Leveraging (Biased) Information: Multi-armed Bandits with Offline Data
2405.02594
0
0
Abstract
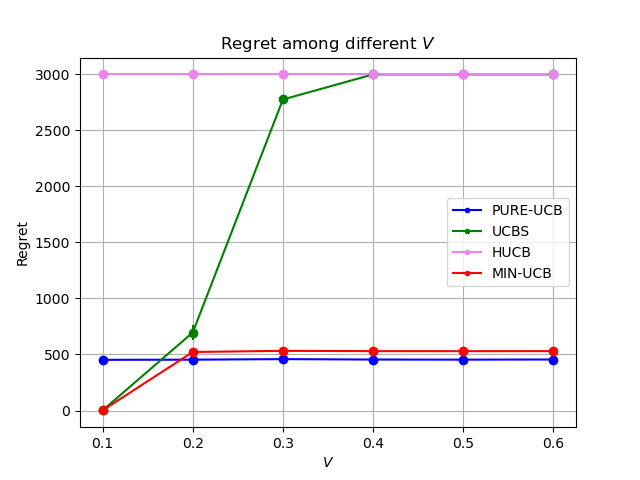
We leverage offline data to facilitate online learning in stochastic multi-armed bandits. The probability distributions that govern the offline data and the online rewards can be different. Without any non-trivial upper bound on their difference, we show that no non-anticipatory policy can outperform the UCB policy by (Auer et al. 2002), even in the presence of offline data. In complement, we propose an online policy MIN-UCB, which outperforms UCB when a non-trivial upper bound is given. MIN-UCB adaptively chooses to utilize the offline data when they are deemed informative, and to ignore them otherwise. MIN-UCB is shown to be tight in terms of both instance independent and dependent regret bounds. Finally, we corroborate the theoretical results with numerical experiments.
Create account to get full access
Overview
- Explores the use of offline data to improve decision-making in multi-armed bandit (MAB) problems
- Proposes new algorithms that leverage biased offline data to enhance exploration and exploitation in MAB settings
- Demonstrates the effectiveness of the proposed approaches through theoretical analysis and empirical evaluations
Plain English Explanation
In many real-world decision-making scenarios, we often have access to historical data that can provide useful information, even if that data is not perfectly representative of the current situation. This paper explores how to leverage such "biased" offline data to improve the performance of multi-armed bandit (MAB) algorithms, which are widely used in areas like personalized recommendations and online advertising.
MAB algorithms face a fundamental tradeoff between exploration (trying new options to gain more information) and exploitation (choosing the best option based on current knowledge). The authors propose new algorithms that can use offline data to guide this exploration-exploitation balance, leading to better overall decision-making.
For example, imagine an e-commerce company trying to determine which product variants to display to customers. They may have historical sales data that is biased due to factors like previous marketing campaigns or product availability. The algorithms in this paper show how to use that biased data to inform the exploration-exploitation tradeoff, potentially leading to higher overall revenue compared to traditional MAB approaches.
Technical Explanation
The paper introduces two new algorithms for leveraging offline data in MAB problems:
-
Offline Policy Learning and Inference by Matrix Completion: This approach uses matrix completion techniques to infer the offline data's underlying reward structure, which is then used to guide exploration in the online setting.
-
Hellinger UCB: A Novel Algorithm for Stochastic Multi-Armed Bandits: This algorithm incorporates a new way of balancing exploration and exploitation that takes into account the distribution shift between the offline and online environments.
The authors also provide theoretical regret bounds for these algorithms, showing that they can outperform traditional MAB approaches in the presence of biased offline data. They validate these theoretical results through experiments on synthetic and real-world datasets, including recommender system benchmarks and reinforcement learning tasks.
Critical Analysis
The paper makes a valuable contribution by addressing the practical challenge of leveraging historical data in MAB problems, where the data may not be perfectly representative of the current environment. The proposed algorithms provide a principled way to incorporate this offline information to improve online decision-making.
However, the authors acknowledge that their approaches rely on certain assumptions, such as the availability of offline data that is "reasonably" informative about the true reward distribution. In real-world scenarios, the quality and relevance of the offline data may be more uncertain, which could limit the effectiveness of these algorithms.
Additionally, the paper does not consider the potential for the offline data to contain biases or noise that could negatively impact the online performance if not properly accounted for. Further research may be needed to develop more robust techniques for handling noisy or adversarial offline data in MAB settings.
Conclusion
This paper presents novel algorithms that leverage biased offline data to enhance the performance of multi-armed bandit algorithms. By incorporating information from historical data, these approaches can improve the exploration-exploitation tradeoff and lead to better overall decision-making.
The theoretical and empirical results demonstrate the potential benefits of this approach, which could have significant practical implications in areas like recommender systems, online advertising, and various reinforcement learning applications. As the availability of historical data continues to grow, techniques for effectively leveraging such information will become increasingly important for building intelligent decision-making systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Leveraging Offline Data in Linear Latent Bandits
Chinmaya Kausik, Kevin Tan, Ambuj Tewari
0
0
Sequential decision-making domains such as recommender systems, healthcare and education often have unobserved heterogeneity in the population that can be modeled using latent bandits $-$ a framework where an unobserved latent state determines the model for a trajectory. While the latent bandit framework is compelling, the extent of its generality is unclear. We first address this by establishing a de Finetti theorem for decision processes, and show that $textit{every}$ exchangeable and coherent stateless decision process is a latent bandit. The latent bandit framework lends itself particularly well to online learning with offline datasets, a problem of growing interest in sequential decision-making. One can leverage offline latent bandit data to learn a complex model for each latent state, so that an agent can simply learn the latent state online to act optimally. We focus on a linear model for a latent bandit with $d_A$-dimensional actions, where the latent states lie in an unknown $d_K$-dimensional subspace for $d_K ll d_A$. We present SOLD, a novel principled method to learn this subspace from short offline trajectories with guarantees. We then provide two methods to leverage this subspace online: LOCAL-UCB and ProBALL-UCB. We demonstrate that LOCAL-UCB enjoys $tilde O(min(d_Asqrt{T}, d_Ksqrt{T}(1+sqrt{d_AT/d_KN})))$ regret guarantees, where the effective dimension is lower when the size $N$ of the offline dataset is larger. ProBALL-UCB enjoys a slightly weaker guarantee, but is more practical and computationally efficient. Finally, we establish the efficacy of our methods using experiments on both synthetic data and real-life movie recommendation data from MovieLens.
