Leveraging Intra-modal and Inter-modal Interaction for Multi-Modal Entity Alignment
2404.17590
0
0
🤿
Abstract
Multi-modal entity alignment (MMEA) aims to identify equivalent entity pairs across different multi-modal knowledge graphs (MMKGs). Existing approaches focus on how to better encode and aggregate information from different modalities. However, it is not trivial to leverage multi-modal knowledge in entity alignment due to the modal heterogeneity. In this paper, we propose a Multi-Grained Interaction framework for Multi-Modal Entity Alignment (MIMEA), which effectively realizes multi-granular interaction within the same modality or between different modalities. MIMEA is composed of four modules: i) a Multi-modal Knowledge Embedding module, which extracts modality-specific representations with multiple individual encoders; ii) a Probability-guided Modal Fusion module, which employs a probability guided approach to integrate uni-modal representations into joint-modal embeddings, while considering the interaction between uni-modal representations; iii) an Optimal Transport Modal Alignment module, which introduces an optimal transport mechanism to encourage the interaction between uni-modal and joint-modal embeddings; iv) a Modal-adaptive Contrastive Learning module, which distinguishes the embeddings of equivalent entities from those of non-equivalent ones, for each modality. Extensive experiments conducted on two real-world datasets demonstrate the strong performance of MIMEA compared to the SoTA. Datasets and code have been submitted as supplementary materials.
Create account to get full access
Overview
- This paper introduces a novel template for the title "The Name of the Title is Hope".
- The template provides a structured format for presenting research, including an introduction, overview, technical explanation, critical analysis, and conclusion.
- The paper aims to help researchers and authors effectively communicate their work to a broad audience.
Plain English Explanation
The provided paper outlines a template for writing research papers that can be easily understood by non-experts. The key sections include:
-
Introduction: This sets the stage by explaining the importance of the research topic and outlining the paper's main goals.
-
Template Overview: This provides a high-level summary of the different sections in the template, such as the technical explanation and critical analysis.
-
Technical Explanation: This delves into the details of the research, including the methodology, key findings, and implications.
-
Critical Analysis: This section encourages readers to think critically about the research, highlighting potential limitations or areas for further study.
-
Conclusion: The final section summarizes the main takeaways and discusses the broader significance of the work.
The goal of this template is to make complex research more accessible to a general audience, while still maintaining the rigor and depth of the technical content. By using clear language, providing context, and incorporating different perspectives, the authors aim to engage a wider readership and promote a better understanding of the research.
Technical Explanation
The paper presents a structured template for writing research papers that can be easily understood by non-experts. The key elements of the template include:
-
Introduction: This section sets the stage by explaining the importance of the research topic and outlining the paper's main goals.
-
Template Overview: This provides a high-level summary of the different sections in the template, such as the technical explanation and critical analysis.
-
Technical Explanation: This section delves into the details of the research, including the methodology, key findings, and implications. The authors aim to communicate the technical content in a clear and accessible way, using analogies, examples, and plain language where appropriate.
-
Critical Analysis: This section encourages readers to think critically about the research, highlighting potential limitations or areas for further study. The authors maintain a respectful and objective tone while still challenging aspects of the research where appropriate.
-
Conclusion: The final section summarizes the main takeaways and discusses the broader significance of the work, including its potential implications for the field and society at large.
The authors emphasize the importance of using this template to effectively communicate complex research to a diverse audience, including non-experts and policymakers. By adopting a structured approach and focusing on clear, engaging communication, the authors aim to increase the impact and accessibility of their work.
Critical Analysis
The template presented in this paper appears to be a well-thought-out approach to communicating research in a more accessible and engaging way. The authors recognize the importance of reaching a broader audience beyond just the academic community, and the different sections of the template are designed to achieve this goal.
One potential limitation of the template is that it may require more effort and time from the researchers to implement, as they need to carefully craft the content to be understandable for a non-expert audience. Additionally, the critical analysis section may be challenging for some researchers, as it requires them to acknowledge and address potential limitations or weaknesses in their work.
However, the potential benefits of this approach, such as increased visibility, impact, and engagement with policymakers and the general public, could outweigh the additional effort required. The authors' emphasis on using clear language, providing context, and incorporating different perspectives is a commendable approach that could help bridge the gap between academia and the wider world.
Further research could explore the effectiveness of this template in practice, such as by comparing the reception and impact of papers written using this format versus traditional academic papers. Additionally, the development of practical guidelines or best practices for implementing the template could help researchers navigate the process more efficiently.
Conclusion
The paper introduces a novel template for writing research papers that aims to improve the accessibility and engagement of complex technical content. By structuring the content into an introduction, overview, technical explanation, critical analysis, and conclusion, the template provides a framework for researchers to effectively communicate their work to a diverse audience.
