Attribute-Aware Implicit Modality Alignment for Text Attribute Person Search
2406.03721
0
0

Abstract
Text attribute person search aims to find specific pedestrians through given textual attributes, which is very meaningful in the scene of searching for designated pedestrians through witness descriptions. The key challenge is the significant modality gap between textual attributes and images. Previous methods focused on achieving explicit representation and alignment through unimodal pre-trained models. Nevertheless, the absence of inter-modality correspondence in these models may lead to distortions in the local information of intra-modality. Moreover, these methods only considered the alignment of inter-modality and ignored the differences between different attribute categories. To mitigate the above problems, we propose an Attribute-Aware Implicit Modality Alignment (AIMA) framework to learn the correspondence of local representations between textual attributes and images and combine global representation matching to narrow the modality gap. Firstly, we introduce the CLIP model as the backbone and design prompt templates to transform attribute combinations into structured sentences. This facilitates the model's ability to better understand and match image details. Next, we design a Masked Attribute Prediction (MAP) module that predicts the masked attributes after the interaction of image and masked textual attribute features through multi-modal interaction, thereby achieving implicit local relationship alignment. Finally, we propose an Attribute-IoU Guided Intra-Modal Contrastive (A-IoU IMC) loss, aligning the distribution of different textual attributes in the embedding space with their IoU distribution, achieving better semantic arrangement. Extensive experiments on the Market-1501 Attribute, PETA, and PA100K datasets show that the performance of our proposed method significantly surpasses the current state-of-the-art methods.
Create account to get full access
Attribute-Aware Implicit Modality Alignment for Text Attribute Person Search
Overview
- This research paper proposes an approach called Attribute-Aware Implicit Modality Alignment (AAIMA) for text-based person search.
- The goal is to enable more accurate retrieval of person images based on textual descriptions of their attributes, such as hair color, clothing, and accessories.
- The method aims to better align the text and image modalities by capturing the implicit relationships between attributes and visual characteristics.
Plain English Explanation
The paper describes a technique to help computers better understand the connection between how people are described in words and what they look like in images. When you search for a person based on a textual description of their appearance, this method is designed to improve the chances of finding the right matching image.
The key idea is to capture the hidden or "implicit" relationships between the words used to describe a person's attributes (like hair color, clothing, etc.) and the actual visual characteristics in the corresponding image. By learning these implicit connections, the system can make more informed decisions about which images best match a given textual description.
This could be useful in applications like law enforcement, where investigators need to search databases of images to find people based on eyewitness reports or other text-based descriptions of their appearance. It could also have applications in online shopping, social media, or other areas where people want to find visuals that match textual queries about people's looks.
Technical Explanation
The Attribute-Aware Implicit Modality Alignment (AAIMA) approach proposed in the paper aims to better align the text and image modalities by capturing the implicit relationships between attributes and visual characteristics. This is done through a multi-task learning framework that jointly optimizes for attribute classification and cross-modal retrieval.
The architecture includes a text encoder to process the input textual descriptions, an image encoder to process the person images, and a cross-modal alignment module that learns to map the text and image representations into a shared latent space.
Importantly, the model also includes an attribute prediction branch that learns to predict the person's attributes from the image representation. This helps the model capture the implicit connections between the textual descriptions and the actual visual characteristics.
The experiments demonstrate that this attribute-aware alignment approach outperforms previous text-to-image retrieval methods on several benchmark datasets for text-based person search.
Critical Analysis
The paper presents a well-designed approach that addresses an important real-world problem. The authors thoroughly evaluate their method and demonstrate its advantages over prior work.
However, the paper does not delve into some potential limitations or caveats. For example, the model's performance may be constrained by the quality and coverage of the attribute annotations in the training data. Additionally, the approach may struggle with rare or unusual attribute combinations that are not well represented in the datasets.
Further research could explore ways to make the model more robust to such edge cases, perhaps by incorporating external knowledge sources or using more sophisticated attribute modeling techniques. Investigating the model's interpretability and explainability could also be a fruitful direction, as understanding the implicit relationships learned by the system could lead to additional insights.
Conclusion
The Attribute-Aware Implicit Modality Alignment (AAIMA) approach proposed in this paper represents a significant advance in the field of text-based person search. By capturing the implicit connections between textual descriptions and visual characteristics, the method can retrieve person images more accurately based on attribute-rich queries.
