Online Policy Learning and Inference by Matrix Completion
2404.17398
0
0
🤯
Abstract
Making online decisions can be challenging when features are sparse and orthogonal to historical ones, especially when the optimal policy is learned through collaborative filtering. We formulate the problem as a matrix completion bandit (MCB), where the expected reward under each arm is characterized by an unknown low-rank matrix. The $epsilon$-greedy bandit and the online gradient descent algorithm are explored. Policy learning and regret performance are studied under a specific schedule for exploration probabilities and step sizes. A faster decaying exploration probability yields smaller regret but learns the optimal policy less accurately. We investigate an online debiasing method based on inverse propensity weighting (IPW) and a general framework for online policy inference. The IPW-based estimators are asymptotically normal under mild arm-optimality conditions. Numerical simulations corroborate our theoretical findings. Our methods are applied to the San Francisco parking pricing project data, revealing intriguing discoveries and outperforming the benchmark policy.
Create account to get full access
Overview
- Online decision-making can be challenging when features are sparse and unrelated to historical data
- The optimal policy is often learned through collaborative filtering
- The problem is formulated as a matrix completion bandit (MCB), where the expected reward under each option is characterized by an unknown low-rank matrix
- The researchers explore the ε-greedy bandit and online gradient descent algorithms, studying policy learning and regret performance under different exploration probabilities and step sizes
- An online debiasing method based on inverse propensity weighting (IPW) and a general framework for online policy inference are investigated
- The methods are applied to the San Francisco parking pricing project data, revealing insights and outperforming the benchmark policy
Plain English Explanation
Making good decisions online can be tricky when the available information is limited and unrelated to past data. In this research, the authors tackle this challenge by framing the problem as a matrix completion bandit. This means they model the expected reward for each possible decision as an unknown low-rank matrix, which they then try to learn.
The researchers explore two algorithms: the ε-greedy bandit and online gradient descent. These methods balance exploration (trying new options) and exploitation (using the best known option) in different ways, and the researchers study how the choice of exploration probability and step size affects the learning of the optimal policy and the overall regret (the difference between the rewards obtained and the maximum possible reward).
The paper also introduces an online debiasing method based on inverse propensity weighting. This helps correct for biases that can arise when the data used to learn the policy doesn't fully represent the true underlying distribution.
The researchers apply their methods to data from a San Francisco parking pricing project, and find that their approaches outperform the benchmark policy, providing useful insights into the problem.
Technical Explanation
The authors formulate the problem as a matrix completion bandit (MCB), where the expected reward under each arm (decision option) is characterized by an unknown low-rank matrix. This allows them to capture the sparse and orthogonal nature of the features, which can be challenging for traditional approaches.
They explore two algorithms: the ε-greedy bandit and the online gradient descent algorithm. The ε-greedy bandit balances exploration and exploitation by randomly selecting a new option with probability ε and choosing the currently best option with probability 1-ε. The online gradient descent algorithm updates the policy parameters using gradient descent on the observed rewards.
The researchers study the policy learning and regret performance of these algorithms under different schedules for the exploration probability ε and the step size. They find that a faster decaying exploration probability yields smaller regret but learns the optimal policy less accurately.
The paper also introduces an online debiasing method based on inverse propensity weighting (IPW). This corrects for biases in the data used to learn the policy, helping the algorithms converge to the true optimal policy. The IPW-based estimators are shown to be asymptotically normal under mild arm-optimality conditions.
The methods are evaluated on the San Francisco parking pricing project data, and the results reveal interesting insights and outperform the benchmark policy. The researchers demonstrate the practical applicability of their approach to real-world decision-making problems.
Critical Analysis
The paper presents a novel and theoretically sound approach to online decision-making in the face of sparse and orthogonal features. The use of the matrix completion bandit framework and the exploration of different algorithms, including the ε-greedy bandit and online gradient descent, provide a comprehensive understanding of the problem and the tradeoffs involved.
One potential limitation of the research is the assumption of a low-rank structure for the expected reward matrix. While this assumption may hold in certain applications, it may not be universally applicable, and relaxing this assumption could be an area for further investigation.
Additionally, the paper focuses on the asymptotic properties of the IPW-based estimators, but does not provide a detailed analysis of the finite-sample performance. Exploring the finite-sample behavior and the practical implications of the debiasing method could be an interesting direction for future work.
