Leveraging Interpretability in the Transformer to Automate the Proactive Scaling of Cloud Resources

0
Sign in to get full access
Overview
- The paper describes a method to leverage the interpretability of transformers to automatically scale cloud resources proactively.
- The key ideas are using transformer-based models to predict future cloud resource demands and using the interpretability of transformers to guide the scaling decisions.
- The proposed approach aims to improve the efficiency and responsiveness of cloud resource management.
Plain English Explanation
The paper introduces a new way to manage the resources in cloud computing environments. In cloud computing, companies rent computing power, storage, and other resources from large data centers run by cloud providers like Amazon or Google. The amount of resources a company needs can change a lot over time, so the cloud provider has to constantly monitor usage and scale the resources up or down as needed.
The researchers in this paper developed a model using transformers to help the cloud provider predict future resource demands. Transformers are a type of machine learning model that is good at understanding patterns in sequential data, like the way resource usage changes over time. The researchers found that transformers not only make accurate predictions, but they are also interpretable, meaning we can understand how the model is making its predictions.
By understanding how the transformer model works, the researchers can use that information to automatically decide when and how to scale the cloud resources up or down. This helps the cloud provider be more proactive in managing the resources, rather than just reactively responding to changes in demand. The goal is to make cloud computing more efficient and reliable for the companies using the cloud.
Technical Explanation
The core of the proposed approach is using a transformer-based model to predict future cloud resource demands. Transformers are a type of neural network architecture that has shown strong performance on a variety of sequential data tasks, including time-series forecasting.
The researchers train a transformer model on historical cloud resource usage data to learn patterns and trends. They leverage the inherent interpretability of transformers to gain insights into the key factors driving resource usage changes over time. This allows them to identify the most important "triggers" or usage patterns that should prompt the cloud provider to scale resources proactively.
Specifically, the researchers analyze the attention weights within the transformer model to understand which past usage patterns or events are most predictive of future spikes in demand. They then use this information to develop a set of scaling rules that the cloud provider can automatically apply to scale resources up or down in anticipation of demand changes, rather than waiting for resources to become overloaded or underutilized.
The researchers evaluate their approach on real-world cloud usage datasets and find that it can improve the efficiency and responsiveness of cloud resource management compared to traditional reactive scaling approaches.
Critical Analysis
The paper makes a compelling case for the value of interpreting transformer models to enable proactive cloud resource scaling. By understanding the key drivers of resource usage changes, the approach can help cloud providers be more proactive and efficient in managing their infrastructure.
However, the paper does not deeply explore potential limitations or caveats of the approach. For example, the reliance on historical data means the model may struggle to anticipate unprecedented demand spikes or usage patterns not seen in the training data. There are also open questions about how to handle the inherent uncertainty in demand forecasting and how to balance the trade-offs between over-provisioning and under-provisioning resources.
Additionally, the researchers focus solely on CPU and memory usage as the cloud resources to be scaled. In practice, cloud providers need to manage a wide range of resources including storage, networking bandwidth, and specialized hardware accelerators. Extending the approach to handle this broader resource management challenge could be an important area for future work.
Overall, the paper presents a promising direction for improving cloud resource management through the interpretability of transformer models. Further research is needed to fully understand the limits and generalizability of the approach, as well as to integrate it with the complex realities of modern cloud computing environments.
Conclusion
This paper introduces a novel approach to leverage the interpretability of transformer models to enable proactive scaling of cloud resources. By analyzing the internal workings of the transformer, the researchers can identify the key factors driving changes in resource demands over time. They then use this information to automatically scale resources up or down in anticipation of demand changes, rather than just reactively responding to overloaded or underutilized resources.
The proposed approach has the potential to significantly improve the efficiency and responsiveness of cloud resource management, which is increasingly critical as cloud computing becomes more pervasive across industries. While the paper focuses on a specific set of cloud resources, the general principles could likely be extended to handle the broader resource management challenges faced by cloud providers. Further research is needed to fully understand the limits and real-world applicability of this transformer-based approach to cloud auto-scaling.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Leveraging Interpretability in the Transformer to Automate the Proactive Scaling of Cloud Resources
Amadou Ba, Pavithra Harsha, Chitra Subramanian
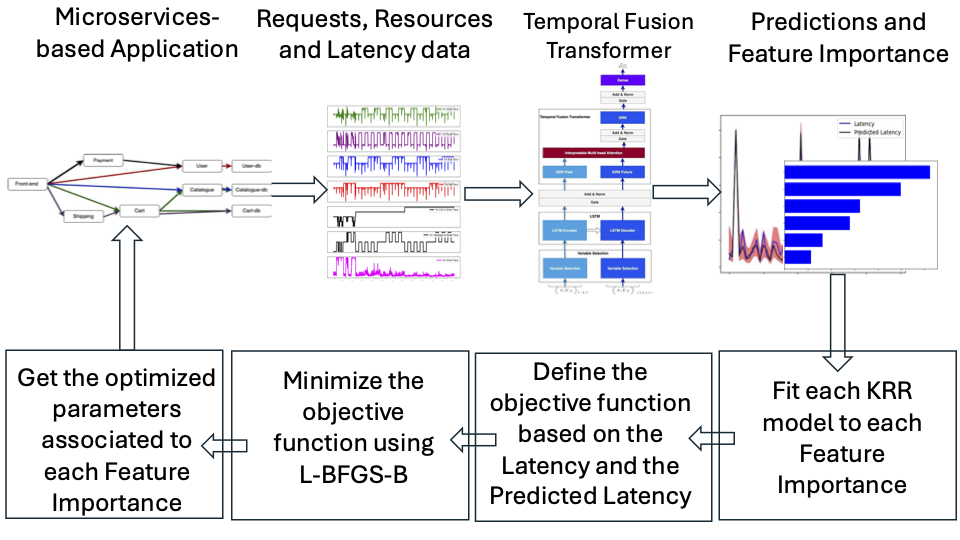
Modern web services adopt cloud-native principles to leverage the advantages of microservices. To consistently guarantee high Quality of Service (QoS) according to Service Level Agreements (SLAs), ensure satisfactory user experiences, and minimize operational costs, each microservice must be provisioned with the right amount of resources. However, accurately provisioning microservices with adequate resources is complex and depends on many factors, including workload intensity and the complex interconnections between microservices. To address this challenge, we develop a model that captures the relationship between an end-to-end latency, requests at the front-end level, and resource utilization. We then use the developed model to predict the end-to-end latency. Our solution leverages the Temporal Fusion Transformer (TFT), an attention-based architecture equipped with interpretability features. When the prediction results indicate SLA non-compliance, we use the feature importance provided by the TFT as covariates in Kernel Ridge Regression (KRR), with the response variable being the desired latency, to learn the parameters associated with the feature importance. These learned parameters reflect the adjustments required to the features to ensure SLA compliance. We demonstrate the merit of our approach with a microservice-based application and provide a roadmap to deployment.
Read more9/6/2024
🔮
0
TempoScale: A Cloud Workloads Prediction Approach Integrating Short-Term and Long-Term Information
Linfeng Wen, Minxian Xu, Adel N. Toosi, Kejiang Ye
Cloud native solutions are widely applied in various fields, placing higher demands on the efficient management and utilization of resource platforms. To achieve the efficiency, load forecasting and elastic scaling have become crucial technologies for dynamically adjusting cloud resources to meet user demands and minimizing resource waste. However, existing prediction-based methods lack comprehensive analysis and integration of load characteristics across different time scales. For instance, long-term trend analysis helps reveal long-term changes in load and resource demand, thereby supporting proactive resource allocation over longer periods, while short-term volatility analysis can examine short-term fluctuations in load and resource demand, providing support for real-time scheduling and rapid response. In response to this, our research introduces TempoScale, which aims to enhance the comprehensive understanding of temporal variations in cloud workloads, enabling more intelligent and adaptive decision-making for elastic scaling. TempoScale utilizes the Complete Ensemble Empirical Mode Decomposition with Adaptive Noise algorithm to decompose time-series load data into multiple Intrinsic Mode Functions (IMF) and a Residual Component (RC). First, we integrate the IMF, which represents both long-term trends and short-term fluctuations, into the time series prediction model to obtain intermediate results. Then, these intermediate results, along with the RC, are transferred into a fully connected layer to obtain the final result. Finally, this result is fed into the resource management system based on Kubernetes for resource scaling. Our proposed approach can reduce the Mean Square Error by 5.80% to 30.43% compared to the baselines, and reduce the average response time by 5.58% to 31.15%.
Read more5/22/2024

