Geometrically-driven Aggregation for Zero-shot 3D Point Cloud Understanding

0
Sign in to get full access
Overview
- Presents a new approach for zero-shot 3D point cloud understanding, called Geometrically-driven Aggregation (GGA)
- Addresses the challenge of classifying 3D point cloud data without labeled training data
- Leverages geometric properties of the point cloud to learn meaningful representations
- Outperforms state-of-the-art zero-shot methods on several 3D point cloud benchmarks
Plain English Explanation
Analyzing 3D point cloud data, which represents the shape and structure of objects or environments, is an important task in areas like robotics and autonomous vehicles. Zero-shot learning aims to classify this data without needing labeled training examples, which can be costly and time-consuming to obtain.
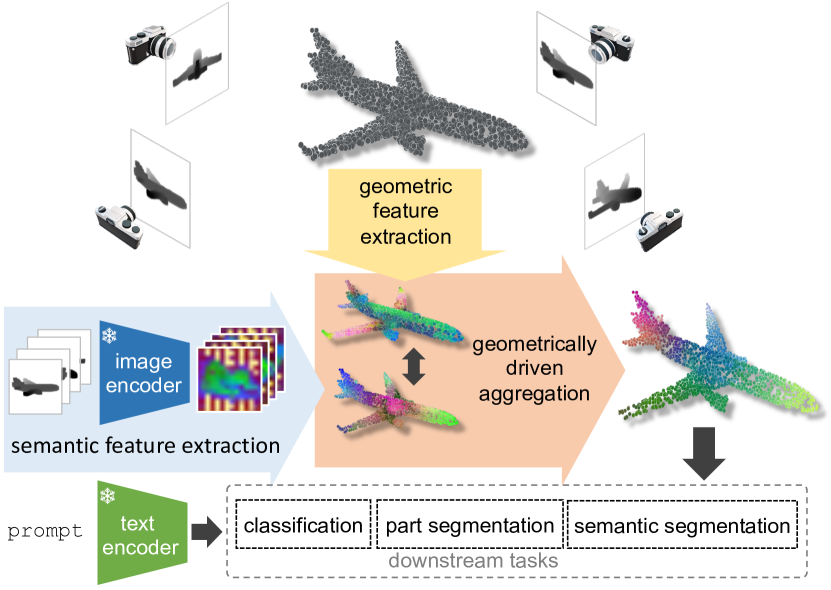
The researchers in this paper propose a new method called Geometrically-driven Aggregation (GGA) that learns meaningful representations of 3D point clouds by leveraging their inherent geometric properties, rather than relying on labeled training data. GGA works by extracting various geometric features from the point cloud, such as local curvature and normal vectors, and using these to generate a compact, informative encoding of the object or scene.
This encoded representation can then be used to classify the point cloud into different categories, even if no labeled training data is available. The authors show that GGA outperforms other state-of-the-art zero-shot learning methods on several benchmarks, demonstrating its effectiveness at learning useful representations from 3D point cloud data without needing labeled examples.
Technical Explanation
The key innovation of the GGA approach is its use of geometric properties to learn meaningful representations of 3D point clouds. Rather than relying on labeled training data, GGA extracts a variety of geometric features from the raw point cloud, including local curvature, normal vectors, and higher-order geometric moments.
These geometric features are then aggregated using an attentional pooling mechanism, which learns to emphasize the most informative aspects of the point cloud. The resulting compact representation can be used for classification, without needing any labeled training data.
The authors demonstrate the effectiveness of GGA on several 3D point cloud benchmarks, including ModelNet40 and ScanNet. They show that GGA outperforms other zero-shot learning approaches, despite not using any labeled training data.
Critical Analysis
One potential limitation of the GGA approach is that it relies on the availability of 3D point cloud data, which can be more difficult to obtain and process than 2D image data. The authors note that their method may not perform as well on sparse or incomplete point clouds, which are common in real-world scenarios.
Additionally, while GGA outperforms other zero-shot learning methods, its performance is still generally lower than supervised learning approaches that have access to labeled training data. This suggests that there is room for further improvements in zero-shot 3D point cloud understanding.
Overall, the GGA method represents a promising step forward in the field of zero-shot 3D point cloud understanding, but more research is needed to address its current limitations and further advance the state of the art.
Conclusion
This paper presents a novel approach called Geometrically-driven Aggregation (GGA) for zero-shot 3D point cloud understanding. GGA leverages the inherent geometric properties of point clouds to learn meaningful representations, without needing any labeled training data.
The authors demonstrate the effectiveness of GGA on several 3D point cloud benchmarks, where it outperforms other state-of-the-art zero-shot learning methods. While GGA has some limitations, it represents an important contribution to the field of 3D point cloud understanding, and could have significant implications for applications like robotics, autonomous vehicles, and augmented reality.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Geometrically-driven Aggregation for Zero-shot 3D Point Cloud Understanding
Guofeng Mei, Luigi Riz, Yiming Wang, Fabio Poiesi
Zero-shot 3D point cloud understanding can be achieved via 2D Vision-Language Models (VLMs). Existing strategies directly map Vision-Language Models from 2D pixels of rendered or captured views to 3D points, overlooking the inherent and expressible point cloud geometric structure. Geometrically similar or close regions can be exploited for bolstering point cloud understanding as they are likely to share semantic information. To this end, we introduce the first training-free aggregation technique that leverages the point cloud's 3D geometric structure to improve the quality of the transferred Vision-Language Models. Our approach operates iteratively, performing local-to-global aggregation based on geometric and semantic point-level reasoning. We benchmark our approach on three downstream tasks, including classification, part segmentation, and semantic segmentation, with a variety of datasets representing both synthetic/real-world, and indoor/outdoor scenarios. Our approach achieves new state-of-the-art results in all benchmarks. Our approach operates iteratively, performing local-to-global aggregation based on geometric and semantic point-level reasoning. Code and dataset are available at https://luigiriz.github.io/geoze-website/
Read more4/16/2024

