Unsupervised Morphological Tree Tokenizer
2406.15245
0
0
Abstract
As a cornerstone in language modeling, tokenization involves segmenting text inputs into pre-defined atomic units. Conventional statistical tokenizers often disrupt constituent boundaries within words, thereby corrupting semantic information. To address this drawback, we introduce morphological structure guidance to tokenization and propose a deep model to induce character-level structures of words. Specifically, the deep model jointly encodes internal structures and representations of words with a mechanism named $textit{MorphOverriding}$ to ensure the indecomposability of morphemes. By training the model with self-supervised objectives, our method is capable of inducing character-level structures that align with morphological rules without annotated training data. Based on the induced structures, our algorithm tokenizes words through vocabulary matching in a top-down manner. Empirical results indicate that the proposed method effectively retains complete morphemes and outperforms widely adopted methods such as BPE and WordPiece on both morphological segmentation tasks and language modeling tasks. The code will be released later.
Create account to get full access
Overview
- This paper presents an unsupervised approach to morphological tree tokenization, which aims to automatically segment words into their constituent morphemes without any labeled training data.
- The proposed method leverages the hierarchical structure of words to learn a tree-based tokenizer in an unsupervised manner, allowing for more accurate word representations compared to traditional subword tokenizers.
- The authors evaluate their approach on several benchmark datasets, demonstrating its effectiveness in capturing morphological structure and improving downstream natural language processing tasks.
Plain English Explanation
Words are often made up of smaller building blocks called morphemes, which are the smallest meaningful units of a language. For example, the word "unlockable" contains the morphemes "un", "lock", and "able". Subword tokenizers are commonly used in natural language processing to break down words into these subparts, but they don't always capture the full hierarchical structure of the words.
The researchers in this paper propose a new approach called the "Unsupervised Morphological Tree Tokenizer" that can automatically discover the tree-like structure of words without any labeled training data. This allows for a more nuanced understanding of the internal composition of words, which can be beneficial for tasks like machine translation, text generation, and language understanding.
The key idea is to learn this morphological structure in an unsupervised way, by analyzing patterns in the language data itself, rather than relying on manually annotated examples. The authors demonstrate that their tree-based tokenizer outperforms traditional subword methods on a variety of benchmarks, suggesting that capturing the hierarchical nature of words can lead to more accurate and informative word representations.