0
Multiscale Representation Enhanced Temporal Flow Fusion Model for Long-Term Workload Forecasting
Shiyu Wang, Zhixuan Chu, Yinbo Sun, Yu Liu, Yuliang Guo, Yang Chen, Huiyang Jian, Lintao Ma, Xingyu Lu, Jun Zhou
Accurate workload forecasting is critical for efficient resource management in cloud computing systems, enabling effective scheduling and autoscaling. Despite recent advances with transformer-based forecasting models, challenges remain due to the non-stationary, nonlinear characteristics of workload time series and the long-term dependencies. In particular, inconsistent performance between long-term history and near-term forecasts hinders long-range predictions. This paper proposes a novel framework leveraging self-supervised multiscale representation learning to capture both long-term and near-term workload patterns. The long-term history is encoded through multiscale representations while the near-term observations are modeled via temporal flow fusion. These representations of different scales are fused using an attention mechanism and characterized with normalizing flows to handle non-Gaussian/non-linear distributions of time series. Extensive experiments on 9 benchmarks demonstrate superiority over existing methods.
Read more8/20/2024

0
RATSF: Empowering Customer Service Volume Management through Retrieval-Augmented Time-Series Forecasting
Tianfeng Wang, Gaojie Cui
An efficient customer service management system hinges on precise forecasting of service volume. In this scenario, where data non-stationarity is pronounced, successful forecasting heavily relies on identifying and leveraging similar historical data rather than merely summarizing periodic patterns. Existing models based on RNN or Transformer architectures may struggle with this flexible and effective utilization. To tackle this challenge, we initially developed the Time Series Knowledge Base (TSKB) with an advanced indexing system for efficient historical data retrieval. We also developed the Retrieval Augmented Cross-Attention (RACA) module, a variant of the cross-attention mechanism within Transformer's decoder layers, designed to be seamlessly integrated into the vanilla Transformer architecture to assimilate key historical data segments. The synergy between TSKB and RACA forms the backbone of our Retrieval-Augmented Time Series Forecasting (RATSF) framework. Based on the above two components, RATSF not only significantly enhances performance in the context of Fliggy hotel service volume forecasting but also adapts flexibly to various scenarios and integrates with a multitude of Transformer variants for time-series forecasting. Extensive experimentation has validated the effectiveness and generalizability of this system design across multiple diverse contexts.
Read more6/18/2024