Leveraging Interpolation Models and Error Bounds for Verifiable Scientific Machine Learning
2404.03586
0
0

Abstract
Effective verification and validation techniques for modern scientific machine learning workflows are challenging to devise. Statistical methods are abundant and easily deployed, but often rely on speculative assumptions about the data and methods involved. Error bounds for classical interpolation techniques can provide mathematically rigorous estimates of accuracy, but often are difficult or impractical to determine computationally. In this work, we present a best-of-both-worlds approach to verifiable scientific machine learning by demonstrating that (1) multiple standard interpolation techniques have informative error bounds that can be computed or estimated efficiently; (2) comparative performance among distinct interpolants can aid in validation goals; (3) deploying interpolation methods on latent spaces generated by deep learning techniques enables some interpretability for black-box models. We present a detailed case study of our approach for predicting lift-drag ratios from airfoil images. Code developed for this work is available in a public Github repository.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This research paper presents a novel approach to leveraging interpolation models and error bounds for verifiable scientific machine learning.
- The researchers explore the use of mesh-based interpolation and the Delaunay triangulation method to improve the reliability and interpretability of machine learning models in scientific applications.
- They introduce a framework for incorporating error bounds into the model training and prediction processes, enabling users to quantify the uncertainty associated with the model's outputs.
Plain English Explanation
Imagine you're a scientist trying to understand a complex phenomenon, like the behavior of a chemical reaction or the movement of ocean currents. You might collect data from experiments or observations, and then use machine learning algorithms to build a model that can predict the behavior of the system.
However, traditional machine learning models can sometimes be like black boxes - it's not always clear how they arrive at their predictions, or how reliable those predictions are. This is where the research in this paper comes in.
The researchers propose using a special type of machine learning model called an "interpolation model." Instead of just trying to fit a curve to your data, an interpolation model tries to capture the underlying structure of the system, and make predictions based on that. The researchers use a technique called "Delaunay triangulation" to create a mesh-like structure that can represent the relationships between the different parts of the system.
But that's not all - the researchers also introduce a way to add "error bounds" to the model. This means that instead of just giving you a single prediction, the model can also tell you how certain it is about that prediction. So you don't just get a number, you also get a range of values that the true answer is likely to fall within.
This is really important in scientific applications, where you need to be able to trust the predictions you're making. If you're a doctor trying to diagnose a patient, or an engineer designing a new product, you need to know how reliable the model's predictions are, and how much uncertainty is involved.
By incorporating these error bounds, the researchers hope to create machine learning models that are more transparent, interpretable, and trustworthy - helping scientists and researchers to make more informed decisions and draw more reliable conclusions from their data.
Technical Explanation
The paper introduces a framework for leveraging interpolation models and error bounds to improve the reliability and interpretability of scientific machine learning.
The researchers focus on mesh-based interpolation, specifically the Delaunay triangulation method, to capture the underlying structure of the system being modeled. Delaunay triangulation is a technique for dividing a space into a set of connected triangles, with each triangle representing a local region of the system.
By using this mesh-based approach, the researchers can create models that are more faithful to the underlying physics or dynamics of the system, rather than just trying to fit a curve to the data. This allows for better generalization and more accurate predictions, especially in regions of the input space that are sparsely sampled.
To quantify the uncertainty associated with the model's predictions, the researchers incorporate error bounds into the training and prediction processes. They use techniques like interval arithmetic and Taylor series expansions to propagate error bounds through the model, providing users with not just a point estimate, but a range of values that the true output is likely to fall within.
This framework for verifiable scientific machine learning has several key advantages:
- Improved interpretability: The mesh-based structure of the interpolation model makes it easier to understand the relationships and dependencies within the system being modeled.
- Quantified uncertainty: The error bounds provide users with a clear sense of the reliability and trustworthiness of the model's predictions.
- Enhanced decision-making: By understanding the uncertainty associated with model outputs, users can make more informed and risk-aware decisions in scientific and engineering applications.
The paper presents several case studies and experiments demonstrating the effectiveness of this approach, including applications in physics, chemistry, and biology. The results show that the interpolation models with error bounds can outperform traditional machine learning methods in terms of accuracy, robustness, and interpretability.
Critical Analysis
The researchers have made a compelling case for the importance of incorporating error bounds and interpretable models into scientific machine learning. By leveraging mesh-based interpolation and Delaunay triangulation, they have developed a framework that can capture the underlying structure of complex systems more faithfully than traditional black-box models.
One potential limitation of the approach is the computational complexity associated with the mesh-based interpolation and error propagation. As the dimensionality of the input space increases, the complexity of the Delaunay triangulation and the error bound calculations can become prohibitively high. The researchers acknowledge this challenge and suggest potential avenues for improving the scalability of the framework.
