LEAST: Local text-conditioned image style transfer

0
Sign in to get full access
Overview
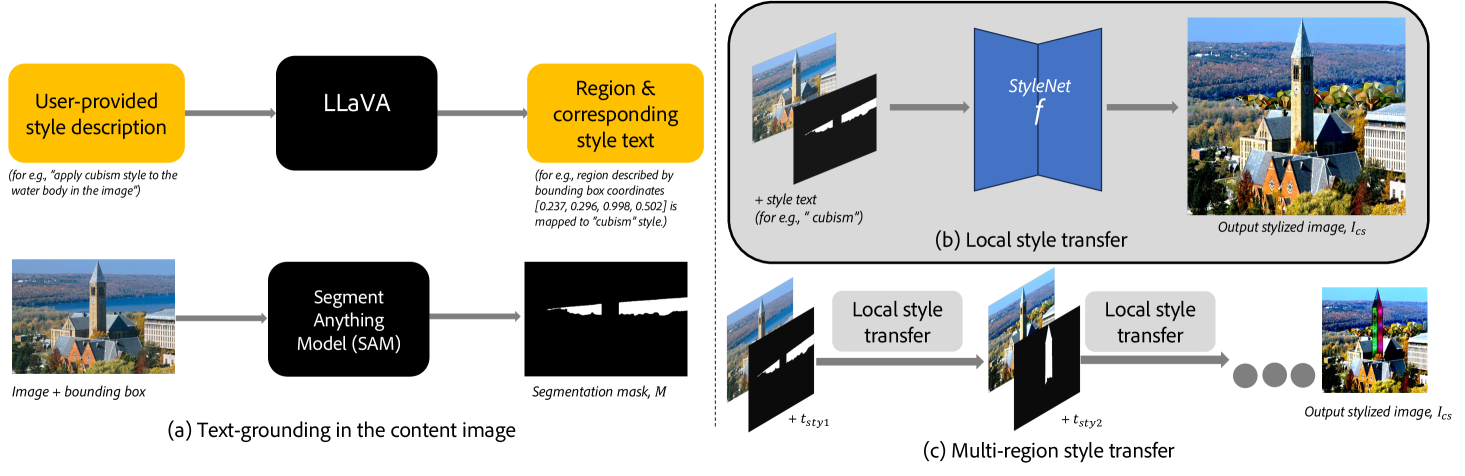
- This paper introduces LEAST, a novel approach for "local" text-conditioned image style transfer.
- LEAST aims to enable more fine-grained and controllable style transfer by allowing users to specify text descriptions for different regions of an image.
- The method leverages a combination of language and vision models to capture and transfer styles based on the provided text input.
Plain English Explanation
LEAST is a new technique for adjusting the style of an image in a more targeted and customizable way. Rather than applying a single style across the whole image, LEAST allows users to specify text descriptions for different parts of the image. For example, you could say "make the sky look dreamy and the grass look vibrant." The system then uses these text descriptions to transfer the corresponding styles to the relevant regions of the image.
This is a more advanced approach compared to existing text-to-image style transfer methods, which typically apply a single, global style. By enabling "local" style transfer based on specific text inputs, LEAST gives users finer control over the final artistic look and feel of the image.
Technical Explanation
The key innovation in LEAST is its ability to map text descriptions to localized style adjustments within an image. The system first encodes the input image using a vision model and the text descriptions using a language model. It then learns to align these text and visual features, allowing it to identify which parts of the image correspond to the provided text inputs.
Based on this text-image alignment, LEAST can selectively apply different style transfer operations to different regions of the image. This is in contrast to prior work, which typically applied a single, global style transfer. The authors demonstrate LEAST's capabilities across a range of artistic styles and use cases, showing how it enables more expressive and customizable image stylization.
Critical Analysis
While LEAST represents an interesting advancement in text-conditioned image editing, the paper acknowledges some limitations. For instance, the method relies on accurate text-image alignment, which can be challenging in complex scenes. Additionally, the quality of the final stylized images is still dependent on the capabilities of the underlying style transfer models.
Further research could explore ways to improve the robustness and generalization of the text-to-style mapping, perhaps by incorporating additional modalities or leveraging large-scale pretraining. There may also be opportunities to extend the LEAST framework to other image editing tasks beyond style transfer, such as selective color adjustment or semantic image manipulation.
Overall, LEAST represents a promising step towards more expressive and controllable image editing, with potential applications in areas like digital art, visual effects, and personalized content creation.
Conclusion
The LEAST method introduced in this paper enables a new level of text-conditioned image style transfer, allowing users to customize the artistic look and feel of different regions within a single image. By leveraging language and vision models to align text descriptions with localized style adjustments, LEAST opens up new possibilities for creative expression and personalization in digital imaging.
While the approach has some limitations, it represents an important advancement in the field of text-to-image synthesis, with potential impacts on various creative and artistic applications. As the underlying models and techniques continue to evolve, we can expect to see increasingly sophisticated and user-friendly image editing tools that empower people to bring their creative visions to life.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LEAST: Local text-conditioned image style transfer
Silky Singh, Surgan Jandial, Simra Shahid, Abhinav Java
Text-conditioned style transfer enables users to communicate their desired artistic styles through text descriptions, offering a new and expressive means of achieving stylization. In this work, we evaluate the text-conditioned image editing and style transfer techniques on their fine-grained understanding of user prompts for precise local style transfer. We find that current methods fail to accomplish localized style transfers effectively, either failing to localize style transfer to certain regions in the image, or distorting the content and structure of the input image. To this end, we carefully design an end-to-end pipeline that guarantees local style transfer according to users' intent. Further, we substantiate the effectiveness of our approach through quantitative and qualitative analysis. The project code is available at: https://github.com/silky1708/local-style-transfer.
Read more5/28/2024