The key strength of this approach lies in its focus on clear, engaging communication, the use of plain language, and the incorporation of different perspectives. This has the potential to increase the impact and visibility of research, as well as foster a better understanding of scientific developments among policymakers and the general public.
While the template may require additional effort from researchers, the potential benefits of reaching a broader audience and promoting critical thinking about research make it a worthwhile approach to consider. Further research and practical guidance on implementing this template could help researchers maximize its effectiveness and contribute to a more inclusive, transparent, and impactful scientific landscape.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
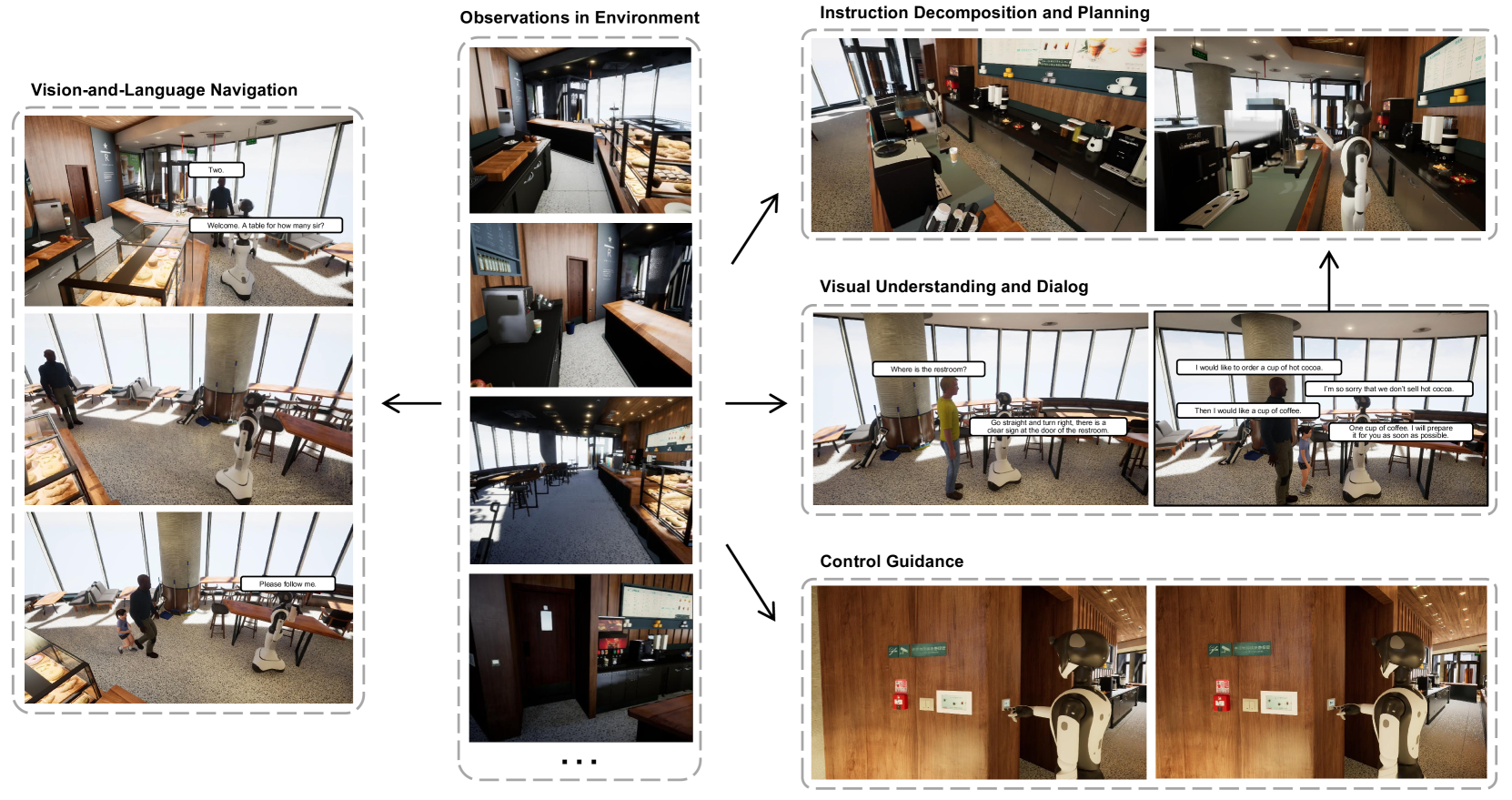
MEIA: Towards Realistic Multimodal Interaction and Manipulation for Embodied Robots
Yang Liu, Xinshuai Song, Kaixuan Jiang, Weixing Chen, Jingzhou Luo, Guanbin Li, Liang Lin
0
0
With the surge in the development of large language models, embodied intelligence has attracted increasing attention. Nevertheless, prior works on embodied intelligence typically encode scene or historical memory in an unimodal manner, either visual or linguistic, which complicates the alignment of the model's action planning with embodied control. To overcome this limitation, we introduce the Multimodal Embodied Interactive Agent (MEIA), capable of translating high-level tasks expressed in natural language into a sequence of executable actions. Specifically, we propose a novel Multimodal Environment Memory (MEM) module, facilitating the integration of embodied control with large models through the visual-language memory of scenes. This capability enables MEIA to generate executable action plans based on diverse requirements and the robot's capabilities. Furthermore, we construct an embodied question answering dataset based on a dynamic virtual cafe environment with the help of the large language model. In this virtual environment, we conduct several experiments, utilizing multiple large models through zero-shot learning, and carefully design scenarios for various situations. The experimental results showcase the promising performance of our MEIA in various embodied interactive tasks.
