Learning Quadrupedal Locomotion via Differentiable Simulation
2404.02887
0
0

Abstract
The emergence of differentiable simulators enabling analytic gradient computation has motivated a new wave of learning algorithms that hold the potential to significantly increase sample efficiency over traditional Reinforcement Learning (RL) methods. While recent research has demonstrated performance gains in scenarios with comparatively smooth dynamics and, thus, smooth optimization landscapes, research on leveraging differentiable simulators for contact-rich scenarios, such as legged locomotion, is scarce. This may be attributed to the discontinuous nature of contact, which introduces several challenges to optimizing with analytic gradients. The purpose of this paper is to determine if analytic gradients can be beneficial even in the face of contact. Our investigation focuses on the effects of different soft and hard contact models on the learning process, examining optimization challenges through the lens of contact simulation. We demonstrate the viability of employing analytic gradients to learn physically plausible locomotion skills with a quadrupedal robot using Short-Horizon Actor-Critic (SHAC), a learning algorithm leveraging analytic gradients, and draw a comparison to a state-of-the-art RL algorithm, Proximal Policy Optimization (PPO), to understand the benefits of analytic gradients.
Create account to get full access
Overview
- This paper explores using differentiable simulation to train quadrupedal robots to walk.
- The key idea is to leverage the ability to compute gradients through the simulation in order to optimize the robot's control policy.
- The authors demonstrate their approach on several benchmark quadruped locomotion tasks, showing improved performance compared to prior methods.
Plain English Explanation
Robots that can walk on four legs, like dogs or horses, have many potential applications, such as navigating difficult terrain. However, training these quadrupedal robots to walk effectively is a challenging problem. This paper introduces a new approach that aims to make the training process more efficient.
The core insight is to use a simulation model of the robot that is "differentiable." This means the simulator can provide information about how changes to the robot's control inputs (e.g. motor commands) will affect its future behavior. The researchers can then leverage this gradient information to systematically optimize the robot's control policy through an iterative process.
Intuitively, this is similar to how human beings learn to walk. We start with an initial guess at how to move our legs, get feedback on what works and what doesn't, and gradually refine our walking technique. The differentiable simulator provides this kind of feedback signal to help the robot converge on an effective walking gait.
The authors demonstrate their approach on several benchmark tasks, showing that it can produce more capable walking behaviors compared to prior methods that do not use differentiable simulation. This suggests the technique could be a valuable tool for developing more agile and versatile legged robots in the future.
Technical Explanation
The key technical innovation in this paper is the use of differentiable simulation to enable gradient-based optimization of quadruped locomotion controllers. Traditionally, training legged robots to walk has relied on trial-and-error methods or hand-engineered controllers. In contrast, the authors leverage the ability to backpropagate gradients through the simulation model in order to directly optimize the robot's control policy.
Specifically, the authors use a differentiable physics engine called MuJoCo to model the quadruped robot and its interactions with the environment. They then formulate the locomotion task as an optimization problem, where the objective is to maximize the robot's forward velocity while satisfying various constraints (e.g. joint torque limits, foot contact forces, etc.). By computing gradients of this objective with respect to the robot's control parameters, they can efficiently explore the space of possible control policies and converge on an effective gait.
The authors evaluate their approach on several benchmark quadruped locomotion tasks, including flat terrain, stepping stones, and rough terrain. They show that their differentiable simulation-based method outperforms prior reinforcement learning and optimal control approaches, producing more robust and efficient walking behaviors.
Critical Analysis
The authors provide a thorough analysis of the strengths and limitations of their approach. One key caveat is that the differentiable simulation model may not perfectly capture all the complexities of real-world robot dynamics, such as unmodeled flexibilities or contact phenomena. As a result, the controllers optimized in simulation may not transfer perfectly to the physical robot.
The authors acknowledge this "reality gap" issue and propose several mitigation strategies, such as domain randomization and model-predictive control. However, fully bridging this gap remains an open challenge that requires further research.
Another potential limitation is the computational cost of the gradient-based optimization process, which may limit the scalability of the approach to more complex robots or larger control spaces. The authors do not provide a detailed analysis of the runtime performance of their method.
Overall, this work represents a promising step towards more efficient training of quadrupedal robots using differentiable simulation. However, further research is needed to address the remaining challenges around sim-to-real transfer and computational efficiency in order to fully realize the potential of this approach.
Conclusion
This paper introduces a novel technique for training quadrupedal robots to walk using differentiable simulation. By leveraging the ability to compute gradients through the simulation model, the authors are able to efficiently optimize the robot's control policy and produce more capable locomotion behaviors compared to prior methods.
While the approach has some limitations around the fidelity of the simulation model and computational cost, the authors demonstrate its potential on several benchmark tasks. This work suggests that differentiable simulation could be a valuable tool for developing more agile and versatile legged robots in the future, with applications ranging from search-and-rescue operations to prosthetic limb control.
