Sifting out communities in large sparse networks
2405.00816
0
0
🌀
Abstract
Research data sets are growing to unprecedented sizes and network modeling is commonly used to extract complex relationships in diverse domains, such as genetic interactions involved in disease, logistics, and social communities. As the number of nodes increases in a network, an increasing sparsity of edges is a practical limitation due to memory restrictions. Moreover, many of these sparse networks exhibit very large numbers of nodes with no adjacent edges, as well as disjoint components of nodes with no edges connecting them. A prevalent aim in network modeling is the identification of clusters, or communities, of nodes that are highly interrelated. Several definitions of strong community structure have been introduced to facilitate this task, each with inherent assumptions and biases. We introduce an intuitive objective function for quantifying the quality of clustering results in large sparse networks. We utilize a two-step method for identifying communities which is especially well-suited for this domain as the first step efficiently divides the network into the disjoint components, while the second step optimizes clustering of the produced components based on the new objective. Using simulated networks, optimization based on the new objective function consistently yields significantly higher accuracy than those based on the modularity function, with the widest gaps appearing for the noisiest networks. Additionally, applications to benchmark problems illustrate the intuitive correctness of our approach. Finally, the practicality of our approach is demonstrated in real-world data in which we identify complex genetic interactions in large-scale networks comprised of tens of thousands of nodes. Based on these three different types of trials, our results clearly demonstrate the usefulness of our two-step procedure and the accuracy of our simple objective.
Create account to get full access
Overview
- Research datasets are growing in size, and network modeling is commonly used to understand complex relationships in diverse domains.
- However, as the number of nodes increases, the sparsity of edges becomes a practical limitation due to memory restrictions.
- Many sparse networks have a large number of nodes with no adjacent edges, as well as disjoint components with no connecting edges.
- A key aim in network modeling is to identify clusters or communities of highly interrelated nodes.
- Several definitions of strong community structure have been introduced, each with inherent assumptions and biases.
Plain English Explanation
Networks are used to model and study complex relationships in many fields, such as genetics, logistics, and social communities. As these networks grow larger, with more and more nodes (e.g., people, genes, or businesses), they often become very sparse, meaning there are relatively few connections between the nodes. This sparsity can make it challenging to analyze the networks and identify important clusters or communities of closely related nodes.
The researchers introduce a new way to measure the quality of clustering or community detection in these large, sparse networks. Their approach is designed to work especially well when there are many nodes with no connections, as well as completely separate groups of nodes that aren't connected to each other at all. By first efficiently dividing the network into these separate components, and then optimizing the clustering of each component, the researchers are able to consistently identify communities more accurately than previous methods, especially in noisy or complex networks.
Technical Explanation
The researchers propose a new objective function for quantifying the quality of clustering results in large, sparse networks. This is motivated by the practical limitations of memory and the common occurrence of nodes with no adjacent edges, as well as disjoint components without any connecting edges.
To address these challenges, the researchers introduce a two-step method. The first step efficiently divides the network into disjoint components, while the second step optimizes the clustering of these components based on the new objective function.
Through experiments on simulated networks, the researchers show that their new objective function consistently yields significantly higher accuracy in community detection compared to the commonly used modularity function, especially for noisier networks. They also demonstrate the intuitive correctness of their approach on benchmark problems, and show its practicality on real-world data, where they identify complex genetic interactions in large-scale networks.
Critical Analysis
The researchers acknowledge that their proposed objective function and two-step method make inherent assumptions and may have certain biases, just like the definitions of community structure they aim to improve upon. While the results on simulated and benchmark networks are promising, it would be valuable to further analyze the limitations and potential issues of their approach, especially when applied to real-world networks with unknown ground truth.
Additionally, the researchers could explore how their method performs compared to other advanced community detection algorithms, such as those that leverage robust graph embedding methods or mixed-membership models. Comparing the strengths and weaknesses of different approaches in a more comprehensive way would strengthen the critical evaluation of the proposed technique.
Conclusion
This research introduces a novel objective function and two-step method for identifying communities in large, sparse networks. By efficiently dividing the network into disjoint components and then optimizing the clustering of these components, the researchers demonstrate significantly improved accuracy over previous approaches, especially in noisy or complex networks.