This technology has the potential to enable a wide range of applications, from improved search and discovery in digital media to enhanced tools for law enforcement and security. As the authors continue to refine and expand on this work, it could lead to even more powerful and versatile systems for bridging the gap between language and vision.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Towards Better Text-to-Image Generation Alignment via Attention Modulation
Yihang Wu, Xiao Cao, Kaixin Li, Zitan Chen, Haonan Wang, Lei Meng, Zhiyong Huang
0
0
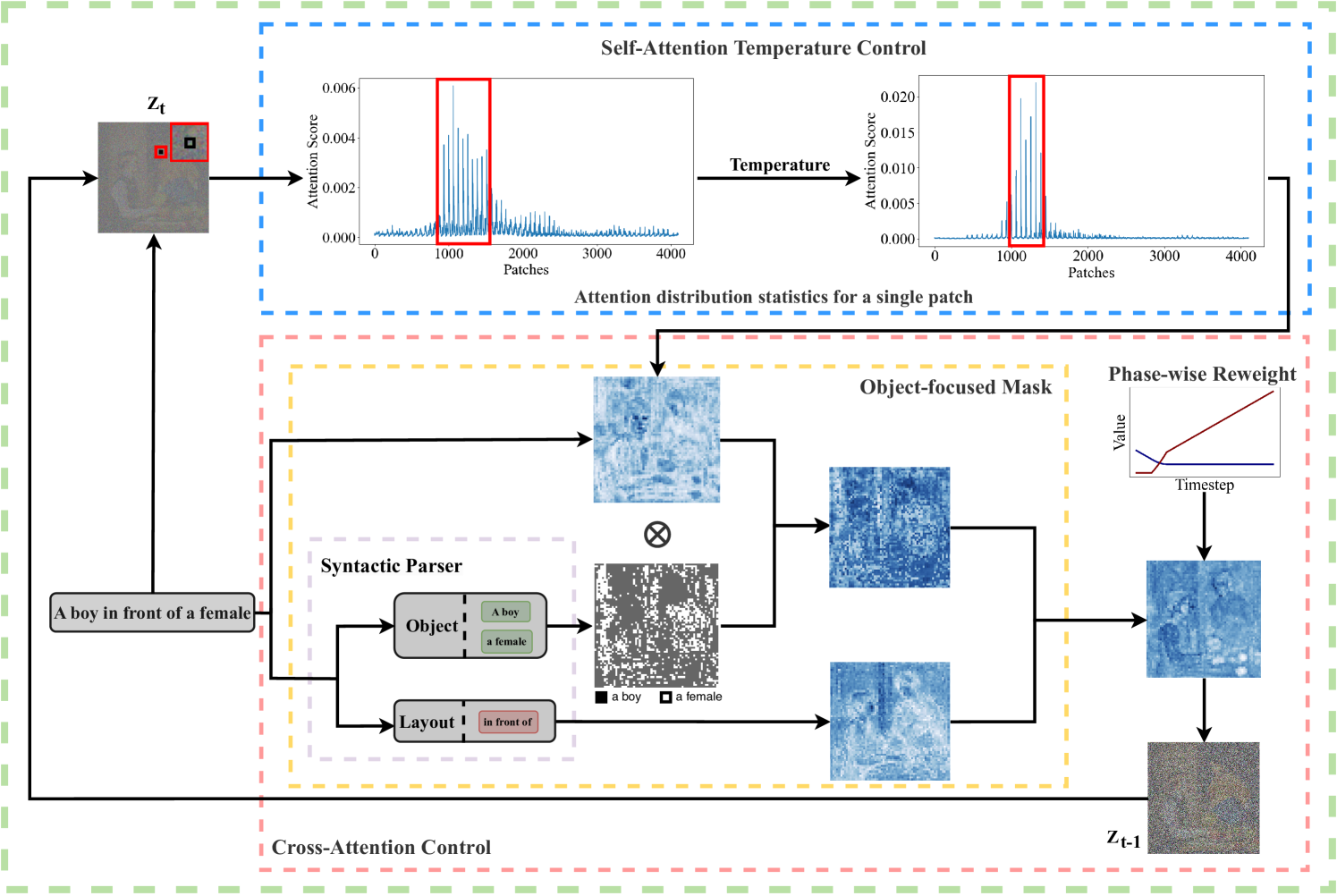
In text-to-image generation tasks, the advancements of diffusion models have facilitated the fidelity of generated results. However, these models encounter challenges when processing text prompts containing multiple entities and attributes. The uneven distribution of attention results in the issues of entity leakage and attribute misalignment. Training from scratch to address this issue requires numerous labeled data and is resource-consuming. Motivated by this, we propose an attribution-focusing mechanism, a training-free phase-wise mechanism by modulation of attention for diffusion model. One of our core ideas is to guide the model to concentrate on the corresponding syntactic components of the prompt at distinct timesteps. To achieve this, we incorporate a temperature control mechanism within the early phases of the self-attention modules to mitigate entity leakage issues. An object-focused masking scheme and a phase-wise dynamic weight control mechanism are integrated into the cross-attention modules, enabling the model to discern the affiliation of semantic information between entities more effectively. The experimental results in various alignment scenarios demonstrate that our model attain better image-text alignment with minimal additional computational cost.
