Learning to Unlearn for Robust Machine Unlearning

0

Sign in to get full access
Overview
This research paper explores a novel approach to machine unlearning, which involves removing specific information from a trained machine learning model. The authors propose a meta-learning technique called "Learning to Unlearn" (L2U) that enables models to learn how to effectively unlearn information while maintaining overall performance.
Plain English Explanation
Machine learning models can become very proficient at tasks like image recognition or language processing by training on large datasets. However, these models may also inadvertently learn sensitive or private information about the individuals in the training data. Machine unlearning aims to remove this type of information from the model in a robust and reliable way.
The Learning to Unlearn for Robust Machine Unlearning paper introduces a new technique called "Learning to Unlearn" (L2U) that helps models learn how to effectively unlearn unwanted information. The key idea is to train the model to not only learn the original task, but also to learn how to remove specific parts of what it has learned. This meta-learning approach allows the model to become more adept at the unlearning process over time.
The authors test their L2U method on several machine learning tasks and datasets, and show that it outperforms previous unlearning techniques in terms of retaining overall model performance while successfully removing the target information. This work represents an important step towards building more robust and trustworthy machine learning systems that can selectively forget sensitive data when required.
Technical Explanation
The core innovation of this paper is the Learning to Unlearn (L2U) meta-learning approach. The key idea is to introduce a secondary training objective that encourages the model to learn how to effectively unlearn specific information, in addition to the primary objective of learning the original task.
During training, the model is presented with two types of examples: those that it should learn, and those that it should unlearn. The model is trained to minimize a combination of the standard task loss (e.g. classification error) and an unlearning loss that measures how well the model can remove the target information. By backpropagating gradients from both objectives, the model learns to adapt its internal representations to support both learning and unlearning.
The authors experiment with different unlearning loss functions, including gradient projection and adversarial training, and find that gradient projection works best in practice. They evaluate the L2U method on image classification and language modeling tasks, and show that it outperforms prior machine unlearning techniques in terms of unlearning performance while maintaining overall model accuracy.
Critical Analysis
The L2U approach represents an important advance in the field of machine unlearning. By framing unlearning as a meta-learning problem, the authors have developed a more principled and effective way to remove unwanted information from trained models. The experiments demonstrate the efficacy of the approach across different tasks and datasets.
However, the paper does not address some key limitations and potential issues with the L2U method. For example, the unlearning process may be computationally expensive, as it requires training the model on both learning and unlearning objectives. There are also open questions about the robustness of the unlearning process, particularly in the face of adversarial attacks designed to circumvent the unlearning.
Additionally, the paper does not explore the broader societal implications of selective machine unlearning, such as the potential for misuse or unintended consequences. Further research is needed to understand how these techniques can be deployed responsibly and ethically.
Conclusion
The "Learning to Unlearn" technique proposed in this paper represents a significant advancement in the field of machine unlearning. By framing unlearning as a meta-learning problem, the authors have developed a more principled and effective approach to removing unwanted information from trained models. The experimental results demonstrate the method's effectiveness across a range of tasks and datasets.
This work has important implications for building more trustworthy and privacy-preserving machine learning systems. As AI becomes increasingly ubiquitous in our lives, the ability to selectively forget sensitive data will be crucial for maintaining individual privacy and societal trust in these technologies. The L2U approach serves as an important step towards realizing this vision, but further research is needed to address the remaining challenges and ensure the responsible deployment of these techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning to Unlearn for Robust Machine Unlearning
Mark He Huang, Lin Geng Foo, Jun Liu
Machine unlearning (MU) seeks to remove knowledge of specific data samples from trained models without the necessity for complete retraining, a task made challenging by the dual objectives of effective erasure of data and maintaining the overall performance of the model. Despite recent advances in this field, balancing between the dual objectives of unlearning remains challenging. From a fresh perspective of generalization, we introduce a novel Learning-to-Unlearn (LTU) framework, which adopts a meta-learning approach to optimize the unlearning process to improve forgetting and remembering in a unified manner. LTU includes a meta-optimization scheme that facilitates models to effectively preserve generalizable knowledge with only a small subset of the remaining set, while thoroughly forgetting the specific data samples. We also introduce a Gradient Harmonization strategy to align the optimization trajectories for remembering and forgetting via mitigating gradient conflicts, thus ensuring efficient and effective model updates. Our approach demonstrates improved efficiency and efficacy for MU, offering a promising solution to the challenges of data rights and model reusability.
