LinkGPT: Teaching Large Language Models To Predict Missing Links
2406.04640
0
0
Abstract
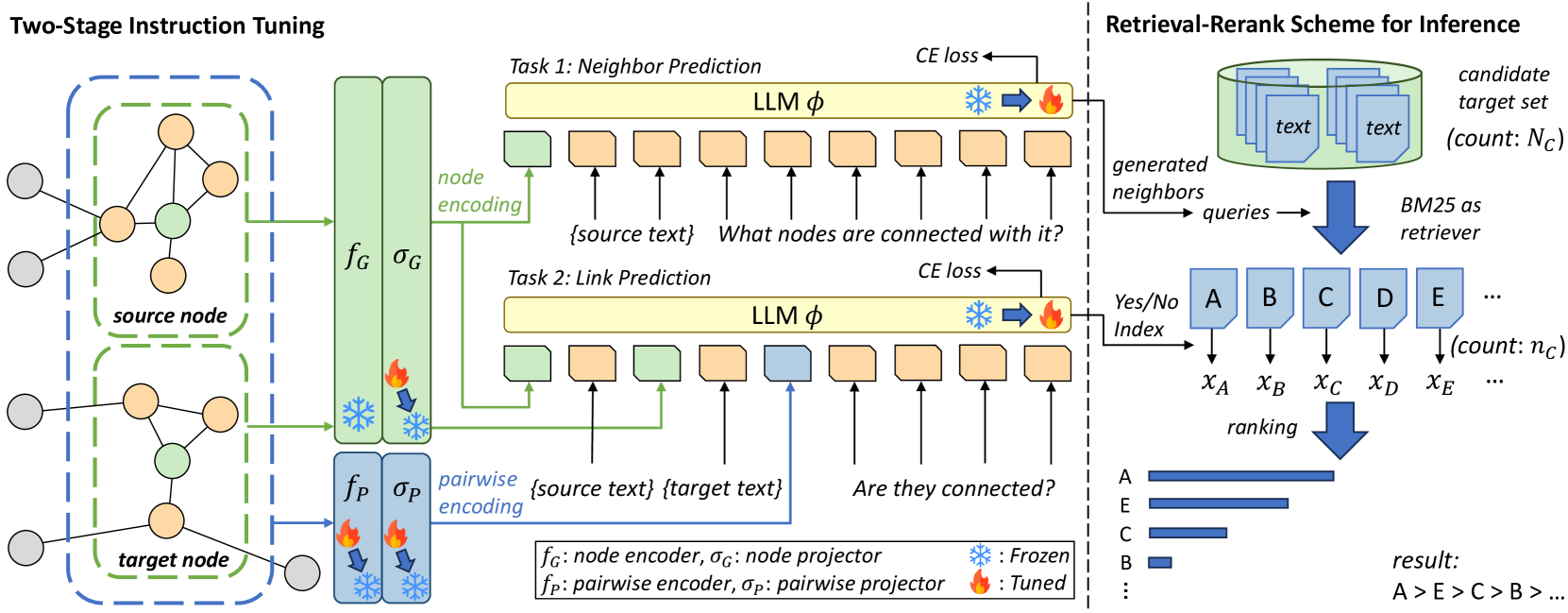
Large Language Models (LLMs) have shown promising results on various language and vision tasks. Recently, there has been growing interest in applying LLMs to graph-based tasks, particularly on Text-Attributed Graphs (TAGs). However, most studies have focused on node classification, while the use of LLMs for link prediction (LP) remains understudied. In this work, we propose a new task on LLMs, where the objective is to leverage LLMs to predict missing links between nodes in a graph. This task evaluates an LLM's ability to reason over structured data and infer new facts based on learned patterns. This new task poses two key challenges: (1) How to effectively integrate pairwise structural information into the LLMs, which is known to be crucial for LP performance, and (2) how to solve the computational bottleneck when teaching LLMs to perform LP. To address these challenges, we propose LinkGPT, the first end-to-end trained LLM for LP tasks. To effectively enhance the LLM's ability to understand the underlying structure, we design a two-stage instruction tuning approach where the first stage fine-tunes the pairwise encoder, projector, and node projector, and the second stage further fine-tunes the LLMs to predict links. To address the efficiency challenges at inference time, we introduce a retrieval-reranking scheme. Experiments show that LinkGPT can achieve state-of-the-art performance on real-world graphs as well as superior generalization in zero-shot and few-shot learning, surpassing existing benchmarks. At inference time, it can achieve $10times$ speedup while maintaining high LP accuracy.
Create account to get full access
Overview
- This paper, "LinkGPT: Teaching Large Language Models To Predict Missing Links", explores a novel approach to using large language models (LLMs) to predict missing links in graphs or networks.
