Leveraging advances in machine learning for the robust classification and interpretation of networks
2403.13215
0
0
Abstract
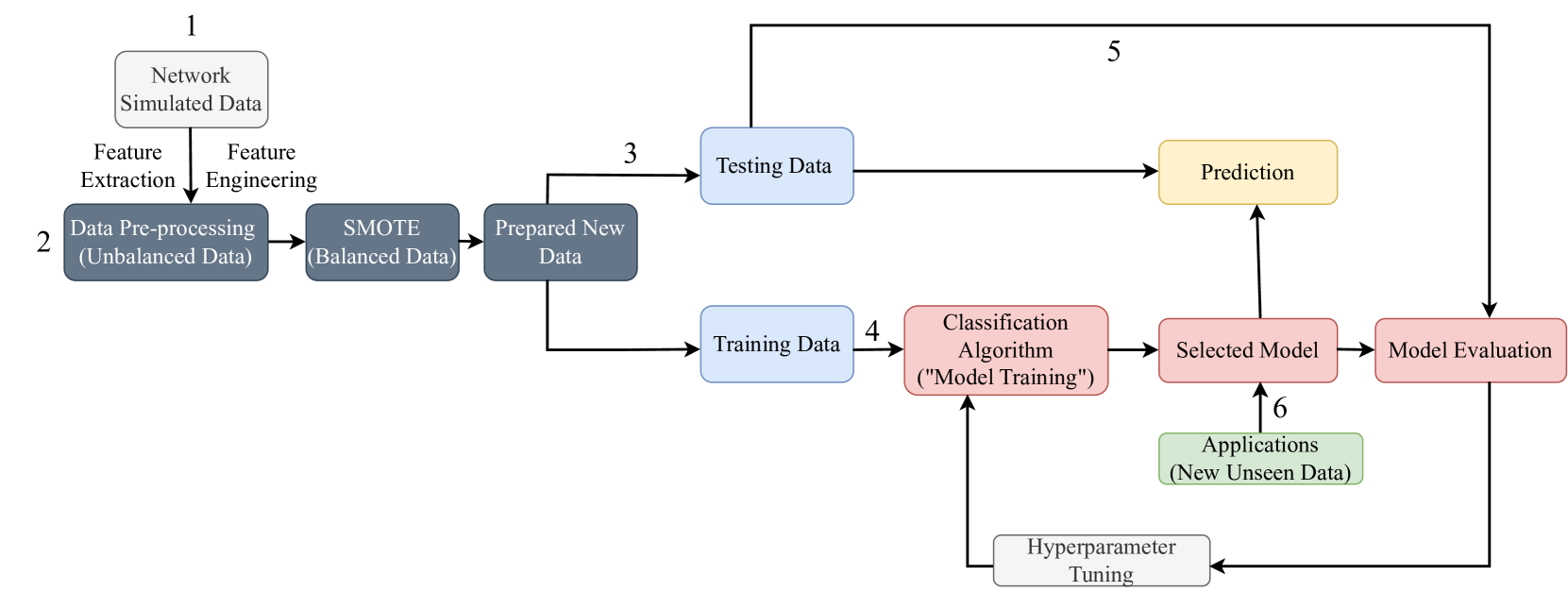
The ability to simulate realistic networks based on empirical data is an important task across scientific disciplines, from epidemiology to computer science. Often simulation approaches involve selecting a suitable network generative model such as Erdos-R'enyi or small-world. However, few tools are available to quantify if a particular generative model is suitable for capturing a given network structure or organization. We utilize advances in interpretable machine learning to classify simulated networks by our generative models based on various network attributes, using both primary features and their interactions. Our study underscores the significance of specific network features and their interactions in distinguishing generative models, comprehending complex network structures, and the formation of real-world networks.
Create account to get full access
Overview
- The paper investigates the factors that contribute to the formation of "small-world" networks, which are characterized by high clustering and short path lengths.
- The researchers leverage machine learning techniques to predict and classify network structures based on various topological and statistical features.
- The goal is to develop robust and accurate models for understanding and characterizing the mechanisms underlying network growth and evolution.
Plain English Explanation
"Small-world" networks are a type of network structure that have a unique set of properties. They are highly interconnected, with clusters of nodes that are closely linked to each other, but also have relatively short paths between any two nodes in the network. This combination of local clustering and global connectivity is what gives small-world networks their distinctive "small-world" feel.
The researchers in this paper wanted to better understand what factors lead to the formation of these small-world networks. They used machine learning techniques to analyze the network features, such as the number of connections, the distribution of connections, and the overall pattern of connections. By training machine learning models on data from many different types of networks, they were able to develop predictive algorithms that can identify the key characteristics that make a network a small-world network.
This is important because small-world networks are found in many real-world systems, from social networks to biological systems. By understanding the underlying mechanisms that create these networks, researchers can gain insights into how these systems function and evolve over time. The machine learning approach used in this paper provides a powerful tool for uncovering these patterns in a robust and systematic way.
Technical Explanation
The paper begins by introducing the concept of small-world networks and outlining the key network features that are used to characterize them, such as the clustering coefficient and average path length.
The researchers then describe their data collection process, which involved generating a large dataset of synthetic networks with varying topological and statistical properties. They used this dataset to train and evaluate several machine learning models, including logistic regression, support vector machines, and [neural networks], for the tasks of predicting and classifying small-world networks.
The key findings of the paper include:
- Certain network features, such as the degree distribution and modularity, are particularly informative for distinguishing small-world networks from other types of networks.
- The machine learning models were able to achieve high accuracy in both predicting the small-world property and classifying networks into small-world and non-small-world categories.
- The models were also found to be robust to noise and variations in the input data, suggesting their potential for real-world applications.