Read more7/16/2024
0
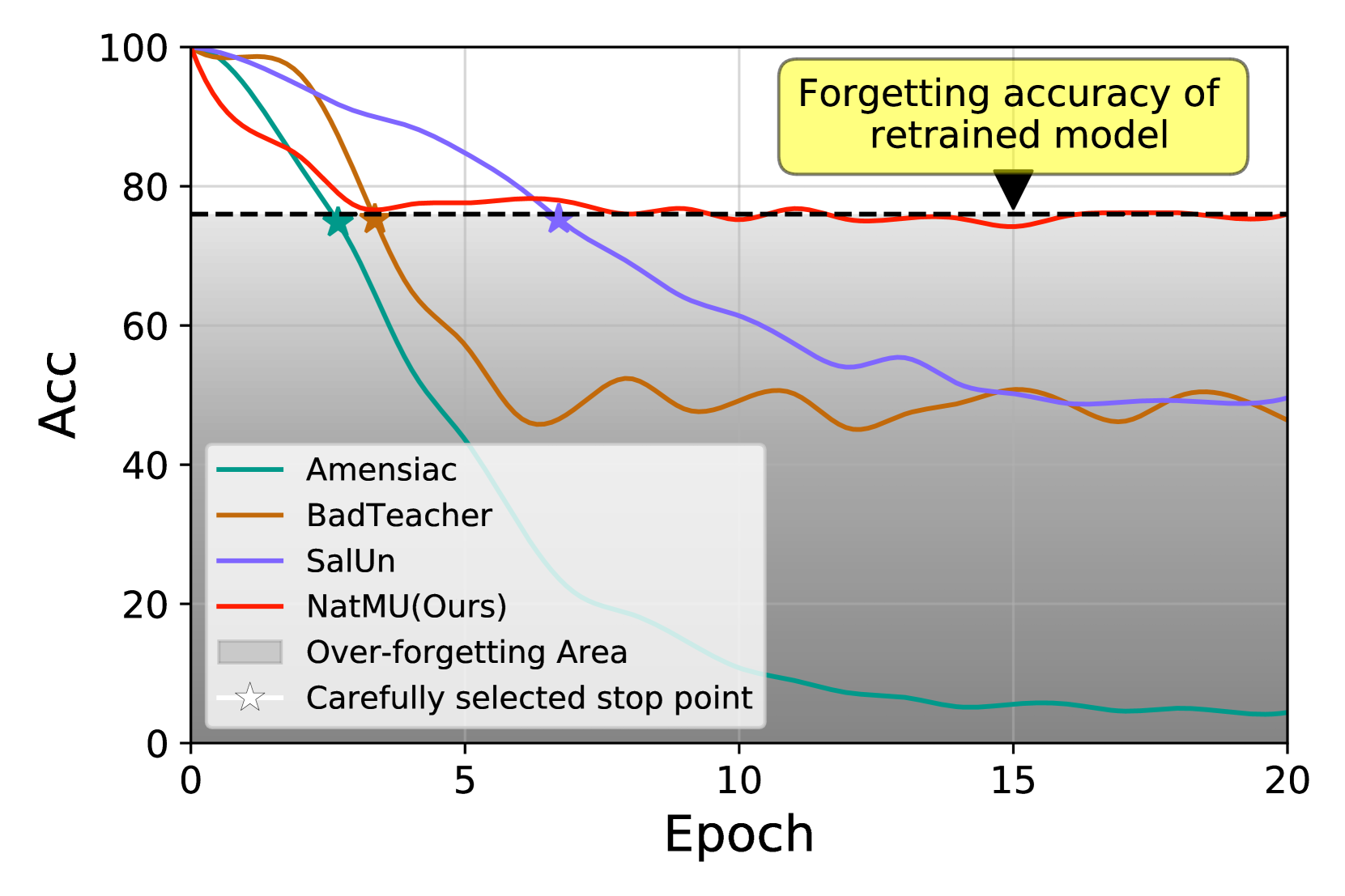
Towards Natural Machine Unlearning
Zhengbao He, Tao Li, Xinwen Cheng, Zhehao Huang, Xiaolin Huang
Machine unlearning (MU) aims to eliminate information that has been learned from specific training data, namely forgetting data, from a pre-trained model. Currently, the mainstream of existing MU methods involves modifying the forgetting data with incorrect labels and subsequently fine-tuning the model. While learning such incorrect information can indeed remove knowledge, the process is quite unnatural as the unlearning process undesirably reinforces the incorrect information and leads to over-forgetting. Towards more textit{natural} machine unlearning, we inject correct information from the remaining data to the forgetting samples when changing their labels. Through pairing these adjusted samples with their labels, the model will tend to use the injected correct information and naturally suppress the information meant to be forgotten. Albeit straightforward, such a first step towards natural machine unlearning can significantly outperform current state-of-the-art approaches. In particular, our method substantially reduces the over-forgetting and leads to strong robustness to hyperparameters, making it a promising candidate for practical machine unlearning.