Technical Explanation
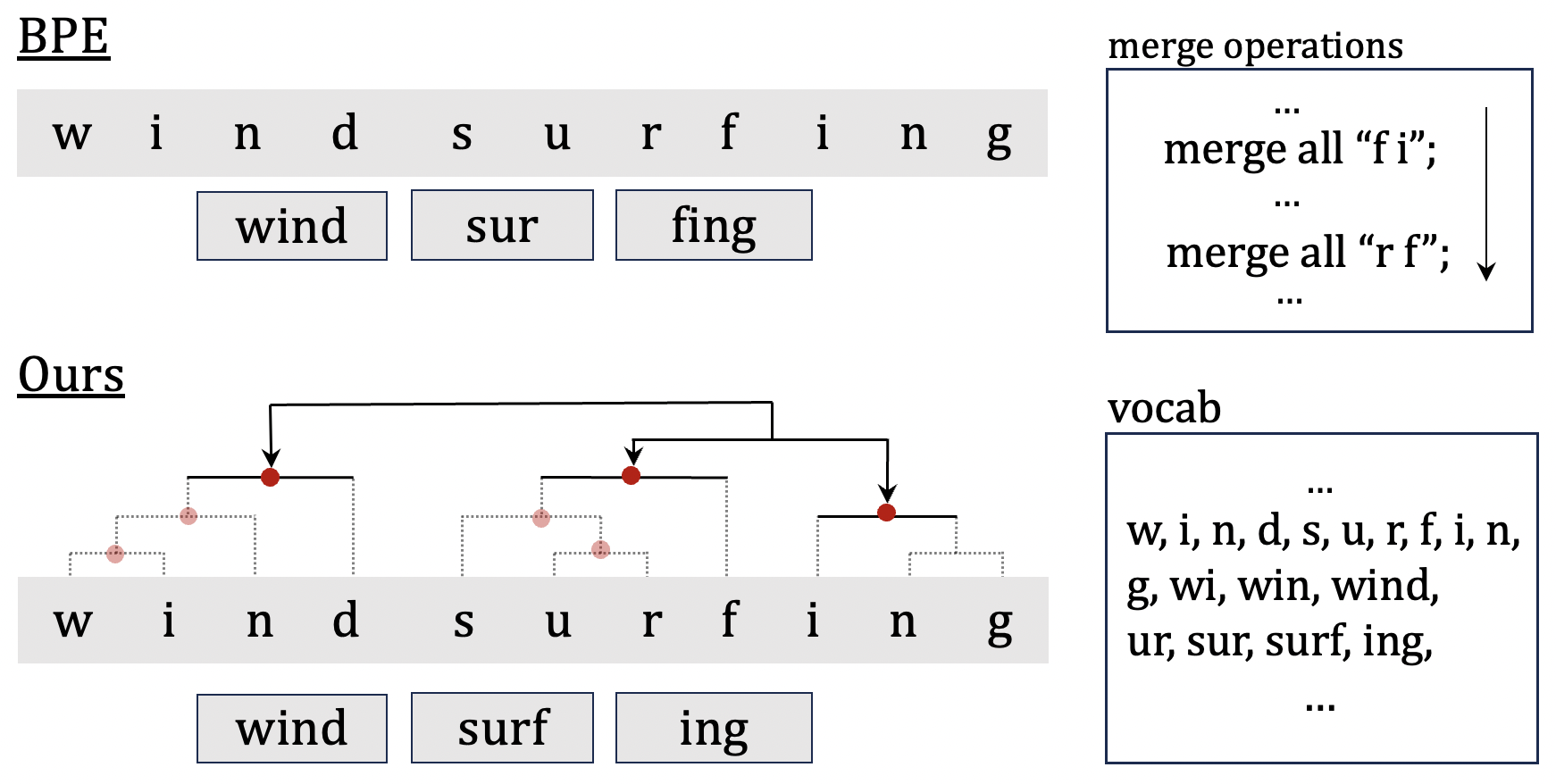
The paper introduces the "Unsupervised Morphological Tree Tokenizer" (UMTT), a novel approach to segmenting words into their morphological components without any labeled training data. Unlike traditional subword tokenizers, which break words into fixed-size pieces, the UMTT learns a tree-structured representation that reflects the inherent hierarchical nature of morphology.
The key components of the UMTT are:
- Morphological Tree Construction: The model learns to construct a binary tree for each word, where the leaf nodes correspond to the individual morphemes and the internal nodes capture the hierarchical relationships between them.
- Unsupervised Training: The model is trained in an unsupervised manner, using only the raw text data, to optimize the tree structures such that they best explain the observed words.
- Tokenization: During inference, the trained UMTT model is used to decompose new words into their morphological constituents by traversing the learned tree structures.
The authors evaluate the UMTT on several benchmark datasets for morphological segmentation and show that it outperforms strong supervised and unsupervised baselines. They also demonstrate the benefits of the tree-structured representations in downstream tasks, such as machine translation and part-of-speech tagging.
Critical Analysis
The Unsupervised Morphological Tree Tokenizer presented in this paper is a compelling approach that addresses some of the limitations of traditional subword tokenization methods. By learning a hierarchical representation of words, the model can capture more nuanced morphological structure, which can be advantageous for a variety of natural language processing applications.
However, the paper does not discuss the potential limitations or challenges of the UMTT approach. For instance, it's unclear how well the model would perform on morphologically complex languages or how it would scale to large vocabularies. Additionally, the authors do not explore the interpretability of the learned tree structures or how they could be leveraged for linguistic analysis.
Furthermore, while the paper demonstrates the UMTT's effectiveness on several benchmarks, it would be valuable to see how the model performs in real-world, production-level scenarios, where factors like computational efficiency, robustness, and cross-lingual generalization may become more important.
Overall, the Unsupervised Morphological Tree Tokenizer is a promising contribution to the field of natural language processing, but further research is needed to fully understand its strengths, limitations, and practical implications.