5/28/2024
🚀
BanditQ: Fair Bandits with Guaranteed Rewards
Abhishek Sinha
0
0
Classic no-regret multi-armed bandit algorithms, including the Upper Confidence Bound (UCB), Hedge, and EXP3, are inherently unfair by design. Their unfairness stems from their objective of playing the most rewarding arm as frequently as possible while ignoring the rest. In this paper, we consider a fair prediction problem in the stochastic setting with a guaranteed minimum rate of accrual of rewards for each arm. We study the problem in both full-information and bandit feedback settings. Combining queueing-theoretic techniques with adversarial bandits, we propose a new online policy, called BanditQ, that achieves the target reward rates while conceding a regret and target rate violation penalty of at most $O(T^{frac{3}{4}}).$ The regret bound in the full-information setting can be further improved to $O(sqrt{T})$ under either a monotonicity assumption or when considering time-averaged regret. The proposed policy is efficient and admits a black-box reduction from the fair prediction problem to the standard adversarial MAB problem. The analysis of the BanditQ policy involves a new self-bounding inequality, which might be of independent interest.
5/14/2024
Data-Driven Upper Confidence Bounds with Near-Optimal Regret for Heavy-Tailed Bandits
Ambrus Tam'as, Szabolcs Szentp'eteri, Bal'azs Csan'ad Cs'aji
0
0
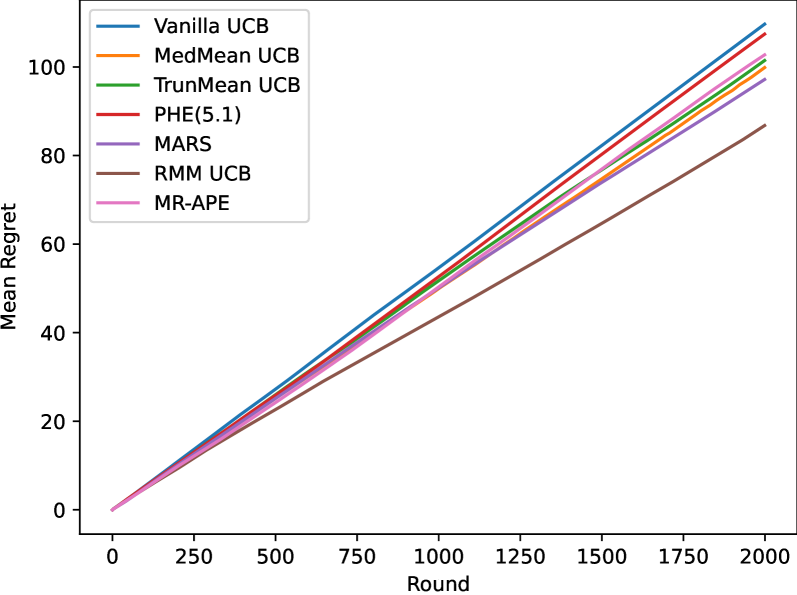
Stochastic multi-armed bandits (MABs) provide a fundamental reinforcement learning model to study sequential decision making in uncertain environments. The upper confidence bounds (UCB) algorithm gave birth to the renaissance of bandit algorithms, as it achieves near-optimal regret rates under various moment assumptions. Up until recently most UCB methods relied on concentration inequalities leading to confidence bounds which depend on moment parameters, such as the variance proxy, that are usually unknown in practice. In this paper, we propose a new distribution-free, data-driven UCB algorithm for symmetric reward distributions, which needs no moment information. The key idea is to combine a refined, one-sided version of the recently developed resampled median-of-means (RMM) method with UCB. We prove a near-optimal regret bound for the proposed anytime, parameter-free RMM-UCB method, even for heavy-tailed distributions.
6/11/2024
📊
Efficient Policy Evaluation with Offline Data Informed Behavior Policy Design
Shuze Liu, Shangtong Zhang
0
0
Most reinforcement learning practitioners evaluate their policies with online Monte Carlo estimators for either hyperparameter tuning or testing different algorithmic design choices, where the policy is repeatedly executed in the environment to get the average outcome. Such massive interactions with the environment are prohibitive in many scenarios. In this paper, we propose novel methods that improve the data efficiency of online Monte Carlo estimators while maintaining their unbiasedness. We first propose a tailored closed-form behavior policy that provably reduces the variance of an online Monte Carlo estimator. We then design efficient algorithms to learn this closed-form behavior policy from previously collected offline data. Theoretical analysis is provided to characterize how the behavior policy learning error affects the amount of reduced variance. Compared with previous works, our method achieves better empirical performance in a broader set of environments, with fewer requirements for offline data.
6/3/2024