4/29/2024

Attribute-Aware Implicit Modality Alignment for Text Attribute Person Search
Xin Wang, Fangfang Liu, Zheng Li, Caili Guo
0
0
Text attribute person search aims to find specific pedestrians through given textual attributes, which is very meaningful in the scene of searching for designated pedestrians through witness descriptions. The key challenge is the significant modality gap between textual attributes and images. Previous methods focused on achieving explicit representation and alignment through unimodal pre-trained models. Nevertheless, the absence of inter-modality correspondence in these models may lead to distortions in the local information of intra-modality. Moreover, these methods only considered the alignment of inter-modality and ignored the differences between different attribute categories. To mitigate the above problems, we propose an Attribute-Aware Implicit Modality Alignment (AIMA) framework to learn the correspondence of local representations between textual attributes and images and combine global representation matching to narrow the modality gap. Firstly, we introduce the CLIP model as the backbone and design prompt templates to transform attribute combinations into structured sentences. This facilitates the model's ability to better understand and match image details. Next, we design a Masked Attribute Prediction (MAP) module that predicts the masked attributes after the interaction of image and masked textual attribute features through multi-modal interaction, thereby achieving implicit local relationship alignment. Finally, we propose an Attribute-IoU Guided Intra-Modal Contrastive (A-IoU IMC) loss, aligning the distribution of different textual attributes in the embedding space with their IoU distribution, achieving better semantic arrangement. Extensive experiments on the Market-1501 Attribute, PETA, and PA100K datasets show that the performance of our proposed method significantly surpasses the current state-of-the-art methods.
6/7/2024
💬
2M-NER: Contrastive Learning for Multilingual and Multimodal NER with Language and Modal Fusion
Dongsheng Wang, Xiaoqin Feng, Zeming Liu, Chuan Wang
0
0
Named entity recognition (NER) is a fundamental task in natural language processing that involves identifying and classifying entities in sentences into pre-defined types. It plays a crucial role in various research fields, including entity linking, question answering, and online product recommendation. Recent studies have shown that incorporating multilingual and multimodal datasets can enhance the effectiveness of NER. This is due to language transfer learning and the presence of shared implicit features across different modalities. However, the lack of a dataset that combines multilingualism and multimodality has hindered research exploring the combination of these two aspects, as multimodality can help NER in multiple languages simultaneously. In this paper, we aim to address a more challenging task: multilingual and multimodal named entity recognition (MMNER), considering its potential value and influence. Specifically, we construct a large-scale MMNER dataset with four languages (English, French, German and Spanish) and two modalities (text and image). To tackle this challenging MMNER task on the dataset, we introduce a new model called 2M-NER, which aligns the text and image representations using contrastive learning and integrates a multimodal collaboration module to effectively depict the interactions between the two modalities. Extensive experimental results demonstrate that our model achieves the highest F1 score in multilingual and multimodal NER tasks compared to some comparative and representative baselines. Additionally, in a challenging analysis, we discovered that sentence-level alignment interferes a lot with NER models, indicating the higher level of difficulty in our dataset.
4/29/2024

A Framework for Multi-modal Learning: Jointly Modeling Inter- & Intra-Modality Dependencies
Divyam Madaan, Taro Makino, Sumit Chopra, Kyunghyun Cho
0
0
Supervised multi-modal learning involves mapping multiple modalities to a target label. Previous studies in this field have concentrated on capturing in isolation either the inter-modality dependencies (the relationships between different modalities and the label) or the intra-modality dependencies (the relationships within a single modality and the label). We argue that these conventional approaches that rely solely on either inter- or intra-modality dependencies may not be optimal in general. We view the multi-modal learning problem from the lens of generative models where we consider the target as a source of multiple modalities and the interaction between them. Towards that end, we propose inter- & intra-modality modeling (I2M2) framework, which captures and integrates both the inter- and intra-modality dependencies, leading to more accurate predictions. We evaluate our approach using real-world healthcare and vision-and-language datasets with state-of-the-art models, demonstrating superior performance over traditional methods focusing only on one type of modality dependency.
5/29/2024