0
InstantStyle-Plus: Style Transfer with Content-Preserving in Text-to-Image Generation
Haofan Wang, Peng Xing, Renyuan Huang, Hao Ai, Qixun Wang, Xu Bai
Style transfer is an inventive process designed to create an image that maintains the essence of the original while embracing the visual style of another. Although diffusion models have demonstrated impressive generative power in personalized subject-driven or style-driven applications, existing state-of-the-art methods still encounter difficulties in achieving a seamless balance between content preservation and style enhancement. For example, amplifying the style's influence can often undermine the structural integrity of the content. To address these challenges, we deconstruct the style transfer task into three core elements: 1) Style, focusing on the image's aesthetic characteristics; 2) Spatial Structure, concerning the geometric arrangement and composition of visual elements; and 3) Semantic Content, which captures the conceptual meaning of the image. Guided by these principles, we introduce InstantStyle-Plus, an approach that prioritizes the integrity of the original content while seamlessly integrating the target style. Specifically, our method accomplishes style injection through an efficient, lightweight process, utilizing the cutting-edge InstantStyle framework. To reinforce the content preservation, we initiate the process with an inverted content latent noise and a versatile plug-and-play tile ControlNet for preserving the original image's intrinsic layout. We also incorporate a global semantic adapter to enhance the semantic content's fidelity. To safeguard against the dilution of style information, a style extractor is employed as discriminator for providing supplementary style guidance. Codes will be available at https://github.com/instantX-research/InstantStyle-Plus.
Read more7/2/2024

0
Regional Style and Color Transfer
Zhicheng Ding, Panfeng Li, Qikai Yang, Siyang Li, Qingtian Gong
This paper presents a novel contribution to the field of regional style transfer. Existing methods often suffer from the drawback of applying style homogeneously across the entire image, leading to stylistic inconsistencies or foreground object twisted when applied to image with foreground elements such as person figures. To address this limitation, we propose a new approach that leverages a segmentation network to precisely isolate foreground objects within the input image. Subsequently, style transfer is applied exclusively to the background region. The isolated foreground objects are then carefully reintegrated into the style-transferred background. To enhance the visual coherence between foreground and background, a color transfer step is employed on the foreground elements prior to their rein-corporation. Finally, we utilize feathering techniques to achieve a seamless amalgamation of foreground and background, resulting in a visually unified and aesthetically pleasing final composition. Extensive evaluations demonstrate that our proposed approach yields significantly more natural stylistic transformations compared to conventional methods.
Read more9/17/2024

0
FreeStyle: Free Lunch for Text-guided Style Transfer using Diffusion Models
Feihong He, Gang Li, Mengyuan Zhang, Leilei Yan, Lingyu Si, Fanzhang Li, Li Shen
The rapid development of generative diffusion models has significantly advanced the field of style transfer. However, most current style transfer methods based on diffusion models typically involve a slow iterative optimization process, e.g., model fine-tuning and textual inversion of style concept. In this paper, we introduce FreeStyle, an innovative style transfer method built upon a pre-trained large diffusion model, requiring no further optimization. Besides, our method enables style transfer only through a text description of the desired style, eliminating the necessity of style images. Specifically, we propose a dual-stream encoder and single-stream decoder architecture, replacing the conventional U-Net in diffusion models. In the dual-stream encoder, two distinct branches take the content image and style text prompt as inputs, achieving content and style decoupling. In the decoder, we further modulate features from the dual streams based on a given content image and the corresponding style text prompt for precise style transfer. Our experimental results demonstrate high-quality synthesis and fidelity of our method across various content images and style text prompts. Compared with state-of-the-art methods that require training, our FreeStyle approach notably reduces the computational burden by thousands of iterations, while achieving comparable or superior performance across multiple evaluation metrics including CLIP Aesthetic Score, CLIP Score, and Preference. We have released the code anonymously at: href{https://anonymous.4open.science/r/FreeStyleAnonymous-0F9B}
Read more7/19/2024