Lexically Grounded Subword Segmentation
2406.13560
0
0
Abstract
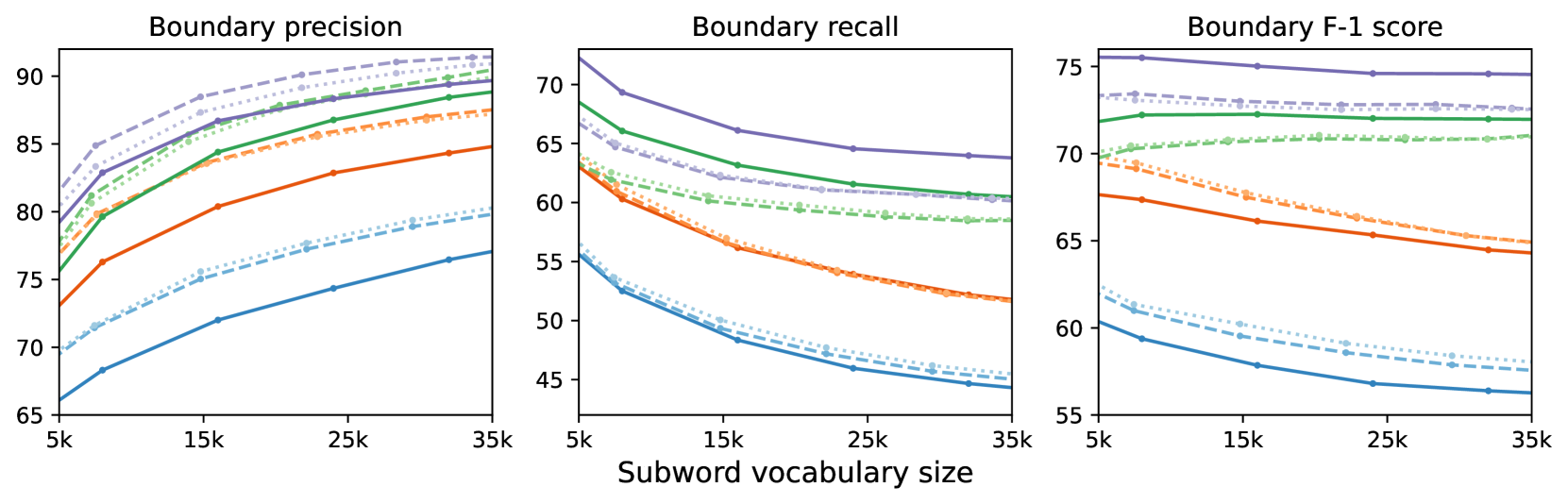
We present three innovations in tokenization and subword segmentation. First, we propose to use unsupervised morphological analysis with Morfessor as pre-tokenization. Second, we present an algebraic method for obtaining subword embeddings grounded in a word embedding space. Based on that, we design a novel subword segmentation algorithm that uses the embeddings, ensuring that the procedure considers lexical meaning. Third, we introduce an efficient segmentation algorithm based on a subword bigram model that can be initialized with the lexically aware segmentation method to avoid using Morfessor and large embedding tables at inference time. We evaluate the proposed approaches using two intrinsic metrics and measure their performance on two downstream tasks: part-of-speech tagging and machine translation. Our experiments show significant improvements in the morphological plausibility of the segmentation when evaluated using segmentation precision on morpheme boundaries and improved R'enyi efficiency in 8 languages. Although the proposed tokenization methods do not have a large impact on automatic translation quality, we observe consistent performance gains in the arguably more morphological task of part-of-speech tagging.
Create account to get full access
Overview
- This paper proposes a new approach for lexically-grounded subword segmentation, which aims to improve the quality of subword tokenization for natural language processing tasks.
- The key ideas include using lexical knowledge to guide the segmentation process, employing subword embeddings to capture meaningful linguistic units, and leveraging a neural network architecture to learn the segmentation model.
- The proposed method outperforms existing subword tokenization techniques on various benchmarks, demonstrating its effectiveness for improving downstream language understanding and generation capabilities.
Plain English Explanation
In natural language processing, subword tokenization is an important step that breaks down words into smaller meaningful units called "subwords." This can help language models handle rare or unknown words more effectively. However, existing subword tokenization methods often struggle to capture the true linguistic structure of words.