Additionally, while the case studies presented in the paper demonstrate the effectiveness of the approach in specific domains, it would be valuable to see how the framework performs across a wider range of scientific and engineering applications. Further research could explore the generalizability of the method and its ability to handle diverse data types and problem formulations.
Another area for potential improvement is the integration of the framework with existing machine learning workflows and toolkits. Providing users with seamless ways to incorporate the interpolation models and error bounds into their existing analysis pipelines could enhance the practical adoption and impact of this research.
Conclusion
This research paper presents a novel approach to leveraging interpolation models and error bounds for verifiable scientific machine learning. By using mesh-based interpolation and Delaunay triangulation, the researchers have developed a framework that can capture the underlying structure of complex systems more faithfully than traditional machine learning models.
The incorporation of error bounds into the model training and prediction processes allows users to quantify the uncertainty associated with the model's outputs, which is crucial for making informed and risk-aware decisions in scientific and engineering applications.
The potential benefits of this approach include improved interpretability, enhanced decision-making, and more reliable predictions, particularly in areas of the input space that are sparsely sampled. While the framework faces some computational challenges as the dimensionality of the problem increases, the researchers have identified promising avenues for further research and development.
Overall, this work represents an important step towards developing more transparent, trustworthy, and verifiable machine learning models for scientific and engineering applications, with significant implications for fields ranging from healthcare to environmental science.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Analytical results for uncertainty propagation through trained machine learning regression models
Andrew Thompson
0
0
Machine learning (ML) models are increasingly being used in metrology applications. However, for ML models to be credible in a metrology context they should be accompanied by principled uncertainty quantification. This paper addresses the challenge of uncertainty propagation through trained/fixed machine learning (ML) regression models. Analytical expressions for the mean and variance of the model output are obtained/presented for certain input data distributions and for a variety of ML models. Our results cover several popular ML models including linear regression, penalised linear regression, kernel ridge regression, Gaussian Processes (GPs), support vector machines (SVMs) and relevance vector machines (RVMs). We present numerical experiments in which we validate our methods and compare them with a Monte Carlo approach from a computational efficiency point of view. We also illustrate our methods in the context of a metrology application, namely modelling the state-of-health of lithium-ion cells based upon Electrical Impedance Spectroscopy (EIS) data
5/9/2024
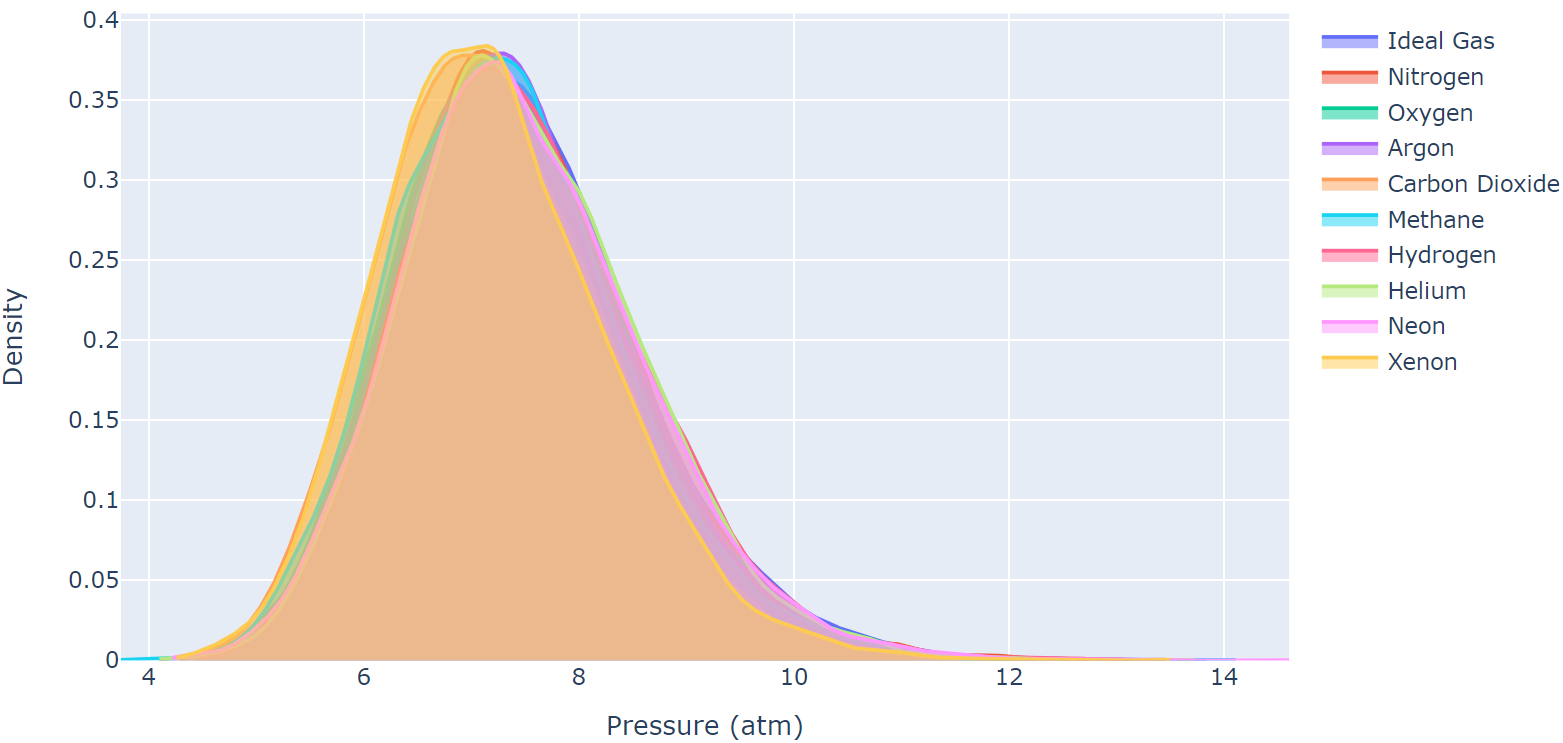
Quantifying Distribution Shifts and Uncertainties for Enhanced Model Robustness in Machine Learning Applications
Vegard Flovik
0
0
