A Linear Time and Space Local Point Cloud Geometry Encoder via Vectorized Kernel Mixture (VecKM)
2404.01568
0
0
Abstract
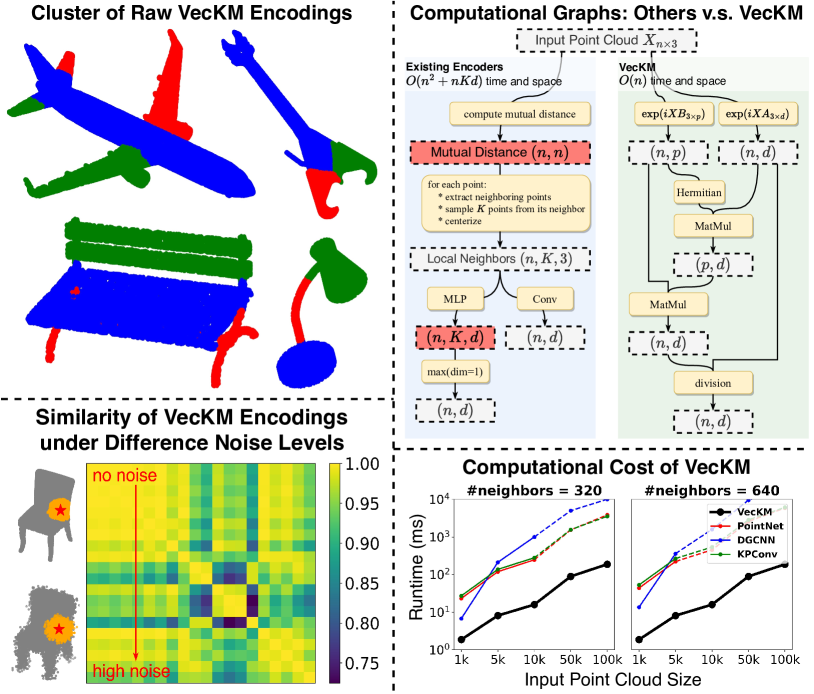
We propose VecKM, a local point cloud geometry encoder that is descriptive and efficient to compute. VecKM leverages a unique approach by vectorizing a kernel mixture to represent the local point cloud. Such representation's descriptiveness is supported by two theorems that validate its ability to reconstruct and preserve the similarity of the local shape. Unlike existing encoders downsampling the local point cloud, VecKM constructs the local geometry encoding using all neighboring points, producing a more descriptive encoding. Moreover, VecKM is efficient to compute and scalable to large point cloud inputs: VecKM reduces the memory cost from $(n^2+nKd)$ to $(nd+np)$; and reduces the major runtime cost from computing $nK$ MLPs to $n$ MLPs, where $n$ is the size of the point cloud, $K$ is the neighborhood size, $d$ is the encoding dimension, and $p$ is a marginal factor. The efficiency is due to VecKM's unique factorizable property that eliminates the need of explicitly grouping points into neighbors. In the normal estimation task, VecKM demonstrates not only 100x faster inference speed but also highest accuracy and strongest robustness. In classification and segmentation tasks, integrating VecKM as a preprocessing module achieves consistently better performance than the PointNet, PointNet++, and point transformer baselines, and runs consistently faster by up to 10 times.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces a new method called Vectorized Kernel Mixture (VecKM) for efficiently encoding the geometry of local point cloud regions.
- VecKM can encode point cloud geometry in linear time and space, making it suitable for large-scale point cloud processing tasks.
- The method represents local point cloud geometry using a mixture of Gaussian kernels, which can be efficiently computed and stored.
Plain English Explanation
VecKM is a technique for compactly representing the shape and structure of small regions within a larger point cloud dataset. Point clouds are collections of individual data points, often used to represent 3D objects or environments. Capturing the local geometry of point clouds is important for many applications, such as 3D reconstruction, object recognition, and scene understanding.