The paper introduces a new approach called lexically-grounded subword segmentation that aims to address this challenge. The key idea is to use lexical knowledge - information about the meanings and structures of words - to guide the subword segmentation process. This helps ensure that the resulting subwords align better with the actual linguistic units within words.
The method works by first constructing a vocabulary of subwords that capture meaningful linguistic patterns. It then uses a neural network to learn how to segment words into these subwords in a way that is informed by the lexical knowledge. The neural network is trained on a dataset of words and their correct segmentations.
By incorporating lexical information, this approach can produce subword tokenizations that are more faithful to the true linguistic structure of words. This, in turn, can lead to improved performance on a variety of natural language processing tasks, such as language understanding and generation.
Technical Explanation
The paper introduces a lexically-grounded subword segmentation approach that leverages lexical knowledge to improve the quality of subword tokenization. The key components of the method are:
-
Pre-tokenization and Vocabulary Construction: The authors first construct a subword vocabulary by identifying meaningful linguistic units (e.g., morphemes, syllables) based on lexical knowledge. This vocabulary is then used to guide the subsequent segmentation process.
-
Segmentation with Subword Embeddings: The authors propose a neural network architecture that learns to segment words into the pre-constructed subword vocabulary. The network uses subword embeddings - vector representations of the subwords - to capture the semantic and syntactic information associated with each subword. This allows the model to make segmentation decisions that are informed by the linguistic properties of the subwords.
-
Training and Inference: The segmentation model is trained on a dataset of words and their gold-standard segmentations. During inference, the model takes a new word as input and outputs a segmentation that best aligns with the learned subword representations and the lexical knowledge encoded in the vocabulary.
The authors evaluate their approach on several benchmark datasets and compare it to existing subword tokenization methods, such as Byte Pair Encoding (BPE) and SentencePiece. The results demonstrate that the proposed lexically-grounded segmentation method outperforms these baselines, leading to improved performance on downstream language understanding and generation tasks.
Critical Analysis
The paper presents a promising approach for improving subword tokenization by leveraging lexical knowledge. The authors' key insight of using pre-constructed subword vocabularies and subword embeddings to guide the segmentation process is well-motivated and backed by strong empirical results.
One potential limitation of the approach is that it relies on the availability of high-quality lexical resources, such as morphological dictionaries or syllabification rules, to build the initial subword vocabulary. In low-resource scenarios or for languages with limited lexical data, this may pose a challenge.