4/23/2024

LAIP: Learning Local Alignment from Image-Phrase Modeling for Text-based Person Search
Haiguang Wang, Yu Wu, Mengxia Wu, Cao Min, Min Zhang
0
0
Text-based person search aims at retrieving images of a particular person based on a given textual description. A common solution for this task is to directly match the entire images and texts, i.e., global alignment, which fails to deal with discerning specific details that discriminate against appearance-similar people. As a result, some works shift their attention towards local alignment. One group matches fine-grained parts using forward attention weights of the transformer yet underutilizes information. Another implicitly conducts local alignment by reconstructing masked parts based on unmasked context yet with a biased masking strategy. All limit performance improvement. This paper proposes the Local Alignment from Image-Phrase modeling (LAIP) framework, with Bidirectional Attention-weighted local alignment (BidirAtt) and Mask Phrase Modeling (MPM) module.BidirAtt goes beyond the typical forward attention by considering the gradient of the transformer as backward attention, utilizing two-sided information for local alignment. MPM focuses on mask reconstruction within the noun phrase rather than the entire text, ensuring an unbiased masking strategy. Extensive experiments conducted on the CUHK-PEDES, ICFG-PEDES, and RSTPReid datasets demonstrate the superiority of the LAIP framework over existing methods.
6/26/2024
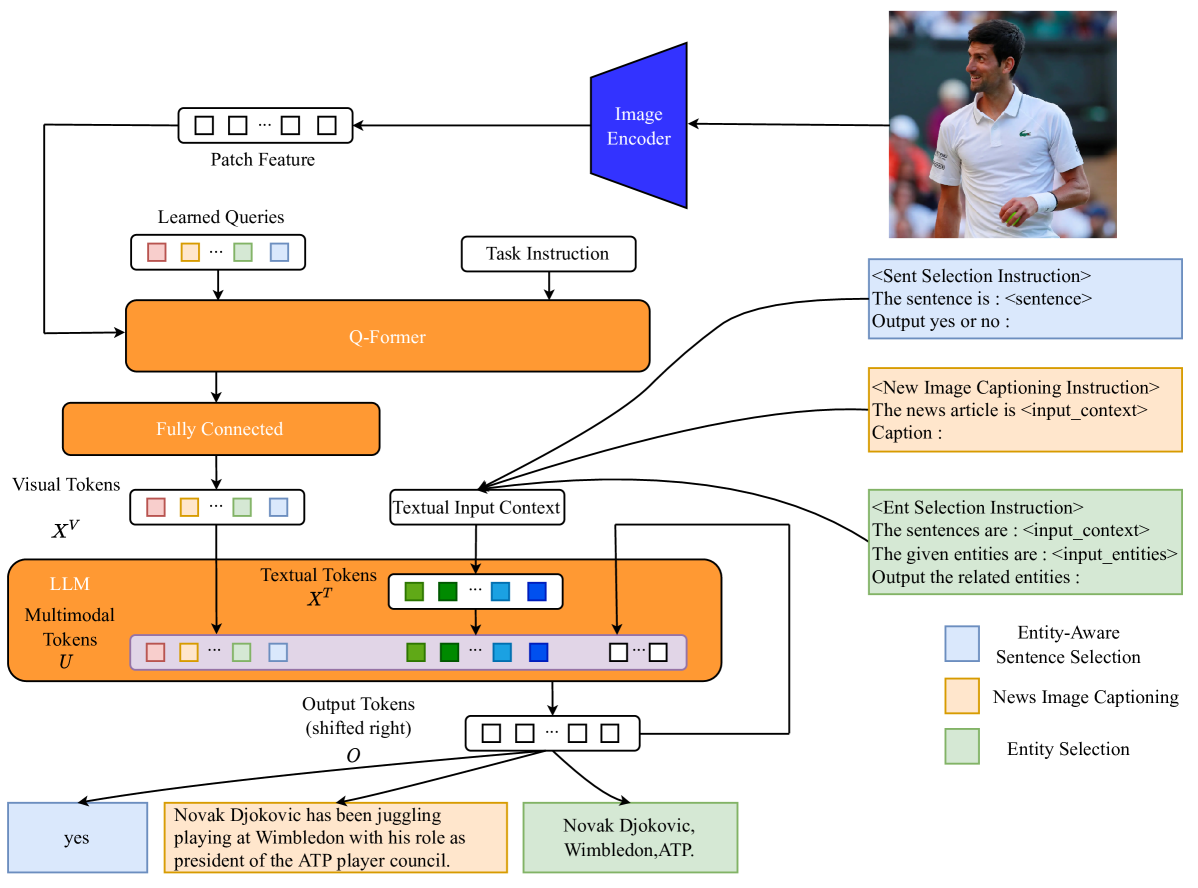
EAMA : Entity-Aware Multimodal Alignment Based Approach for News Image Captioning
Junzhe Zhang, Huixuan Zhang, Xunjian Yin, Xiaojun Wan
0
0
News image captioning requires model to generate an informative caption rich in entities, with the news image and the associated news article. Though Multimodal Large Language Models (MLLMs) have demonstrated remarkable capabilities in addressing various vision-language tasks, our research finds that current MLLMs still bear limitations in handling entity information on news image captioning task. Besides, while MLLMs have the ability to process long inputs, generating high-quality news image captions still requires a trade-off between sufficiency and conciseness of textual input information. To explore the potential of MLLMs and address problems we discovered, we