The key idea behind VecKM is to model the local geometry around each point in the cloud using a mixture of Gaussian distributions. Gaussians are mathematical functions that describe bell-shaped curves, and a mixture of them can approximate complex shapes. VecKM finds the optimal set of Gaussians to represent the local geometry around each point, creating a concise encoding of the point cloud's structure.
The authors show that this Gaussian mixture representation can be computed and stored efficiently, using only linear time and space resources. This is a significant improvement over previous methods, which often required more complex and computationally expensive techniques. The compact VecKM encoding makes it practical to process large-scale point cloud datasets, opening up new possibilities for 3D perception and modeling applications.
Technical Explanation
The VecKM method first divides the input point cloud into small local regions around each point. It then models the geometry of each local region using a mixture of Gaussian kernels. The parameters of these Gaussian kernels (means, covariances, and weights) are optimized to best fit the local point distribution.
A key innovation in VecKM is the use of a vectorized computation scheme to efficiently estimate the Gaussian mixture parameters. This allows the local geometry encoding to be computed in linear time and space complexity, in contrast to previous methods that had higher computational costs.
The authors demonstrate the effectiveness of VecKM through experiments on point cloud classification and segmentation tasks. They show that the compact VecKM encodings can achieve competitive performance compared to more complex point cloud processing approaches, while being much more efficient to compute and store.
Critical Analysis
The paper provides a thorough technical description of the VecKM method and convincingly demonstrates its advantages in terms of computational efficiency. However, the authors do acknowledge some limitations:
- The Gaussian mixture model may not be able to capture highly non-Gaussian or complex local geometries as accurately as other representations.
- The method requires carefully selecting the number of Gaussian components to use, which could be challenging for some applications.
- The experiments focus on relatively simple point cloud processing tasks, and the performance on more advanced 3D perception problems is not explored.
Further research could investigate ways to adaptively determine the Gaussian mixture complexity, explore alternative kernel functions beyond Gaussians, and evaluate VecKM on a broader range of point cloud processing benchmarks. Nonetheless, the core contribution of a linear-time and space local geometry encoding is a significant advance that could enable new large-scale 3D perception capabilities.
Conclusion
The VecKM method presented in this paper offers an efficient way to encode the local geometry of point clouds. By representing local regions as Gaussian mixture models, VecKM can capture the shape and structure of point clouds using only linear time and space resources. This efficiency enables the processing of large-scale 3D data, opening up new possibilities for applications in areas like 3D reconstruction, object recognition, and scene understanding. While the Gaussian mixture model has some limitations, the core ideas behind VecKM represent an important step forward in point cloud geometry processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Rectified Gaussian kernel multi-view k-means clustering
Kristina P. Sinaga
0
0
In this paper, we show two new variants of multi-view k-means (MVKM) algorithms to address multi-view data. The general idea is to outline the distance between $h$-th view data points $x_i^h$ and $h$-th view cluster centers $a_k^h$ in a different manner of centroid-based approach. Unlike other methods, our proposed methods learn the multi-view data by calculating the similarity using Euclidean norm in the space of Gaussian-kernel, namely as multi-view k-means with exponent distance (MVKM-ED). By simultaneously aligning the stabilizer parameter $p$ and kernel coefficients $beta^h$, the compression of Gaussian-kernel based weighted distance in Euclidean norm reduce the sensitivity of MVKM-ED. To this end, this paper designated as Gaussian-kernel multi-view k-means (GKMVKM) clustering algorithm. Numerical evaluation of five real-world multi-view data demonstrates the robustness and efficiency of our proposed MVKM-ED and GKMVKM approaches.