Additionally, the paper does not explore the trade-offs between the complexity of the subword vocabulary and the performance of the segmentation model. It would be interesting to see how the model's behavior and downstream task performance change as the size and granularity of the subword vocabulary are varied.
Further research could also investigate the generalizability of the approach to other languages and domains, as well as its applicability to more diverse natural language processing tasks beyond the ones considered in the paper.
Conclusion
The lexically-grounded subword segmentation approach proposed in this paper offers a promising direction for enhancing subword tokenization in natural language processing. By incorporating lexical knowledge into the segmentation process, the method can produce subword tokenizations that better align with the true linguistic structure of words.
This, in turn, can lead to improved performance on a variety of language understanding and generation tasks, making the approach valuable for advancing the capabilities of language models and other NLP systems. The authors' work highlights the importance of leveraging linguistic insights to improve the fundamental building blocks of natural language processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Unsupervised Morphological Tree Tokenizer
Qingyang Zhu, Xiang Hu, Pengyu Ji, Wei Wu, Kewei Tu
0
0
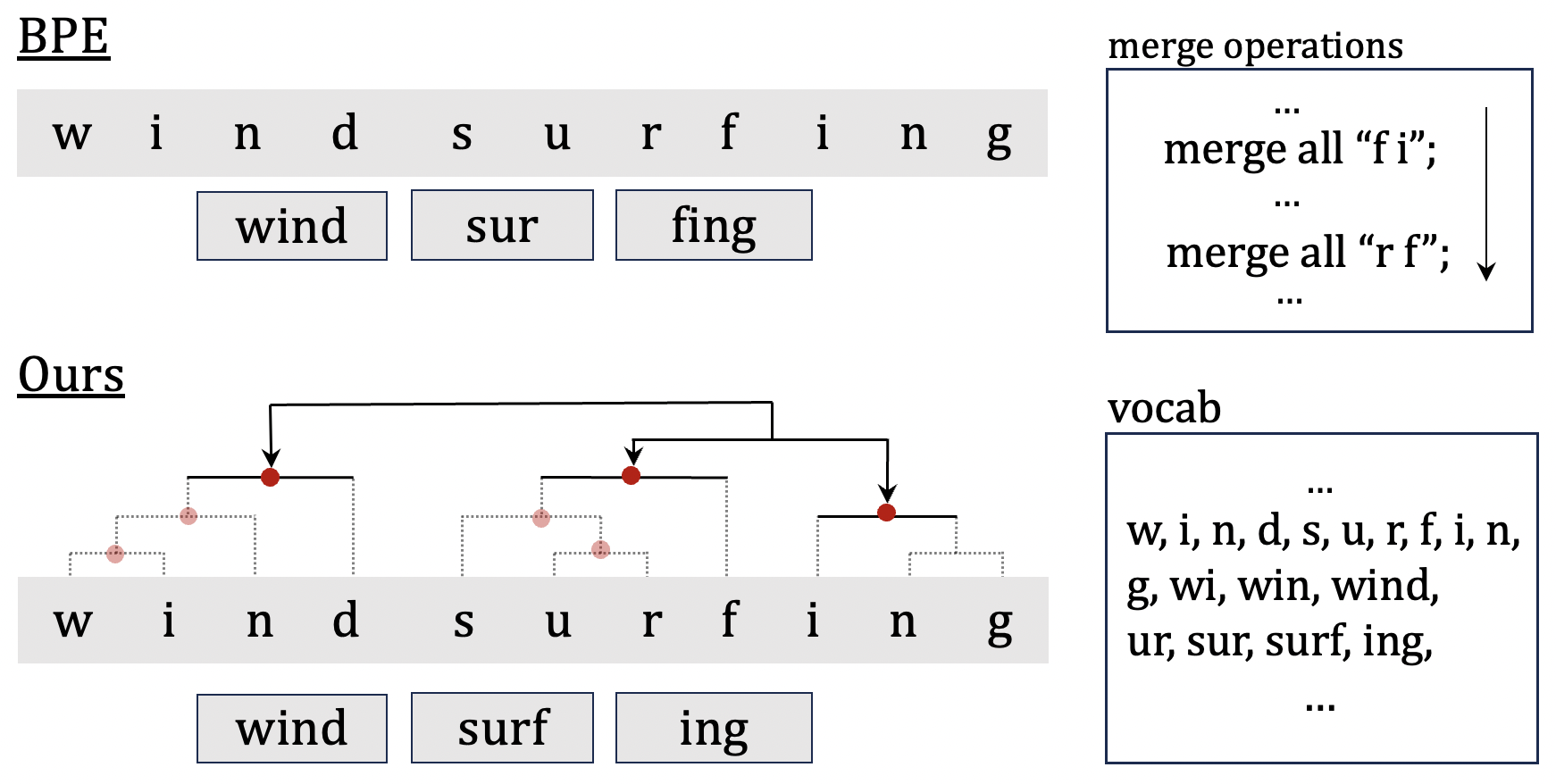
As a cornerstone in language modeling, tokenization involves segmenting text inputs into pre-defined atomic units. Conventional statistical tokenizers often disrupt constituent boundaries within words, thereby corrupting semantic information. To address this drawback, we introduce morphological structure guidance to tokenization and propose a deep model to induce character-level structures of words. Specifically, the deep model jointly encodes internal structures and representations of words with a mechanism named $textit{MorphOverriding}$ to ensure the indecomposability of morphemes. By training the model with self-supervised objectives, our method is capable of inducing character-level structures that align with morphological rules without annotated training data. Based on the induced structures, our algorithm tokenizes words through vocabulary matching in a top-down manner. Empirical results indicate that the proposed method effectively retains complete morphemes and outperforms widely adopted methods such as BPE and WordPiece on both morphological segmentation tasks and language modeling tasks. The code will be released later.
6/24/2024

Labeled Morphological Segmentation with Semi-Markov Models
Ryan Cotterell, Thomas Muller, Alexander Fraser, Hinrich Schutze
0
0
We present labeled morphological segmentation, an alternative view of morphological processing that unifies several tasks. From an annotation standpoint, we additionally introduce a new hierarchy of morphotactic tagsets. Finally, we develop modelname, a discriminative morphological segmentation system that, contrary to previous work, explicitly models morphotactics. We show that textsc{chipmunk} yields improved performance on three tasks for all six languages: (i) morphological segmentation, (ii) stemming and (iii) morphological tag classification. On morphological segmentation, our method shows absolute improvements of 2--6 points $F_1$ over the baseline.