propose : an Entity-Aware Multimodal Alignment based approach for news image captioning. Our approach first aligns the MLLM through Balance Training Strategy with two extra alignment tasks: Entity-Aware Sentence Selection task and Entity Selection task, together with News Image Captioning task, to enhance its capability in handling multimodal entity information. The aligned MLLM will utilizes the additional entity-related information it explicitly extracts to supplement its textual input while generating news image captions. Our approach achieves better results than all previous models in CIDEr score on GoodNews dataset (72.33 -> 88.39) and NYTimes800k dataset (70.83 -> 85.61).
5/7/2024
🤿
Leveraging Intra-modal and Inter-modal Interaction for Multi-Modal Entity Alignment
Zhiwei Hu, V'ictor Guti'errez-Basulto, Zhiliang Xiang, Ru Li, Jeff Z. Pan
0
0
Multi-modal entity alignment (MMEA) aims to identify equivalent entity pairs across different multi-modal knowledge graphs (MMKGs). Existing approaches focus on how to better encode and aggregate information from different modalities. However, it is not trivial to leverage multi-modal knowledge in entity alignment due to the modal heterogeneity. In this paper, we propose a Multi-Grained Interaction framework for Multi-Modal Entity Alignment (MIMEA), which effectively realizes multi-granular interaction within the same modality or between different modalities. MIMEA is composed of four modules: i) a Multi-modal Knowledge Embedding module, which extracts modality-specific representations with multiple individual encoders; ii) a Probability-guided Modal Fusion module, which employs a probability guided approach to integrate uni-modal representations into joint-modal embeddings, while considering the interaction between uni-modal representations; iii) an Optimal Transport Modal Alignment module, which introduces an optimal transport mechanism to encourage the interaction between uni-modal and joint-modal embeddings; iv) a Modal-adaptive Contrastive Learning module, which distinguishes the embeddings of equivalent entities from those of non-equivalent ones, for each modality. Extensive experiments conducted on two real-world datasets demonstrate the strong performance of MIMEA compared to the SoTA. Datasets and code have been submitted as supplementary materials.
4/30/2024