GraphGPT: Graph Instruction Tuning for Large Language Models
2310.13023
0
0

Abstract
Graph Neural Networks (GNNs) have evolved to understand graph structures through recursive exchanges and aggregations among nodes. To enhance robustness, self-supervised learning (SSL) has become a vital tool for data augmentation. Traditional methods often depend on fine-tuning with task-specific labels, limiting their effectiveness when labeled data is scarce. Our research tackles this by advancing graph model generalization in zero-shot learning environments. Inspired by the success of large language models (LLMs), we aim to create a graph-oriented LLM capable of exceptional generalization across various datasets and tasks without relying on downstream graph data. We introduce the GraphGPT framework, which integrates LLMs with graph structural knowledge through graph instruction tuning. This framework includes a text-graph grounding component to link textual and graph structures and a dual-stage instruction tuning approach with a lightweight graph-text alignment projector. These innovations allow LLMs to comprehend complex graph structures and enhance adaptability across diverse datasets and tasks. Our framework demonstrates superior generalization in both supervised and zero-shot graph learning tasks, surpassing existing benchmarks. The open-sourced model implementation of our GraphGPT is available at https://github.com/HKUDS/GraphGPT.
Create account to get full access
Overview
• GraphGPT is a technique that enables large language models to better understand and utilize graph-structured data.
• It does this by "tuning" the language model to follow instructions related to graph analysis and manipulation.
• This allows the language model to tackle a wider range of graph-related tasks, beyond just generating text.
Plain English Explanation
Large language models like GPT-3 are incredibly powerful at generating human-like text. However, they may struggle with tasks that involve structured data, like graphs. GraphGPT aims to address this by training the language model to follow instructions related to graphs.
For example, a user could ask the language model to "Find the shortest path between these two nodes in the graph." The model would then understand the graph-related concepts and be able to provide a relevant answer, rather than just generating generic text.
This "instruction tuning" approach allows the language model to acquire new capabilities beyond just text generation. It can now tackle a wider range of tasks, like graph analysis and domain-specific applications, by learning to follow instructions related to those areas.
Technical Explanation
The GraphGPT approach involves fine-tuning a large language model, such as GPT-3, on a dataset of graph-related instructions and their corresponding outputs. This trains the model to understand and execute tasks involving graph structures.
The key components of the methodology include:
- Structural Information: Encoding the graph structure and properties as part of the input, so the model can learn to leverage this information.
- Instruction Tuning: Fine-tuning the language model on a dataset of graph-related instructions, so it can learn to follow those types of commands.
- Task Execution: Evaluating the model's ability to execute various graph-related tasks, such as node classification, link prediction, and graph generation.
The researchers demonstrate that this approach allows the language model to acquire graph-related capabilities while maintaining its strong text generation performance.
Critical Analysis
The GraphGPT research shows promising results, but there are some potential limitations and areas for further exploration:
- The dataset used for instruction tuning may not capture the full breadth of graph-related tasks and instructions. Expanding the dataset could further enhance the model's capabilities.
- The paper focuses on relatively simple graph tasks. Applying GraphGPT to more complex, real-world graph problems would be an interesting next step.
- The long-term effects of this instruction tuning approach on the language model's broader capabilities and potential biases are not fully explored.
Overall, GraphGPT represents an exciting step towards bridging the gap between large language models and structured data, opening up new possibilities for their application in the era of large language models and graph machine learning.
Conclusion
GraphGPT demonstrates a novel approach to enhancing large language models like GPT-3 with graph-related capabilities. By fine-tuning the models on graph-specific instructions, they can acquire the ability to understand and manipulate graph structures, expanding their potential applications beyond just text generation.
This research highlights the ongoing efforts to integrate large language models and graph machine learning, unlocking new possibilities for the fine-tuning of large language models to tackle a wider range of structured data problems. As the field of large language models and graph analytics continues to evolve, techniques like GraphGPT will play an increasingly important role in advancing the capabilities of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Parameter-Efficient Tuning Large Language Models for Graph Representation Learning
Qi Zhu, Da Zheng, Xiang Song, Shichang Zhang, Bowen Jin, Yizhou Sun, George Karypis
0
0
Text-rich graphs, which exhibit rich textual information on nodes and edges, are prevalent across a wide range of real-world business applications. Large Language Models (LLMs) have demonstrated remarkable abilities in understanding text, which also introduced the potential for more expressive modeling in text-rich graphs. Despite these capabilities, efficiently applying LLMs to representation learning on graphs presents significant challenges. Recently, parameter-efficient fine-tuning methods for LLMs have enabled efficient new task generalization with minimal time and memory consumption. Inspired by this, we introduce Graph-aware Parameter-Efficient Fine-Tuning - GPEFT, a novel approach for efficient graph representation learning with LLMs on text-rich graphs. Specifically, we utilize a graph neural network (GNN) to encode structural information from neighboring nodes into a graph prompt. This prompt is then inserted at the beginning of the text sequence. To improve the quality of graph prompts, we pre-trained the GNN to assist the frozen LLM in predicting the next token in the node text. Compared with existing joint GNN and LMs, our method directly generate the node embeddings from large language models with an affordable fine-tuning cost. We validate our approach through comprehensive experiments conducted on 8 different text-rich graphs, observing an average improvement of 2% in hit@1 and Mean Reciprocal Rank (MRR) in link prediction evaluations. Our results demonstrate the efficacy and efficiency of our model, showing that it can be smoothly integrated with various large language models, including OPT, LLaMA and Falcon.