The application of the methods to the San Francisco parking pricing project data is a strength of the paper, as it demonstrates the real-world relevance and potential impact of the research. However, it would be valuable to see the methods applied to a wider range of decision-making problems to further validate their generalizability.
Overall, this paper makes a significant contribution to the field of online decision-making, particularly in situations where historical data may not be directly relevant to the current problem. The introduction of the matrix completion bandit framework and the exploration of various algorithms, along with the debiasing method, provide a solid foundation for further research and practical applications.
Conclusion
This research tackles the challenge of online decision-making when features are sparse and orthogonal to historical data, a common occurrence in many real-world scenarios. By formulating the problem as a matrix completion bandit, the authors develop a comprehensive framework for learning the optimal policy through collaborative filtering.
The exploration of the ε-greedy bandit and online gradient descent algorithms, along with the introduction of an online debiasing method based on inverse propensity weighting, provides valuable insights into the tradeoffs between exploration, exploitation, and bias correction. The application of these methods to the San Francisco parking pricing project data demonstrates their practical relevance and potential to outperform benchmark policies.
Overall, this research contributes to the growing body of work on contrastive UCB, trajectory-oriented policy optimization, and privacy-constrained policies, pushing the boundaries of online decision-making in the face of sparse and orthogonal data. The insights and methods presented in this paper have the potential to significantly impact a wide range of practical applications, from e-commerce to public policy.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
$epsilon$-Policy Gradient for Online Pricing
Lukasz Szpruch, Tanut Treetanthiploet, Yufei Zhang
0
0
Combining model-based and model-free reinforcement learning approaches, this paper proposes and analyzes an $epsilon$-policy gradient algorithm for the online pricing learning task. The algorithm extends $epsilon$-greedy algorithm by replacing greedy exploitation with gradient descent step and facilitates learning via model inference. We optimize the regret of the proposed algorithm by quantifying the exploration cost in terms of the exploration probability $epsilon$ and the exploitation cost in terms of the gradient descent optimization and gradient estimation errors. The algorithm achieves an expected regret of order $mathcal{O}(sqrt{T})$ (up to a logarithmic factor) over $T$ trials.
5/7/2024
Leveraging (Biased) Information: Multi-armed Bandits with Offline Data
Wang Chi Cheung, Lixing Lyu
0
0
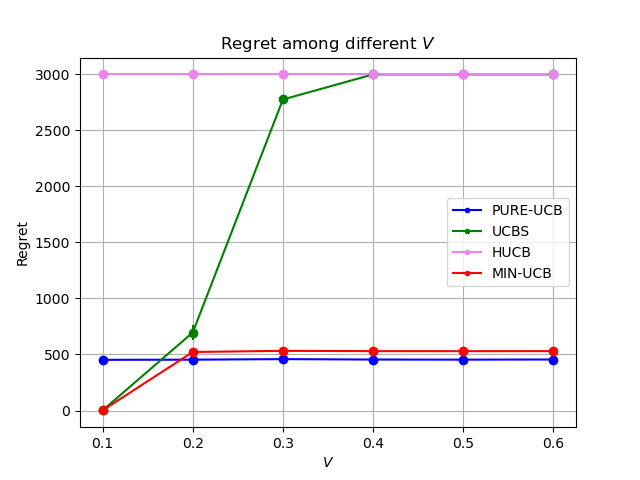
We leverage offline data to facilitate online learning in stochastic multi-armed bandits. The probability distributions that govern the offline data and the online rewards can be different. Without any non-trivial upper bound on their difference, we show that no non-anticipatory policy can outperform the UCB policy by (Auer et al. 2002), even in the presence of offline data. In complement, we propose an online policy MIN-UCB, which outperforms UCB when a non-trivial upper bound is given. MIN-UCB adaptively chooses to utilize the offline data when they are deemed informative, and to ignore them otherwise. MIN-UCB is shown to be tight in terms of both instance independent and dependent regret bounds. Finally, we corroborate the theoretical results with numerical experiments.