Read more5/27/2024

0
Rethinking Machine Unlearning for Large Language Models
Sijia Liu, Yuanshun Yao, Jinghan Jia, Stephen Casper, Nathalie Baracaldo, Peter Hase, Yuguang Yao, Chris Yuhao Liu, Xiaojun Xu, Hang Li, Kush R. Varshney, Mohit Bansal, Sanmi Koyejo, Yang Liu
We explore machine unlearning (MU) in the domain of large language models (LLMs), referred to as LLM unlearning. This initiative aims to eliminate undesirable data influence (e.g., sensitive or illegal information) and the associated model capabilities, while maintaining the integrity of essential knowledge generation and not affecting causally unrelated information. We envision LLM unlearning becoming a pivotal element in the life-cycle management of LLMs, potentially standing as an essential foundation for developing generative AI that is not only safe, secure, and trustworthy, but also resource-efficient without the need of full retraining. We navigate the unlearning landscape in LLMs from conceptual formulation, methodologies, metrics, and applications. In particular, we highlight the often-overlooked aspects of existing LLM unlearning research, e.g., unlearning scope, data-model interaction, and multifaceted efficacy assessment. We also draw connections between LLM unlearning and related areas such as model editing, influence functions, model explanation, adversarial training, and reinforcement learning. Furthermore, we outline an effective assessment framework for LLM unlearning and explore its applications in copyright and privacy safeguards and sociotechnical harm reduction.
Read more7/16/2024

0
What makes unlearning hard and what to do about it
Kairan Zhao, Meghdad Kurmanji, George-Octavian Bu{a}rbulescu, Eleni Triantafillou, Peter Triantafillou
Machine unlearning is the problem of removing the effect of a subset of training data (the ''forget set'') from a trained model without damaging the model's utility e.g. to comply with users' requests to delete their data, or remove mislabeled, poisoned or otherwise problematic data. With unlearning research still being at its infancy, many fundamental open questions exist: Are there interpretable characteristics of forget sets that substantially affect the difficulty of the problem? How do these characteristics affect different state-of-the-art algorithms? With this paper, we present the first investigation aiming to answer these questions. We identify two key factors affecting unlearning difficulty and the performance of unlearning algorithms. Evaluation on forget sets that isolate these identified factors reveals previously-unknown behaviours of state-of-the-art algorithms that don't materialize on random forget sets. Based on our insights, we develop a framework coined Refined-Unlearning Meta-algorithm (RUM) that encompasses: (i) refining the forget set into homogenized subsets, according to different characteristics; and (ii) a meta-algorithm that employs existing algorithms to unlearn each subset and finally delivers a model that has unlearned the overall forget set. We find that RUM substantially improves top-performing unlearning algorithms. Overall, we view our work as an important step in (i) deepening our scientific understanding of unlearning and (ii) revealing new pathways to improving the state-of-the-art.
Read more6/4/2024