- The researchers propose a framework called LinkGPT that fine-tunes LLMs to learn the structure and semantics of graph-structured data, enabling them to predict missing links between nodes.
- The paper evaluates LinkGPT on several benchmark datasets, demonstrating its effectiveness in link prediction tasks compared to existing methods.
Plain English Explanation
The paper discusses a way to teach large language models (GraphGPT, LLMs) how to predict missing connections or "links" between things in a graph or network. Graphs are used to model all kinds of interconnected data, like social networks, knowledge bases, and transportation systems.
The researchers developed a system called "LinkGPT" that takes a large language model and trains it to understand the structure and meaning of graph data. This allows the model to figure out what links are likely to be missing between different nodes (the things connected in the graph). For example, in a social network graph, LinkGPT could predict that two people are likely to be friends based on their existing connections and the overall network structure.
The paper shows that LinkGPT performs well on several standard benchmark tests for predicting missing links, outperforming other existing methods. This suggests that large language models can be effectively adapted to work with graph-structured data, opening up new possibilities for applying these powerful AI models to a wider range of problems involving interconnected information.
Technical Explanation
The key technical contributions of this paper are:
-
LinkGPT Framework: The authors propose a new framework called LinkGPT that fine-tunes large language models (Retrieval-Augmented Language Model for Extreme Multi-Label, Parameter-Efficient Tuning of Large Language Models for Graphs) to perform link prediction on graph-structured data. LinkGPT encodes the graph structure and node features into a sequence-to-sequence format that can be processed by the LLM.
-
Graph-Aware Pretraining: The authors introduce a graph-aware pretraining stage that teaches the LLM to understand basic graph properties and structures, before fine-tuning it on the specific link prediction task. This helps the model learn more effective representations of the graph data.
-
Evaluation: The paper evaluates LinkGPT on several benchmark link prediction datasets, including social networks, knowledge graphs, and biological networks. The results show that LinkGPT outperforms a range of existing graph neural network and embedding-based methods for link prediction.
-
Interpretability: The authors analyze the internal representations learned by LinkGPT, demonstrating that it can capture meaningful structural and semantic relationships within the graph data. This provides insights into how the model makes its predictions.
Critical Analysis
The paper makes a compelling case for using large language models for graph-structured data tasks like link prediction. The proposed LinkGPT framework is a well-designed and thorough approach, and the evaluation results are strong.
However, the paper does not address some potential limitations and areas for future work:
- The performance of LinkGPT likely depends on the quality and size of the pretraining data. The authors do not explore the sensitivity of their approach to the pretraining corpus.
- The paper focuses on link prediction, but LLMs could potentially be applied to a wider range of graph machine learning tasks. Exploring these other applications could further demonstrate the versatility of the approach.
- While the interpretability analysis provides some insights, more work could be done to fully understand how LinkGPT reasons about graph structures and makes its predictions.
Overall, this is a well-executed study that makes a valuable contribution to the emerging field of applying large language models to graph-structured data problems.
Conclusion
This paper introduces LinkGPT, a framework that teaches large language models to predict missing links in graph-structured data. By fine-tuning LLMs on a graph-aware pretraining stage, LinkGPT can effectively capture the structure and semantics of graph data, outperforming existing link prediction methods on several benchmark datasets.
The success of LinkGPT suggests that LLMs can be a powerful tool for a variety of graph-based tasks, beyond just link prediction. As large language models continue to advance, we can expect to see them applied to an increasingly wide range of problems involving interconnected, structured data. This work represents an important step in that direction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

GraphGPT: Graph Instruction Tuning for Large Language Models
Jiabin Tang, Yuhao Yang, Wei Wei, Lei Shi, Lixin Su, Suqi Cheng, Dawei Yin, Chao Huang
0
0
Graph Neural Networks (GNNs) have evolved to understand graph structures through recursive exchanges and aggregations among nodes. To enhance robustness, self-supervised learning (SSL) has become a vital tool for data augmentation. Traditional methods often depend on fine-tuning with task-specific labels, limiting their effectiveness when labeled data is scarce. Our research tackles this by advancing graph model generalization in zero-shot learning environments. Inspired by the success of large language models (LLMs), we aim to create a graph-oriented LLM capable of exceptional generalization across various datasets and tasks without relying on downstream graph data. We introduce the GraphGPT framework, which integrates LLMs with graph structural knowledge through graph instruction tuning. This framework includes a text-graph grounding component to link textual and graph structures and a dual-stage instruction tuning approach with a lightweight graph-text alignment projector. These innovations allow LLMs to comprehend complex graph structures and enhance adaptability across diverse datasets and tasks. Our framework demonstrates superior generalization in both supervised and zero-shot graph learning tasks, surpassing existing benchmarks. The open-sourced model implementation of our GraphGPT is available at https://github.com/HKUDS/GraphGPT.