Distribution shifts, where statistical properties differ between training and test datasets, present a significant challenge in real-world machine learning applications where they directly impact model generalization and robustness. In this study, we explore model adaptation and generalization by utilizing synthetic data to systematically address distributional disparities. Our investigation aims to identify the prerequisites for successful model adaptation across diverse data distributions, while quantifying the associated uncertainties. Specifically, we generate synthetic data using the Van der Waals equation for gases and employ quantitative measures such as Kullback-Leibler divergence, Jensen-Shannon distance, and Mahalanobis distance to assess data similarity. These metrics en able us to evaluate both model accuracy and quantify the associated uncertainty in predictions arising from data distribution shifts. Our findings suggest that utilizing statistical measures, such as the Mahalanobis distance, to determine whether model predictions fall within the low-error interpolation regime or the high-error extrapolation regime provides a complementary method for assessing distribution shift and model uncertainty. These insights hold significant value for enhancing model robustness and generalization, essential for the successful deployment of machine learning applications in real-world scenarios.
5/6/2024
🤯
Valid Inference for Machine Learning Model Parameters
Neil Dey, Jonathan P. Williams
0
0
The parameters of a machine learning model are typically learned by minimizing a loss function on a set of training data. However, this can come with the risk of overtraining; in order for the model to generalize well, it is of great importance that we are able to find the optimal parameter for the model on the entire population -- not only on the given training sample. In this paper, we construct valid confidence sets for this optimal parameter of a machine learning model, which can be generated using only the training data without any knowledge of the population. We then show that studying the distribution of this confidence set allows us to assign a notion of confidence to arbitrary regions of the parameter space, and we demonstrate that this distribution can be well-approximated using bootstrapping techniques.
5/13/2024
🤔
Understanding LLMs Requires More Than Statistical Generalization
Patrik Reizinger, Szilvia Ujv'ary, Anna M'esz'aros, Anna Kerekes, Wieland Brendel, Ferenc Husz'ar
0
0
The last decade has seen blossoming research in deep learning theory attempting to answer, Why does deep learning generalize? A powerful shift in perspective precipitated this progress: the study of overparametrized models in the interpolation regime. In this paper, we argue that another perspective shift is due, since some of the desirable qualities of LLMs are not a consequence of good statistical generalization and require a separate theoretical explanation. Our core argument relies on the observation that AR probabilistic models are inherently non-identifiable: models zero or near-zero KL divergence apart -- thus, equivalent test loss -- can exhibit markedly different behaviors. We support our position with mathematical examples and empirical observations, illustrating why non-identifiability has practical relevance through three case studies: (1) the non-identifiability of zero-shot rule extrapolation; (2) the approximate non-identifiability of in-context learning; and (3) the non-identifiability of fine-tunability. We review promising research directions focusing on LLM-relevant generalization measures, transferability, and inductive biases.
5/6/2024