Conclusion
The Unsupervised Morphological Tree Tokenizer proposed in this paper represents a novel approach to word segmentation that goes beyond traditional subword tokenization methods. By learning a hierarchical representation of words, the model can capture the inherent morphological structure, leading to more accurate and informative word representations.
The authors demonstrate the effectiveness of their approach on several benchmark datasets, showing improvements over both supervised and unsupervised baselines. This suggests that the tree-structured representations learned by the UMTT can be beneficial for a range of natural language processing tasks, such as machine translation, text generation, and language understanding.
While the paper highlights the potential of the UMTT, further research is needed to fully understand its limitations and explore its practical applications. Nonetheless, this work represents an important step towards developing more sophisticated and linguistically-informed word tokenization methods, which can have far-reaching implications for the field of natural language processing as a whole.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Lexically Grounded Subword Segmentation
Jindv{r}ich Libovick'y, Jindv{r}ich Helcl
0
0
We present three innovations in tokenization and subword segmentation. First, we propose to use unsupervised morphological analysis with Morfessor as pre-tokenization. Second, we present an algebraic method for obtaining subword embeddings grounded in a word embedding space. Based on that, we design a novel subword segmentation algorithm that uses the embeddings, ensuring that the procedure considers lexical meaning. Third, we introduce an efficient segmentation algorithm based on a subword bigram model that can be initialized with the lexically aware segmentation method to avoid using Morfessor and large embedding tables at inference time. We evaluate the proposed approaches using two intrinsic metrics and measure their performance on two downstream tasks: part-of-speech tagging and machine translation. Our experiments show significant improvements in the morphological plausibility of the segmentation when evaluated using segmentation precision on morpheme boundaries and improved R'enyi efficiency in 8 languages. Although the proposed tokenization methods do not have a large impact on automatic translation quality, we observe consistent performance gains in the arguably more morphological task of part-of-speech tagging.
6/21/2024

Labeled Morphological Segmentation with Semi-Markov Models
Ryan Cotterell, Thomas Muller, Alexander Fraser, Hinrich Schutze
0
0
We present labeled morphological segmentation, an alternative view of morphological processing that unifies several tasks. From an annotation standpoint, we additionally introduce a new hierarchy of morphotactic tagsets. Finally, we develop modelname, a discriminative morphological segmentation system that, contrary to previous work, explicitly models morphotactics. We show that textsc{chipmunk} yields improved performance on three tasks for all six languages: (i) morphological segmentation, (ii) stemming and (iii) morphological tag classification. On morphological segmentation, our method shows absolute improvements of 2--6 points $F_1$ over the baseline.
4/16/2024

Tokenization Falling Short: The Curse of Tokenization
Yekun Chai, Yewei Fang, Qiwei Peng, Xuhong Li
0
0
Language models typically tokenize raw text into sequences of subword identifiers from a predefined vocabulary, a process inherently sensitive to typographical errors, length variations, and largely oblivious to the internal structure of tokens-issues we term the curse of tokenization. In this study, we delve into these drawbacks and demonstrate that large language models (LLMs) remain susceptible to these problems. This study systematically investigates these challenges and their impact on LLMs through three critical research questions: (1) complex problem solving, (2) token structure probing, and (3) resilience to typographical variation. Our findings reveal that scaling model parameters can mitigate the issue of tokenization; however, LLMs still suffer from biases induced by typos and other text format variations. Our experiments show that subword regularization such as BPE-dropout can mitigate this issue. We will release our code and data to facilitate further research.
6/18/2024
🧠
Cross-lingual, Character-Level Neural Morphological Tagging
Ryan Cotterell, Georg Heigold
0
0
Even for common NLP tasks, sufficient supervision is not available in many languages -- morphological tagging is no exception. In the work presented here, we explore a transfer learning scheme, whereby we train character-level recurrent neural taggers to predict morphological taggings for high-resource languages and low-resource languages together. Learning joint character representations among multiple related languages successfully enables knowledge transfer from the high-resource languages to the low-resource ones, improving accuracy by up to 30% over a monolingual model.
6/7/2024