Valid Inference for Machine Learning Model Parameters
2302.10840
0
0
🤯
Abstract
The parameters of a machine learning model are typically learned by minimizing a loss function on a set of training data. However, this can come with the risk of overtraining; in order for the model to generalize well, it is of great importance that we are able to find the optimal parameter for the model on the entire population -- not only on the given training sample. In this paper, we construct valid confidence sets for this optimal parameter of a machine learning model, which can be generated using only the training data without any knowledge of the population. We then show that studying the distribution of this confidence set allows us to assign a notion of confidence to arbitrary regions of the parameter space, and we demonstrate that this distribution can be well-approximated using bootstrapping techniques.
Create account to get full access
Overview
- Machine learning models are typically trained by minimizing a loss function on a set of training data
- This can lead to overfitting, where the model performs well on the training data but struggles to generalize to new, unseen data
- It is important to find the optimal parameters for the model that work well on the entire population, not just the training sample
- This paper constructs valid confidence sets for the optimal model parameters using only the training data, without any knowledge of the larger population
Plain English Explanation
Training a machine learning model typically involves finding the best set of parameters that minimize the error on a given set of training data. However, this can sometimes lead to the model becoming too specialized to the training data, a phenomenon known as overfitting. For the model to perform well on new, unseen data, it's crucial to find the optimal parameters that work well for the entire population, not just the specific training sample.
This paper presents a way to construct confidence sets for the optimal model parameters using only the training data, without any additional information about the larger population. By studying the distribution of these confidence sets, the researchers show that it's possible to assign a level of confidence to different regions of the parameter space, even for complex machine learning models. This can be achieved using bootstrapping techniques, which provide a way to estimate the uncertainty in the model's parameters.
Technical Explanation
The paper presents a method for constructing valid confidence sets for the optimal parameters of a machine learning model. This is done without any knowledge of the underlying population, using only the training data.
The key insight is that by studying the distribution of these confidence sets, the researchers can assign a notion of confidence to arbitrary regions of the parameter space. This allows them to identify the most promising areas of the parameter space, even for complex models with high-dimensional parameter spaces.
The method is demonstrated using bootstrapping techniques, which provide a way to approximate the distribution of the confidence sets. The researchers show that this approach can be effectively used to quantify the uncertainty in the model's parameters and guide the optimization process.
Critical Analysis
The paper presents a compelling approach for addressing the challenge of overfitting in machine learning models. By constructing valid confidence sets for the optimal model parameters, the researchers provide a way to quantify the uncertainty in the model's parameters and identify the most promising regions of the parameter space.
One potential limitation of the approach is that it relies on the assumption that the training data is representative of the larger population. If the training data is biased or does not adequately capture the true distribution of the population, the confidence sets may not accurately reflect the optimal parameters for the population.
Additionally, the paper does not address the computational complexity of the bootstrapping techniques used to approximate the distribution of the confidence sets. For large-scale models with high-dimensional parameter spaces, this process may become computationally intensive and could limit the practical applicability of the method.
Overall, the research presented in this paper provides a valuable contribution to the field of machine learning, offering a novel approach for addressing the challenge of overfitting and quantifying the uncertainty in model parameters. Further research may be needed to explore the limitations of the method and investigate ways to improve its computational efficiency.
Conclusion
This paper presents a method for constructing valid confidence sets for the optimal parameters of a machine learning model, using only the training data without any knowledge of the underlying population. By studying the distribution of these confidence sets, the researchers demonstrate a way to assign a notion of confidence to arbitrary regions of the parameter space, which can be used to guide the optimization process and improve the generalization performance of the model.
The approach leverages bootstrapping techniques to approximate the distribution of the confidence sets, providing a practical way to quantify the uncertainty in the model's parameters. While the method has some potential limitations, it represents a significant advancement in the field of machine learning, offering a new way to address the challenge of overfitting and improve the reliability of complex models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Confidence Is All You Need for MI Attacks
Abhishek Sinha, Himanshi Tibrewal, Mansi Gupta, Nikhar Waghela, Shivank Garg
0
0
In this evolving era of machine learning security, membership inference attacks have emerged as a potent threat to the confidentiality of sensitive data. In this attack, adversaries aim to determine whether a particular point was used during the training of a target model. This paper proposes a new method to gauge a data point's membership in a model's training set. Instead of correlating loss with membership, as is traditionally done, we have leveraged the fact that training examples generally exhibit higher confidence values when classified into their actual class. During training, the model is essentially being 'fit' to the training data and might face particular difficulties in generalization to unseen data. This asymmetry leads to the model achieving higher confidence on the training data as it exploits the specific patterns and noise present in the training data. Our proposed approach leverages the confidence values generated by the machine learning model. These confidence values provide a probabilistic measure of the model's certainty in its predictions and can further be used to infer the membership of a given data point. Additionally, we also introduce another variant of our method that allows us to carry out this attack without knowing the ground truth(true class) of a given data point, thus offering an edge over existing label-dependent attack methods.
