methods, it would be valuable to see a more direct empirical comparison to state-of-the-art Gaussian mixture learning algorithms.
Overall, the paper makes an important theoretical contribution, but further research may be needed to fully understand the practical implications and limitations of the proposed approach.
Conclusion
This paper presents a new algorithm for efficiently learning Gaussian mixture models, a widely used class of statistical models. The key innovation is the use of diffusion models and associated mathematical techniques to derive bounds on the complexity of learning the score functions of Gaussian mixtures.
The results extend beyond discrete Gaussian mixtures to continuous mixtures supported on low-dimensional structures, which has important applications in areas like manifold learning and generative modeling. While the theoretical guarantees are impressive, further work may be needed to fully understand the practical implications and limitations of the approach.
Overall, this research represents an intriguing step forward in our understanding of how to efficiently learn rich probabilistic models from data, with potential impacts across machine learning and related fields.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Learning general Gaussian mixtures with efficient score matching
Sitan Chen, Vasilis Kontonis, Kulin Shah
0
0
We study the problem of learning mixtures of $k$ Gaussians in $d$ dimensions. We make no separation assumptions on the underlying mixture components: we only require that the covariance matrices have bounded condition number and that the means and covariances lie in a ball of bounded radius. We give an algorithm that draws $d^{mathrm{poly}(k/varepsilon)}$ samples from the target mixture, runs in sample-polynomial time, and constructs a sampler whose output distribution is $varepsilon$-far from the unknown mixture in total variation. Prior works for this problem either (i) required exponential runtime in the dimension $d$, (ii) placed strong assumptions on the instance (e.g., spherical covariances or clusterability), or (iii) had doubly exponential dependence on the number of components $k$. Our approach departs from commonly used techniques for this problem like the method of moments. Instead, we leverage a recently developed reduction, based on diffusion models, from distribution learning to a supervised learning task called score matching. We give an algorithm for the latter by proving a structural result showing that the score function of a Gaussian mixture can be approximated by a piecewise-polynomial function, and there is an efficient algorithm for finding it. To our knowledge, this is the first example of diffusion models achieving a state-of-the-art theoretical guarantee for an unsupervised learning task.
4/30/2024
📉
Mixtures of Gaussians are Privately Learnable with a Polynomial Number of Samples
Mohammad Afzali, Hassan Ashtiani, Christopher Liaw
0
0
We study the problem of estimating mixtures of Gaussians under the constraint of differential privacy (DP). Our main result is that $text{poly}(k,d,1/alpha,1/varepsilon,log(1/delta))$ samples are sufficient to estimate a mixture of $k$ Gaussians in $mathbb{R}^d$ up to total variation distance $alpha$ while satisfying $(varepsilon, delta)$-DP. This is the first finite sample complexity upper bound for the problem that does not make any structural assumptions on the GMMs. To solve the problem, we devise a new framework which may be useful for other tasks. On a high level, we show that if a class of distributions (such as Gaussians) is (1) list decodable and (2) admits a locally small'' cover (Bun et al., 2021) with respect to total variation distance, then the class of its mixtures is privately learnable. The proof circumvents a known barrier indicating that, unlike Gaussians, GMMs do not admit a locally small cover (Aden-Ali et al., 2021b).
4/24/2024
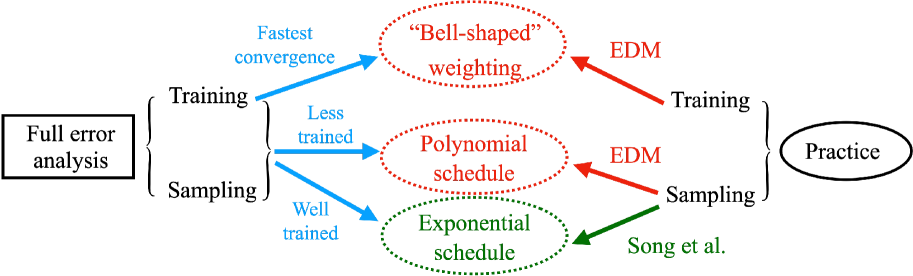
Evaluating the design space of diffusion-based generative models
Yuqing Wang, Ye He, Molei Tao
0
0
Most existing theoretical investigations of the accuracy of diffusion models, albeit significant, assume the score function has been approximated to a certain accuracy, and then use this a priori bound to control the error of generation. This article instead provides a first quantitative understanding of the whole generation process, i.e., both training and sampling. More precisely, it conducts a non-asymptotic convergence analysis of denoising score matching under gradient descent. In addition, a refined sampling error analysis for variance exploding models is also provided. The combination of these two results yields a full error analysis, which elucidates (again, but this time theoretically) how to design the training and sampling processes for effective generation. For instance, our theory implies a preference toward noise distribution and loss weighting that qualitatively agree with the ones used in [Karras et al. 2022]. It also provides some perspectives on why the time and variance schedule used in [Karras et al. 2022] could be better tuned than the pioneering version in [Song et al. 2020].
6/19/2024

Unraveling the Smoothness Properties of Diffusion Models: A Gaussian Mixture Perspective
Jiuxiang Gu, Yingyu Liang, Zhenmei Shi, Zhao Song, Yufa Zhou
0
0
Diffusion models have made rapid progress in generating high-quality samples across various domains. However, a theoretical understanding of the Lipschitz continuity and second momentum properties of the diffusion process is still lacking. In this paper, we bridge this gap by providing a detailed examination of these smoothness properties for the case where the target data distribution is a mixture of Gaussians, which serves as a universal approximator for smooth densities such as image data. We prove that if the target distribution is a $k$-mixture of Gaussians, the density of the entire diffusion process will also be a $k$-mixture of Gaussians. We then derive tight upper bounds on the Lipschitz constant and second momentum that are independent of the number of mixture components $k$. Finally, we apply our analysis to various diffusion solvers, both SDE and ODE based, to establish concrete error guarantees in terms of the total variation distance and KL divergence between the target and learned distributions. Our results provide deeper theoretical insights into the dynamics of the diffusion process under common data distributions.
5/28/2024