4/16/2024
🛸
Using Contextual Information for Sentence-level Morpheme Segmentation
Prabin Bhandari, Abhishek Paudel
0
0
Recent advancements in morpheme segmentation primarily emphasize word-level segmentation, often neglecting the contextual relevance within the sentence. In this study, we redefine the morpheme segmentation task as a sequence-to-sequence problem, treating the entire sentence as input rather than isolating individual words. Our findings reveal that the multilingual model consistently exhibits superior performance compared to monolingual counterparts. While our model did not surpass the performance of the current state-of-the-art, it demonstrated comparable efficacy with high-resource languages while revealing limitations in low-resource language scenarios.
5/15/2024
Evaluating Subword Tokenization: Alien Subword Composition and OOV Generalization Challenge
Khuyagbaatar Batsuren, Ekaterina Vylomova, Verna Dankers, Tsetsuukhei Delgerbaatar, Omri Uzan, Yuval Pinter, G'abor Bella
0
0
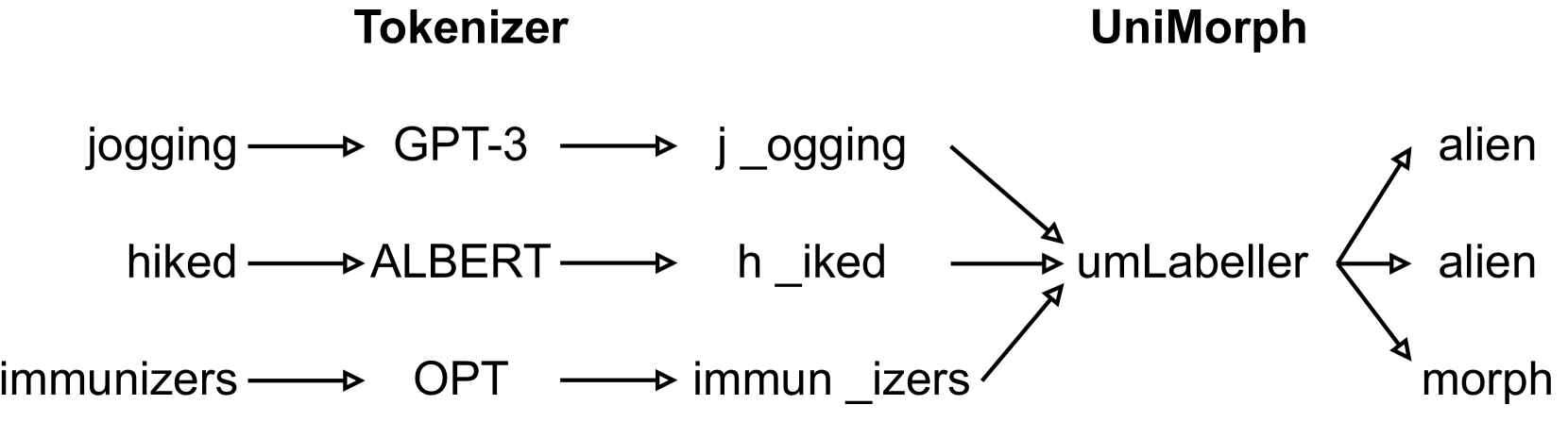
The popular subword tokenizers of current language models, such as Byte-Pair Encoding (BPE), are known not to respect morpheme boundaries, which affects the downstream performance of the models. While many improved tokenization algorithms have been proposed, their evaluation and cross-comparison is still an open problem. As a solution, we propose a combined intrinsic-extrinsic evaluation framework for subword tokenization. Intrinsic evaluation is based on our new UniMorph Labeller tool that classifies subword tokenization as either morphological or alien. Extrinsic evaluation, in turn, is performed via the Out-of-Vocabulary Generalization Challenge 1.0 benchmark, which consists of three newly specified downstream text classification tasks. Our empirical findings show that the accuracy of UniMorph Labeller is 98%, and that, in all language models studied (including ALBERT, BERT, RoBERTa, and DeBERTa), alien tokenization leads to poorer generalizations compared to morphological tokenization for semantic compositionality of word meanings.
4/23/2024