0
Unsupervised Non-Rigid Point Cloud Matching through Large Vision Models
Zhangquan Chen, Puhua Jiang, Ruqi Huang
In this paper, we propose a novel learning-based framework for non-rigid point cloud matching, which can be trained purely on point clouds without any correspondence annotation but also be extended naturally to partial-to-full matching. Our key insight is to incorporate semantic features derived from large vision models (LVMs) to geometry-based shape feature learning. Our framework effectively leverages the structural information contained in the semantic features to address ambiguities arise from self-similarities among local geometries. Furthermore, our framework also enjoys the strong generalizability and robustness regarding partial observations of LVMs, leading to improvements in the regarding point cloud matching tasks. In order to achieve the above, we propose a pixel-to-point feature aggregation module, a local and global attention network as well as a geometrical similarity loss function. Experimental results show that our method achieves state-of-the-art results in matching non-rigid point clouds in both near-isometric and heterogeneous shape collection as well as more realistic partial and noisy data.
Read more8/19/2024

0
Zero-shot detection of buildings in mobile LiDAR using Language Vision Model
June Moh Goo, Zichao Zeng, Jan Boehm
Recent advances have demonstrated that Language Vision Models (LVMs) surpass the existing State-of-the-Art (SOTA) in two-dimensional (2D) computer vision tasks, motivating attempts to apply LVMs to three-dimensional (3D) data. While LVMs are efficient and effective in addressing various downstream 2D vision tasks without training, they face significant challenges when it comes to point clouds, a representative format for representing 3D data. It is more difficult to extract features from 3D data and there are challenges due to large data sizes and the cost of the collection and labelling, resulting in a notably limited availability of datasets. Moreover, constructing LVMs for point clouds is even more challenging due to the requirements for large amounts of data and training time. To address these issues, our research aims to 1) apply the Grounded SAM through Spherical Projection to transfer 3D to 2D, and 2) experiment with synthetic data to evaluate its effectiveness in bridging the gap between synthetic and real-world data domains. Our approach exhibited high performance with an accuracy of 0.96, an IoU of 0.85, precision of 0.92, recall of 0.91, and an F1 score of 0.92, confirming its potential. However, challenges such as occlusion problems and pixel-level overlaps of multi-label points during spherical image generation remain to be addressed in future studies.
Read more4/16/2024

0
Towards Zero-shot Point Cloud Anomaly Detection: A Multi-View Projection Framework
Yuqi Cheng, Yunkang Cao, Guoyang Xie, Zhichao Lu, Weiming Shen
Detecting anomalies within point clouds is crucial for various industrial applications, but traditional unsupervised methods face challenges due to data acquisition costs, early-stage production constraints, and limited generalization across product categories. To overcome these challenges, we introduce the Multi-View Projection (MVP) framework, leveraging pre-trained Vision-Language Models (VLMs) to detect anomalies. Specifically, MVP projects point cloud data into multi-view depth images, thereby translating point cloud anomaly detection into image anomaly detection. Following zero-shot image anomaly detection methods, pre-trained VLMs are utilized to detect anomalies on these depth images. Given that pre-trained VLMs are not inherently tailored for zero-shot point cloud anomaly detection and may lack specificity, we propose the integration of learnable visual and adaptive text prompting techniques to fine-tune these VLMs, thereby enhancing their detection performance. Extensive experiments on the MVTec 3D-AD and Real3D-AD demonstrate our proposed MVP framework's superior zero-shot anomaly detection performance and the prompting techniques' effectiveness. Real-world evaluations on automotive plastic part inspection further showcase that the proposed method can also be generalized to practical unseen scenarios. The code is available at https://github.com/hustCYQ/MVP-PCLIP.
Read more9/23/2024