5/17/2024
EAGLES: Efficient Accelerated 3D Gaussians with Lightweight EncodingS
Sharath Girish, Kamal Gupta, Abhinav Shrivastava
0
0
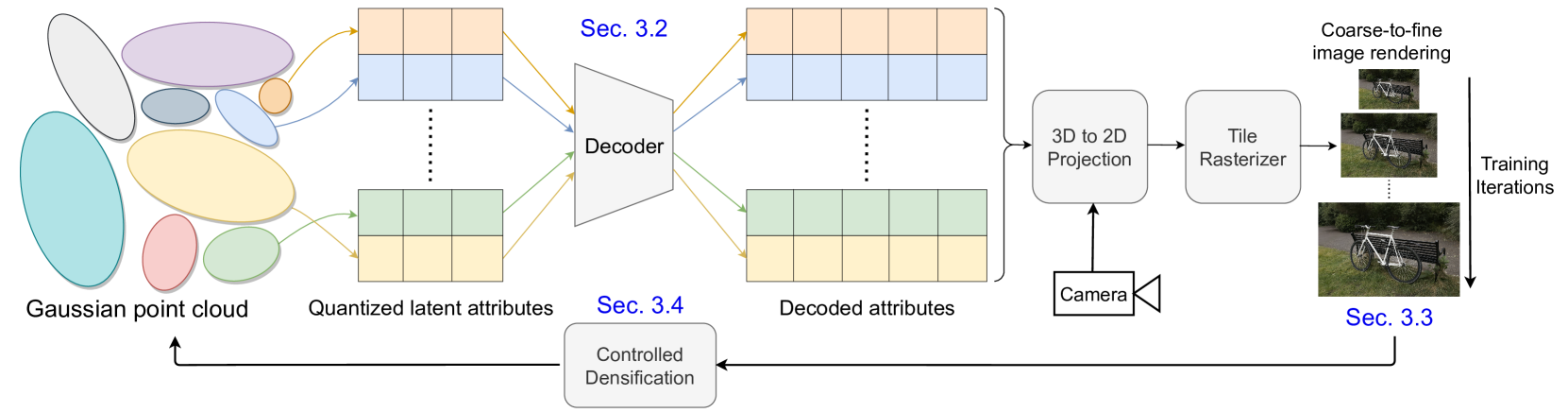
Recently, 3D Gaussian splatting (3D-GS) has gained popularity in novel-view scene synthesis. It addresses the challenges of lengthy training times and slow rendering speeds associated with Neural Radiance Fields (NeRFs). Through rapid, differentiable rasterization of 3D Gaussians, 3D-GS achieves real-time rendering and accelerated training. They, however, demand substantial memory resources for both training and storage, as they require millions of Gaussians in their point cloud representation for each scene. We present a technique utilizing quantized embeddings to significantly reduce per-point memory storage requirements and a coarse-to-fine training strategy for a faster and more stable optimization of the Gaussian point clouds. Our approach develops a pruning stage which results in scene representations with fewer Gaussians, leading to faster training times and rendering speeds for real-time rendering of high resolution scenes. We reduce storage memory by more than an order of magnitude all while preserving the reconstruction quality. We validate the effectiveness of our approach on a variety of datasets and scenes preserving the visual quality while consuming 10-20x lesser memory and faster training/inference speed. Project page and code is available https://efficientgaussian.github.io
4/26/2024
Geometrically-driven Aggregation for Zero-shot 3D Point Cloud Understanding
Guofeng Mei, Luigi Riz, Yiming Wang, Fabio Poiesi
0
0
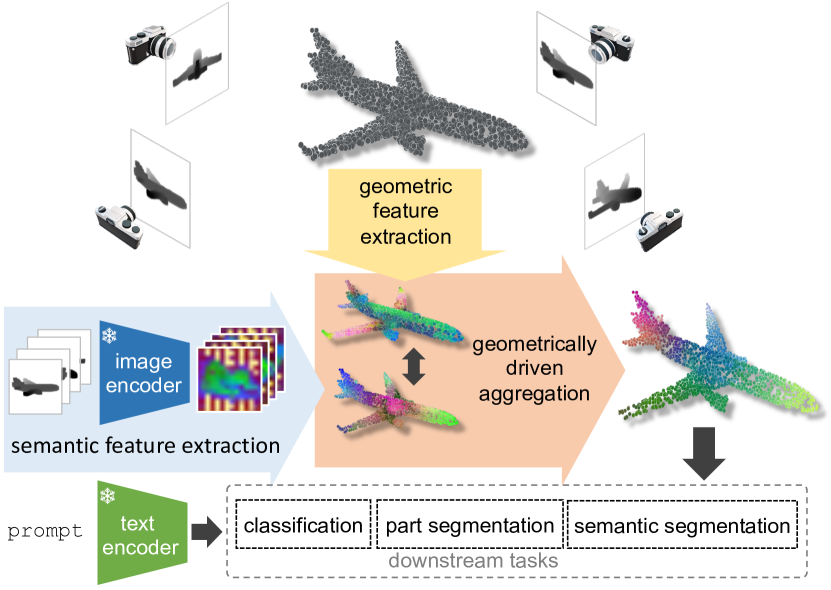
Zero-shot 3D point cloud understanding can be achieved via 2D Vision-Language Models (VLMs). Existing strategies directly map Vision-Language Models from 2D pixels of rendered or captured views to 3D points, overlooking the inherent and expressible point cloud geometric structure. Geometrically similar or close regions can be exploited for bolstering point cloud understanding as they are likely to share semantic information. To this end, we introduce the first training-free aggregation technique that leverages the point cloud's 3D geometric structure to improve the quality of the transferred Vision-Language Models. Our approach operates iteratively, performing local-to-global aggregation based on geometric and semantic point-level reasoning. We benchmark our approach on three downstream tasks, including classification, part segmentation, and