5/7/2024
Multi-Armed Bandits with Network Interference
Abhineet Agarwal, Anish Agarwal, Lorenzo Masoero, Justin Whitehouse
0
0
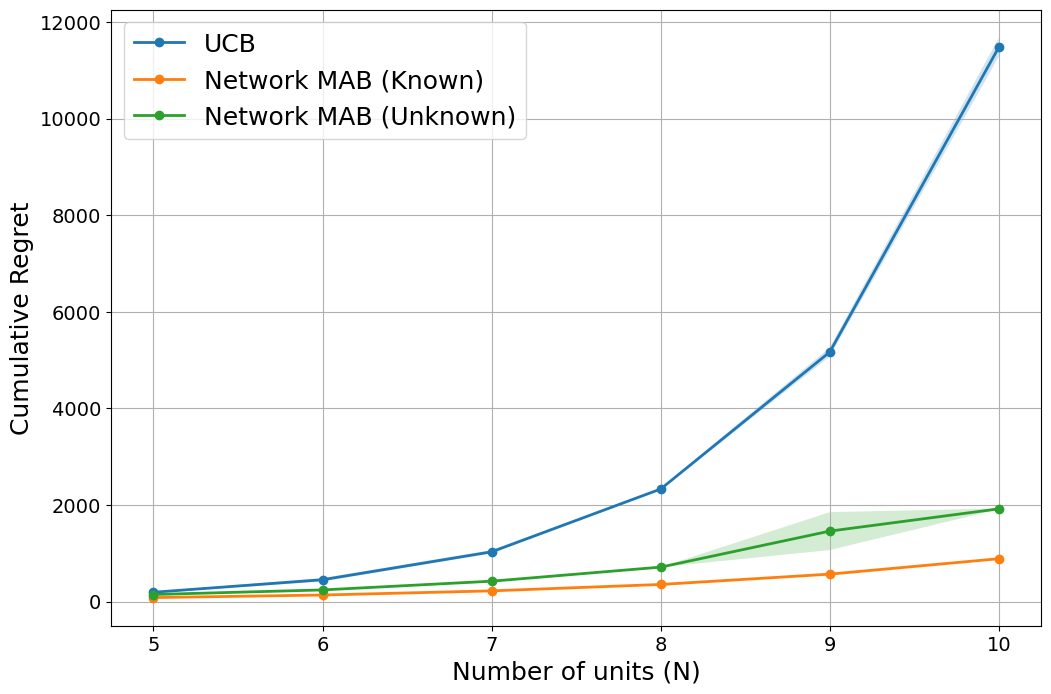
Online experimentation with interference is a common challenge in modern applications such as e-commerce and adaptive clinical trials in medicine. For example, in online marketplaces, the revenue of a good depends on discounts applied to competing goods. Statistical inference with interference is widely studied in the offline setting, but far less is known about how to adaptively assign treatments to minimize regret. We address this gap by studying a multi-armed bandit (MAB) problem where a learner (e-commerce platform) sequentially assigns one of possible $mathcal{A}$ actions (discounts) to $N$ units (goods) over $T$ rounds to minimize regret (maximize revenue). Unlike traditional MAB problems, the reward of each unit depends on the treatments assigned to other units, i.e., there is interference across the underlying network of units. With $mathcal{A}$ actions and $N$ units, minimizing regret is combinatorially difficult since the action space grows as $mathcal{A}^N$. To overcome this issue, we study a sparse network interference model, where the reward of a unit is only affected by the treatments assigned to $s$ neighboring units. We use tools from discrete Fourier analysis to develop a sparse linear representation of the unit-specific reward $r_n: [mathcal{A}]^N rightarrow mathbb{R} $, and propose simple, linear regression-based algorithms to minimize regret. Importantly, our algorithms achieve provably low regret both when the learner observes the interference neighborhood for all units and when it is unknown. This significantly generalizes other works on this topic which impose strict conditions on the strength of interference on a known network, and also compare regret to a markedly weaker optimal action. Empirically, we corroborate our theoretical findings via numerical simulations.
5/30/2024
🔎
Matrix Low-Rank Approximation For Policy Gradient Methods
Sergio Rozada, Antonio G. Marques
0
0
Estimating a policy that maps states to actions is a central problem in reinforcement learning. Traditionally, policies are inferred from the so called value functions (VFs), but exact VF computation suffers from the curse of dimensionality. Policy gradient (PG) methods bypass this by learning directly a parametric stochastic policy. Typically, the parameters of the policy are estimated using neural networks (NNs) tuned via stochastic gradient descent. However, finding adequate NN architectures can be challenging, and convergence issues are common as well. In this paper, we put forth low-rank matrix-based models to estimate efficiently the parameters of PG algorithms. We collect the parameters of the stochastic policy into a matrix, and then, we leverage matrix-completion techniques to promote (enforce) low rank. We demonstrate via numerical studies how low-rank matrix-based policy models reduce the computational and sample complexities relative to NN models, while achieving a similar aggregated reward.
5/29/2024