5/8/2024
A Survey of Large Language Models for Graphs
Xubin Ren, Jiabin Tang, Dawei Yin, Nitesh Chawla, Chao Huang
0
0
Graphs are an essential data structure utilized to represent relationships in real-world scenarios. Prior research has established that Graph Neural Networks (GNNs) deliver impressive outcomes in graph-centric tasks, such as link prediction and node classification. Despite these advancements, challenges like data sparsity and limited generalization capabilities continue to persist. Recently, Large Language Models (LLMs) have gained attention in natural language processing. They excel in language comprehension and summarization. Integrating LLMs with graph learning techniques has attracted interest as a way to enhance performance in graph learning tasks. In this survey, we conduct an in-depth review of the latest state-of-the-art LLMs applied in graph learning and introduce a novel taxonomy to categorize existing methods based on their framework design. We detail four unique designs: i) GNNs as Prefix, ii) LLMs as Prefix, iii) LLMs-Graphs Integration, and iv) LLMs-Only, highlighting key methodologies within each category. We explore the strengths and limitations of each framework, and emphasize potential avenues for future research, including overcoming current integration challenges between LLMs and graph learning techniques, and venturing into new application areas. This survey aims to serve as a valuable resource for researchers and practitioners eager to leverage large language models in graph learning, and to inspire continued progress in this dynamic field. We consistently maintain the related open-source materials at url{https://github.com/HKUDS/Awesome-LLM4Graph-Papers}.
6/26/2024
💬
Retrieval-Augmented Language Model for Extreme Multi-Label Knowledge Graph Link Prediction
Yu-Hsiang Lin, Huang-Ting Shieh, Chih-Yu Liu, Kuang-Ting Lee, Hsiao-Cheng Chang, Jing-Lun Yang, Yu-Sheng Lin
0
0
Extrapolation in Large language models (LLMs) for open-ended inquiry encounters two pivotal issues: (1) hallucination and (2) expensive training costs. These issues present challenges for LLMs in specialized domains and personalized data, requiring truthful responses and low fine-tuning costs. Existing works attempt to tackle the problem by augmenting the input of a smaller language model with information from a knowledge graph (KG). However, they have two limitations: (1) failing to extract relevant information from a large one-hop neighborhood in KG and (2) applying the same augmentation strategy for KGs with different characteristics that may result in low performance. Moreover, open-ended inquiry typically yields multiple responses, further complicating extrapolation. We propose a new task, the extreme multi-label KG link prediction task, to enable a model to perform extrapolation with multiple responses using structured real-world knowledge. Our retriever identifies relevant one-hop neighbors by considering entity, relation, and textual data together. Our experiments demonstrate that (1) KGs with different characteristics require different augmenting strategies, and (2) augmenting the language model's input with textual data improves task performance significantly. By incorporating the retrieval-augmented framework with KG, our framework, with a small parameter size, is able to extrapolate based on a given KG. The code can be obtained on GitHub: https://github.com/exiled1143/Retrieval-Augmented-Language-Model-for-Multi-Label-Knowledge-Graph-Link-Prediction.git
5/22/2024
Parameter-Efficient Tuning Large Language Models for Graph Representation Learning
Qi Zhu, Da Zheng, Xiang Song, Shichang Zhang, Bowen Jin, Yizhou Sun, George Karypis
0
0
Text-rich graphs, which exhibit rich textual information on nodes and edges, are prevalent across a wide range of real-world business applications. Large Language Models (LLMs) have demonstrated remarkable abilities in understanding text, which also introduced the potential for more expressive modeling in text-rich graphs. Despite these capabilities, efficiently applying LLMs to representation learning on graphs presents significant challenges. Recently, parameter-efficient fine-tuning methods for LLMs have enabled efficient new task generalization with minimal time and memory consumption. Inspired by this, we introduce Graph-aware Parameter-Efficient Fine-Tuning - GPEFT, a novel approach for efficient graph representation learning with LLMs on text-rich graphs. Specifically, we utilize a graph neural network (GNN) to encode structural information from neighboring nodes into a graph prompt. This prompt is then inserted at the beginning of the text sequence. To improve the quality of graph prompts, we pre-trained the GNN to assist the frozen LLM in predicting the next token in the node text. Compared with existing joint GNN and LMs, our method directly generate the node embeddings from large language models with an affordable fine-tuning cost. We validate our approach through comprehensive experiments conducted on 8 different text-rich graphs, observing an average improvement of 2% in hit@1 and Mean Reciprocal Rank (MRR) in link prediction evaluations. Our results demonstrate the efficacy and efficiency of our model, showing that it can be smoothly integrated with various large language models, including OPT, LLaMA and Falcon.
4/30/2024