6/21/2024
🔮
Online Calibrated and Conformal Prediction Improves Bayesian Optimization
Shachi Deshpande, Charles Marx, Volodymyr Kuleshov
0
0
Accurate uncertainty estimates are important in sequential model-based decision-making tasks such as Bayesian optimization. However, these estimates can be imperfect if the data violates assumptions made by the model (e.g., Gaussianity). This paper studies which uncertainties are needed in model-based decision-making and in Bayesian optimization, and argues that uncertainties can benefit from calibration -- i.e., an 80% predictive interval should contain the true outcome 80% of the time. Maintaining calibration, however, can be challenging when the data is non-stationary and depends on our actions. We propose using simple algorithms based on online learning to provably maintain calibration on non-i.i.d. data, and we show how to integrate these algorithms in Bayesian optimization with minimal overhead. Empirically, we find that calibrated Bayesian optimization converges to better optima in fewer steps, and we demonstrate improved performance on standard benchmark functions and hyperparameter optimization tasks.
6/27/2024
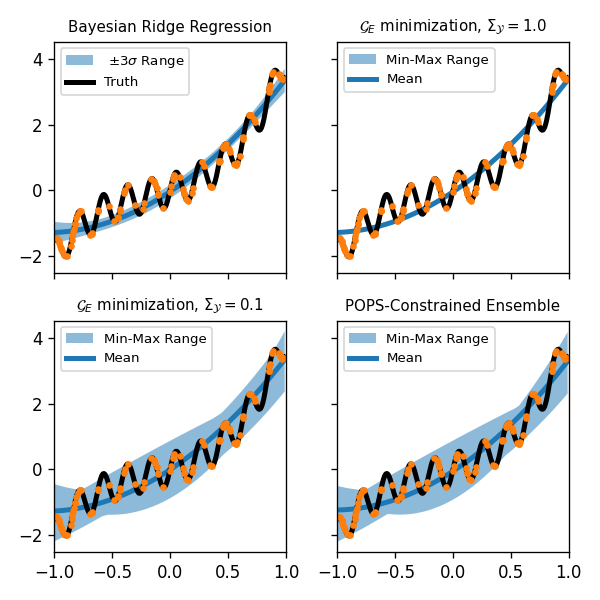
Misspecification uncertainties in near-deterministic regression
Thomas D Swinburne, Danny Perez
0
0
Bayesian regression determines model parameters by minimizing the expected loss, an upper bound to the true generalization error. However, the loss ignores misspecification, where models are imperfect. Parameter uncertainties from Bayesian regression are thus significantly underestimated and vanish in the large data limit. This is particularly problematic when building models of low- noise, or near-deterministic, calculations, as the main source of uncertainty is neglected. We analyze the generalization error of misspecified, near-deterministic surrogate models, a regime of broad relevance in science and engineering. We show posterior distributions must cover every training point to avoid a divergent generalization error and design an ansatz that respects this constraint, which for linear models incurs minimal overhead. This is demonstrated on model problems before application to thousand dimensional datasets in atomistic machine learning. Our efficient misspecification-aware scheme gives accurate prediction and bounding of test errors where existing schemes fail, allowing this important source of uncertainty to be incorporated in computational workflows.
5/8/2024
Bayesian Inference for Consistent Predictions in Overparameterized Nonlinear Regression
Tomoya Wakayama
0
0
The remarkable generalization performance of large-scale models has been challenging the conventional wisdom of the statistical learning theory. Although recent theoretical studies have shed light on this behavior in linear models and nonlinear classifiers, a comprehensive understanding of overparameterization in nonlinear regression models is still lacking. This study explores the predictive properties of overparameterized nonlinear regression within the Bayesian framework, extending the methodology of the adaptive prior considering the intrinsic spectral structure of the data. Posterior contraction is established for generalized linear and single-neuron models with Lipschitz continuous activation functions, demonstrating the consistency in the predictions of the proposed approach. Moreover, the Bayesian framework enables uncertainty estimation of the predictions. The proposed method was validated via numerical simulations and a real data application, showing its ability to achieve accurate predictions and reliable uncertainty estimates. This work provides a theoretical understanding of the advantages of overparameterization and a principled Bayesian approach to large nonlinear models.
6/18/2024