semantic segmentation, with a variety of datasets representing both synthetic/real-world, and indoor/outdoor scenarios. Our approach achieves new state-of-the-art results in all benchmarks. Our approach operates iteratively, performing local-to-global aggregation based on geometric and semantic point-level reasoning. Code and dataset are available at https://luigiriz.github.io/geoze-website/
4/16/2024
GPU-Accelerated Vecchia Approximations of Gaussian Processes for Geospatial Data using Batched Matrix Computations
Qilong Pan, Sameh Abdulah, Marc G. Genton, David E. Keyes, Hatem Ltaief, Ying Sun
0
0
Gaussian processes (GPs) are commonly used for geospatial analysis, but they suffer from high computational complexity when dealing with massive data. For instance, the log-likelihood function required in estimating the statistical model parameters for geospatial data is a computationally intensive procedure that involves computing the inverse of a covariance matrix with size n X n, where n represents the number of geographical locations. As a result, in the literature, studies have shifted towards approximation methods to handle larger values of n effectively while maintaining high accuracy. These methods encompass a range of techniques, including low-rank and sparse approximations. Vecchia approximation is one of the most promising methods to speed up evaluating the log-likelihood function. This study presents a parallel implementation of the Vecchia approximation, utilizing batched matrix computations on contemporary GPUs. The proposed implementation relies on batched linear algebra routines to efficiently execute individual conditional distributions in the Vecchia algorithm. We rely on the KBLAS linear algebra library to perform batched linear algebra operations, reducing the time to solution compared to the state-of-the-art parallel implementation of the likelihood estimation operation in the ExaGeoStat software by up to 700X, 833X, 1380X on 32GB GV100, 80GB A100, and 80GB H100 GPUs, respectively. We also successfully manage larger problem sizes on a single NVIDIA GPU, accommodating up to 1M locations with 80GB A100 and H100 GPUs while maintaining the necessary application accuracy. We further assess the accuracy performance of the implemented algorithm, identifying the optimal settings for the Vecchia approximation algorithm to preserve accuracy on two real geospatial datasets: soil moisture data in the Mississippi Basin area and wind speed data in the Middle East.
4/4/2024