As the field of robotics continues to advance, techniques like this that combine simulation, optimization, and real-world deployment will likely play an increasingly important role in unlocking new capabilities and expanding the practical applications of autonomous systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
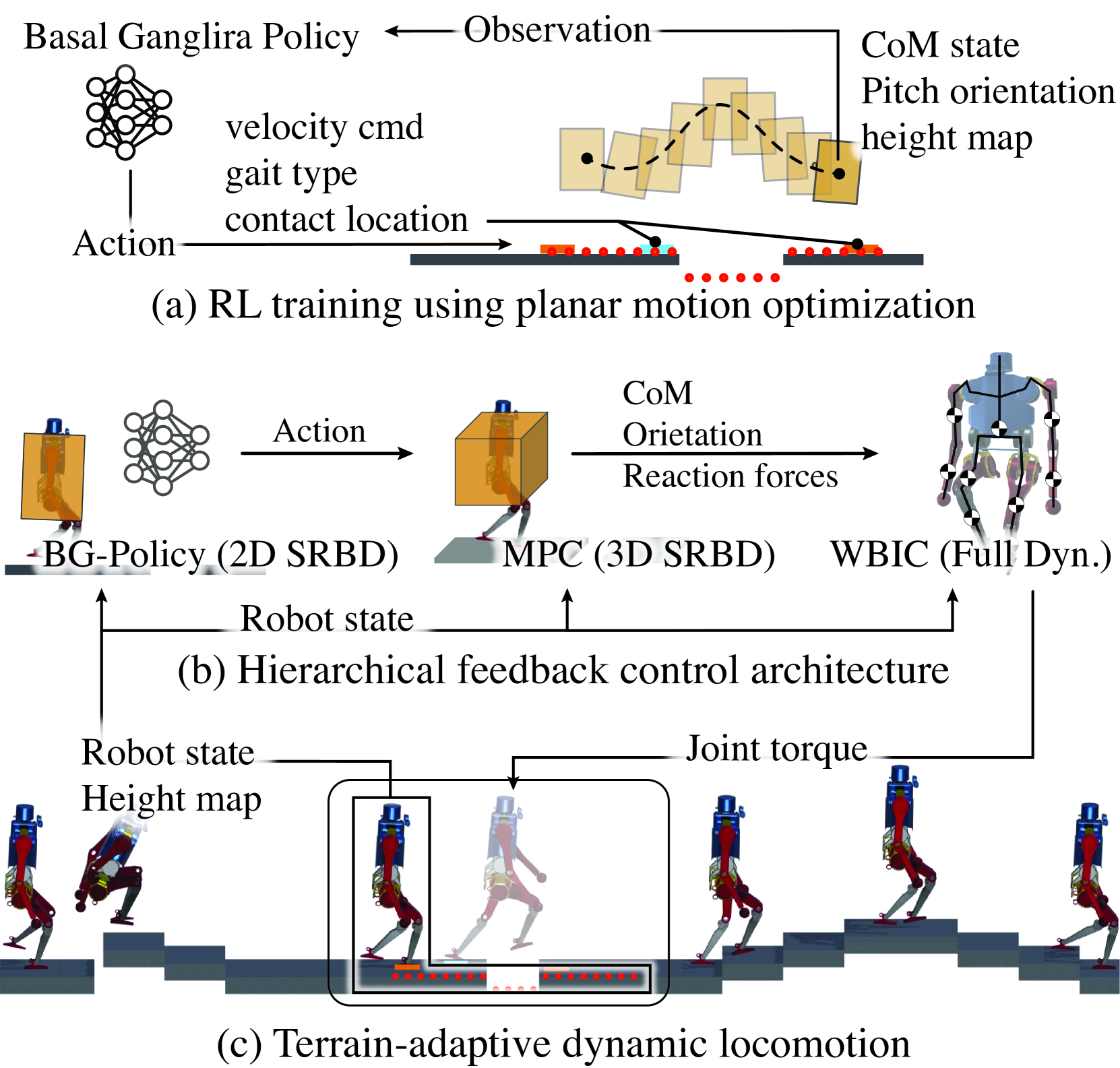
Learning Generic and Dynamic Locomotion of Humanoids Across Discrete Terrains
Shangqun Yu, Nisal Perera, Daniel Marew, Donghyun Kim
0
0
This paper addresses the challenge of terrain-adaptive dynamic locomotion in humanoid robots, a problem traditionally tackled by optimization-based methods or reinforcement learning (RL). Optimization-based methods, such as model-predictive control, excel in finding optimal reaction forces and achieving agile locomotion, especially in quadruped, but struggle with the nonlinear hybrid dynamics of legged systems and the real-time computation of step location, timing, and reaction forces. Conversely, RL-based methods show promise in navigating dynamic and rough terrains but are limited by their extensive data requirements. We introduce a novel locomotion architecture that integrates a neural network policy, trained through RL in simplified environments, with a state-of-the-art motion controller combining model-predictive control (MPC) and whole-body impulse control (WBIC). The policy efficiently learns high-level locomotion strategies, such as gait selection and step positioning, without the need for full dynamics simulations. This control architecture enables humanoid robots to dynamically navigate discrete terrains, making strategic locomotion decisions (e.g., walking, jumping, and leaping) based on ground height maps. Our results demonstrate that this integrated control architecture achieves dynamic locomotion with significantly fewer training samples than conventional RL-based methods and can be transferred to different humanoid platforms without additional training. The control architecture has been extensively tested in dynamic simulations, accomplishing terrain height-based dynamic locomotion for three different robots.