The practical value of this work is highlighted by the researchers' application to real-world data, where they were able to uncover complex genetic interactions in large-scale networks. While the method has certain inherent assumptions and limitations, it represents an important advance in the field of network analysis and community detection, with potentially far-reaching implications across diverse domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Simultaneous Identification of Sparse Structures and Communities in Heterogeneous Graphical Models
Dapeng Shi, Tiandong Wang, Zhiliang Ying
0
0
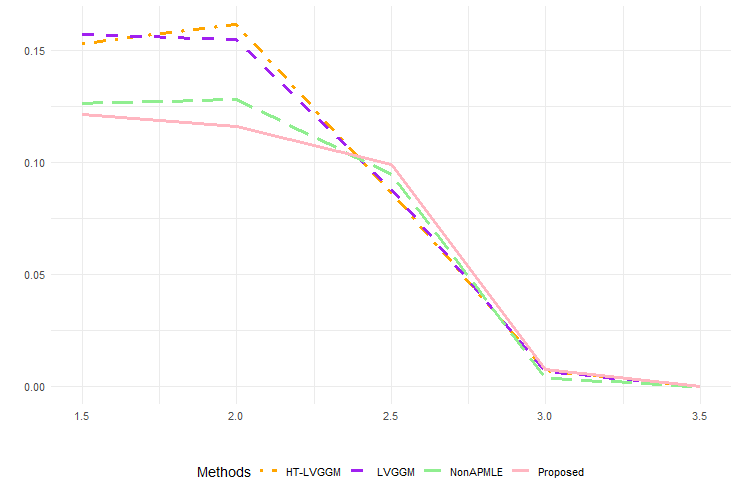
Exploring and detecting community structures hold significant importance in genetics, social sciences, neuroscience, and finance. Especially in graphical models, community detection can encourage the exploration of sets of variables with group-like properties. In this paper, within the framework of Gaussian graphical models, we introduce a novel decomposition of the underlying graphical structure into a sparse part and low-rank diagonal blocks (non-overlapped communities). We illustrate the significance of this decomposition through two modeling perspectives and propose a three-stage estimation procedure with a fast and efficient algorithm for the identification of the sparse structure and communities. Also on the theoretical front, we establish conditions for local identifiability and extend the traditional irrepresentability condition to an adaptive form by constructing an effective norm, which ensures the consistency of model selection for the adaptive $ell_1$ penalized estimator in the second stage. Moreover, we also provide the clustering error bound for the K-means procedure in the third stage. Extensive numerical experiments are conducted to demonstrate the superiority of the proposed method over existing approaches in estimating graph structures. Furthermore, we apply our method to the stock return data, revealing its capability to accurately identify non-overlapped community structures.
5/17/2024
Leveraging advances in machine learning for the robust classification and interpretation of networks
Raima Carol Appaw, Nicholas Fountain-Jones, Michael A. Charleston
0
0
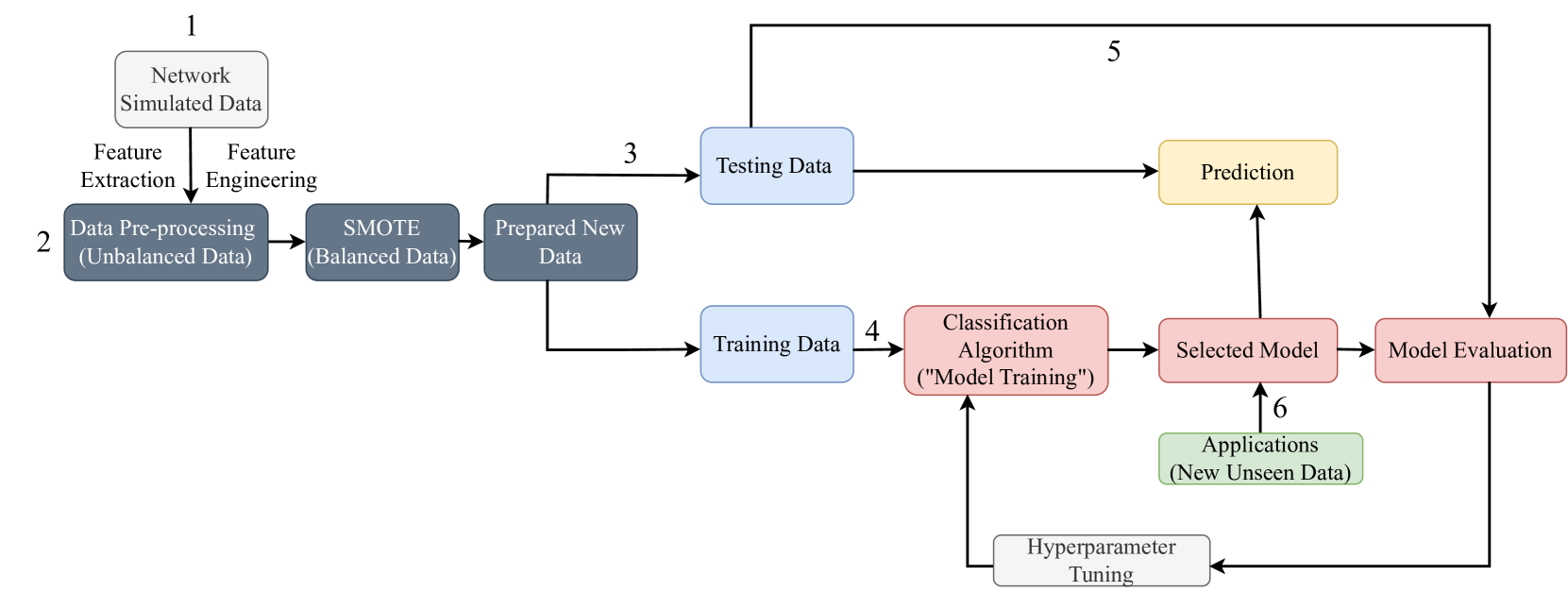
The ability to simulate realistic networks based on empirical data is an important task across scientific disciplines, from epidemiology to computer science. Often simulation approaches involve selecting a suitable network generative model such as Erdos-R'enyi or small-world. However, few tools are available to quantify if a particular generative model is suitable for capturing a given network structure or organization. We utilize advances in interpretable machine learning to classify simulated networks by our generative models based on various network attributes, using both primary features and their interactions. Our study underscores the significance of specific network features and their interactions in distinguishing generative models, comprehending complex network structures, and the formation of real-world networks.
6/13/2024
🔎