Critical Analysis
The paper presents a comprehensive and well-designed study that leverages machine learning techniques to shed light on the structural characteristics of small-world networks. The use of a large synthetic dataset to train and test the models is a particularly notable strength, as it allows the researchers to explore a wide range of network topologies and properties.
One potential limitation of the study is the reliance on synthetic data, which may not fully capture the complexities and nuances of real-world networks. It would be valuable to see how the models perform on empirical datasets from various domains, such as social networks, biological systems, or infrastructure networks.
Additionally, the paper does not delve into the potential implications or applications of the research, beyond the general statement that understanding small-world networks can provide insights into the underlying mechanisms of many complex systems. It would be interesting to explore more specific use cases or areas where these findings could be leveraged, such as network optimization, anomaly detection, or disease modeling.
Conclusion
This paper represents a significant contribution to the field of network science by demonstrating the effectiveness of machine learning in predicting and classifying small-world network structures. The robust and accurate models developed in this study offer a valuable tool for researchers and practitioners seeking to understand the fundamental drivers of network formation and evolution.
The insights gained from this research can have broad implications across a wide range of disciplines, from social sciences to biology and engineering. By uncovering the key topological and statistical features that distinguish small-world networks, the findings of this paper pave the way for further advancements in network-based modeling, analysis, and optimization.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Learning the mechanisms of network growth
Lourens Touwen, Doina Bucur, Remco van der Hofstad, Alessandro Garavaglia, Nelly Litvak
0
0
We propose a novel model-selection method for dynamic networks. Our approach involves training a classifier on a large body of synthetic network data. The data is generated by simulating nine state-of-the-art random graph models for dynamic networks, with parameter range chosen to ensure exponential growth of the network size in time. We design a conceptually novel type of dynamic features that count new links received by a group of vertices in a particular time interval. The proposed features are easy to compute, analytically tractable, and interpretable. Our approach achieves a near-perfect classification of synthetic networks, exceeding the state-of-the-art by a large margin. Applying our classification method to real-world citation networks gives credibility to the claims in the literature that models with preferential attachment, fitness and aging fit real-world citation networks best, although sometimes, the predicted model does not involve vertex fitness.
5/28/2024

Flexible inference in heterogeneous and attributed multilayer networks
Martina Contisciani, Marius Hobbhahn, Eleanor A. Power, Philipp Hennig, Caterina De Bacco
0
0
Networked datasets are often enriched by different types of information about individual nodes or edges. However, most existing methods for analyzing such datasets struggle to handle the complexity of heterogeneous data, often requiring substantial model-specific analysis. In this paper, we develop a probabilistic generative model to perform inference in multilayer networks with arbitrary types of information. Our approach employs a Bayesian framework combined with the Laplace matching technique to ease interpretation of inferred parameters. Furthermore, the algorithmic implementation relies on automatic differentiation, avoiding the need for explicit derivations. This makes our model scalable and flexible to adapt to any combination of input data. We demonstrate the effectiveness of our method in detecting overlapping community structures and performing various prediction tasks on heterogeneous multilayer data, where nodes and edges have different types of attributes. Additionally, we showcase its ability to unveil a variety of patterns in a social support network among villagers in rural India by effectively utilizing all input information in a meaningful way.
6/3/2024
🌐
Machine learning of network inference enhancement from noisy measurements
Kai Wu, Yuanyuan Li, Jing Liu
0
0
Inferring networks from observed time series data presents a clear glimpse into the interconnections among nodes. Network inference models, when dealing with real-world open cases, especially in the presence of observational noise, experience a sharp decline in performance, significantly undermining their practical applicability. We find that in real-world scenarios, noisy samples cause parameter updates in network inference models to deviate from the correct direction, leading to a degradation in performance. Here, we present an elegant and efficient model-agnostic framework tailored to amplify the capabilities of model-based and model-free network inference models for real-world cases. Extensive experiments across nonlinear dynamics, evolutionary games, and epidemic spreading, showcases substantial performance augmentation under varied noise types, particularly thriving in scenarios enriched with clean samples.
5/7/2024
🌀
Sifting out communities in large sparse networks
Sharlee Climer, Kenneth Smith Jr, Wei Yang, Lisa de las Fuentes, Victor G. D'avila-Rom'an, C. Charles Gu
0
0
Research data sets are growing to unprecedented sizes and network modeling is commonly used to extract complex relationships in diverse domains, such as genetic interactions involved in disease, logistics, and social communities. As the number of nodes increases in a network, an increasing sparsity of edges is a practical limitation due to memory restrictions. Moreover, many of these sparse networks exhibit very large numbers of nodes with no adjacent edges, as well as disjoint components of nodes with no edges connecting them. A prevalent aim in network modeling is the identification of clusters, or communities, of nodes that are highly interrelated. Several definitions of strong community structure have been introduced to facilitate this task, each with inherent assumptions and biases. We introduce an intuitive objective function for quantifying the quality of clustering results in large sparse networks. We utilize a two-step method for identifying communities which is especially well-suited for this domain as the first step efficiently divides the network into the disjoint components, while the second step optimizes clustering of the produced components based on the new objective. Using simulated networks, optimization based on the new objective function consistently yields significantly higher accuracy than those based on the modularity function, with the widest gaps appearing for the noisiest networks. Additionally, applications to benchmark problems illustrate the intuitive correctness of our approach. Finally, the practicality of our approach is demonstrated in real-world data in which we identify complex genetic interactions in large-scale networks comprised of tens of thousands of nodes. Based on these three different types of trials, our results clearly demonstrate the usefulness of our two-step procedure and the accuracy of our simple objective.
5/3/2024