5/28/2024
🔗
Adaptive Horizon Actor-Critic for Policy Learning in Contact-Rich Differentiable Simulation
Ignat Georgiev, Krishnan Srinivasan, Jie Xu, Eric Heiden, Animesh Garg
0
0
Model-Free Reinforcement Learning (MFRL), leveraging the policy gradient theorem, has demonstrated considerable success in continuous control tasks. However, these approaches are plagued by high gradient variance due to zeroth-order gradient estimation, resulting in suboptimal policies. Conversely, First-Order Model-Based Reinforcement Learning (FO-MBRL) methods employing differentiable simulation provide gradients with reduced variance but are susceptible to sampling error in scenarios involving stiff dynamics, such as physical contact. This paper investigates the source of this error and introduces Adaptive Horizon Actor-Critic (AHAC), an FO-MBRL algorithm that reduces gradient error by adapting the model-based horizon to avoid stiff dynamics. Empirical findings reveal that AHAC outperforms MFRL baselines, attaining 40% more reward across a set of locomotion tasks and efficiently scaling to high-dimensional control environments with improved wall-clock-time efficiency.
6/5/2024
⛏️
Rethinking Robustness Assessment: Adversarial Attacks on Learning-based Quadrupedal Locomotion Controllers
Fan Shi, Chong Zhang, Takahiro Miki, Joonho Lee, Marco Hutter, Stelian Coros
0
0
Legged locomotion has recently achieved remarkable success with the progress of machine learning techniques, especially deep reinforcement learning (RL). Controllers employing neural networks have demonstrated empirical and qualitative robustness against real-world uncertainties, including sensor noise and external perturbations. However, formally investigating the vulnerabilities of these locomotion controllers remains a challenge. This difficulty arises from the requirement to pinpoint vulnerabilities across a long-tailed distribution within a high-dimensional, temporally sequential space. As a first step towards quantitative verification, we propose a computational method that leverages sequential adversarial attacks to identify weaknesses in learned locomotion controllers. Our research demonstrates that, even state-of-the-art robust controllers can fail significantly under well-designed, low-magnitude adversarial sequence. Through experiments in simulation and on the real robot, we validate our approach's effectiveness, and we illustrate how the results it generates can be used to robustify the original policy and offer valuable insights into the safety of these black-box policies. Project page: https://fanshi14.github.io/me/rss24.html
6/3/2024
🤖
Evolution and learning in differentiable robots
Luke Strgar, David Matthews, Tyler Hummer, Sam Kriegman
0
0
The automatic design of robots has existed for 30 years but has been constricted by serial non-differentiable design evaluations, premature convergence to simple bodies or clumsy behaviors, and a lack of sim2real transfer to physical machines. Thus, here we employ massively-parallel differentiable simulations to rapidly and simultaneously optimize individual neural control of behavior across a large population of candidate body plans and return a fitness score for each design based on the performance of its fully optimized behavior. Non-differentiable changes to the mechanical structure of each robot in the population -- mutations that rearrange, combine, add, or remove body parts -- were applied by a genetic algorithm in an outer loop of search, generating a continuous flow of novel morphologies with highly-coordinated and graceful behaviors honed by gradient descent. This enabled the exploration of several orders-of-magnitude more designs than all previous methods, despite the fact that robots here have the potential to be much more complex, in terms of number of independent motors, than those in prior studies. We found that evolution reliably produces ``increasingly differentiable'' robots: body plans that smooth the loss landscape in which learning operates and thereby provide better training paths toward performant behaviors. Finally, one of the highly differentiable morphologies discovered in simulation was realized as a physical robot and shown to retain its optimized behavior. This provides a cyberphysical platform to investigate the relationship between evolution and learning in biological systems and broadens our understanding of how a robot's physical structure can influence the ability to train policies for it. Videos and code at https://sites.google.com/view/eldir.
5/28/2024