Community Detection for Heterogeneous Multiple Social Networks
Ziqing Zhu, Guan Yuan, Tao Zhou, Jiuxin Cao
0
0
The community plays a crucial role in understanding user behavior and network characteristics in social networks. Some users can use multiple social networks at once for a variety of objectives. These users are called overlapping users who bridge different social networks. Detecting communities across multiple social networks is vital for interaction mining, information diffusion, and behavior migration analysis among networks. This paper presents a community detection method based on nonnegative matrix tri-factorization for multiple heterogeneous social networks, which formulates a common consensus matrix to represent the global fused community. Specifically, the proposed method involves creating adjacency matrices based on network structure and content similarity, followed by alignment matrices which distinguish overlapping users in different social networks. With the generated alignment matrices, the method could enhance the fusion degree of the global community by detecting overlapping user communities across networks. The effectiveness of the proposed method is evaluated with new metrics on Twitter, Instagram, and Tumblr datasets. The results of the experiments demonstrate its superior performance in terms of community quality and community fusion.
5/8/2024

Estimating mixed memberships in multi-layer networks
Huan Qing
0
0
Community detection in multi-layer networks has emerged as a crucial area of modern network analysis. However, conventional approaches often assume that nodes belong exclusively to a single community, which fails to capture the complex structure of real-world networks where nodes may belong to multiple communities simultaneously. To address this limitation, we propose novel spectral methods to estimate the common mixed memberships in the multi-layer mixed membership stochastic block model. The proposed methods leverage the eigen-decomposition of three aggregate matrices: the sum of adjacency matrices, the debiased sum of squared adjacency matrices, and the sum of squared adjacency matrices. We establish rigorous theoretical guarantees for the consistency of our methods. Specifically, we derive per-node error rates under mild conditions on network sparsity, demonstrating their consistency as the number of nodes and/or layers increases under the multi-layer mixed membership stochastic block model. Our theoretical results reveal that the method leveraging the sum of adjacency matrices generally performs poorer than the other two methods for mixed membership estimation in multi-layer networks. We conduct extensive numerical experiments to empirically validate our theoretical findings. For real-world multi-layer networks with unknown community information, we introduce two novel modularity metrics to quantify the quality of mixed membership community detection. Finally, we demonstrate the practical applications of our algorithms and modularity metrics by applying them to real-world multi-layer networks, demonstrating their effectiveness in extracting meaningful community structures.
4/8/2024