4/30/2024

HiGPT: Heterogeneous Graph Language Model
Jiabin Tang, Yuhao Yang, Wei Wei, Lei Shi, Long Xia, Dawei Yin, Chao Huang
0
0
Heterogeneous graph learning aims to capture complex relationships and diverse relational semantics among entities in a heterogeneous graph to obtain meaningful representations for nodes and edges. Recent advancements in heterogeneous graph neural networks (HGNNs) have achieved state-of-the-art performance by considering relation heterogeneity and using specialized message functions and aggregation rules. However, existing frameworks for heterogeneous graph learning have limitations in generalizing across diverse heterogeneous graph datasets. Most of these frameworks follow the pre-train and fine-tune paradigm on the same dataset, which restricts their capacity to adapt to new and unseen data. This raises the question: Can we generalize heterogeneous graph models to be well-adapted to diverse downstream learning tasks with distribution shifts in both node token sets and relation type heterogeneity?'' To tackle those challenges, we propose HiGPT, a general large graph model with Heterogeneous graph instruction-tuning paradigm. Our framework enables learning from arbitrary heterogeneous graphs without the need for any fine-tuning process from downstream datasets. To handle distribution shifts in heterogeneity, we introduce an in-context heterogeneous graph tokenizer that captures semantic relationships in different heterogeneous graphs, facilitating model adaptation. We incorporate a large corpus of heterogeneity-aware graph instructions into our HiGPT, enabling the model to effectively comprehend complex relation heterogeneity and distinguish between various types of graph tokens. Furthermore, we introduce the Mixture-of-Thought (MoT) instruction augmentation paradigm to mitigate data scarcity by generating diverse and informative instructions. Through comprehensive evaluations, our proposed framework demonstrates exceptional performance in terms of generalization performance.
5/21/2024
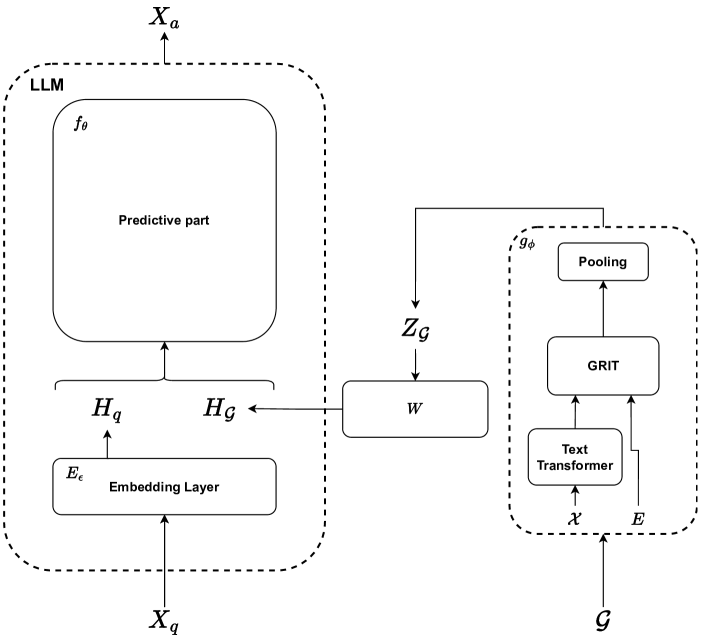
Joint Embeddings for Graph Instruction Tuning
Vlad Argatu, Aaron Haag, Oliver Lohse
0
0
Large Language Models (LLMs) have achieved impressive performance in text understanding and have become an essential tool for building smart assistants. Originally focusing on text, they have been enhanced with multimodal capabilities in recent works that successfully built visual instruction following assistants. As far as the graph modality goes, however, no such assistants have yet been developed. Graph structures are complex in that they represent relation between different features and are permutation invariant. Moreover, representing them in purely textual form does not always lead to good LLM performance even for finetuned models. As a result, there is a need to develop a new method to integrate graphs in LLMs for general graph understanding. This work explores the integration of the graph modality in LLM for general graph instruction following tasks. It aims at producing a deep learning model that enhances an underlying LLM with graph embeddings and trains it to understand them and to produce, given an instruction, an answer grounded in the graph representation. The approach performs significantly better than a graph to text approach and remains consistent even for larger graphs.
6/3/2024
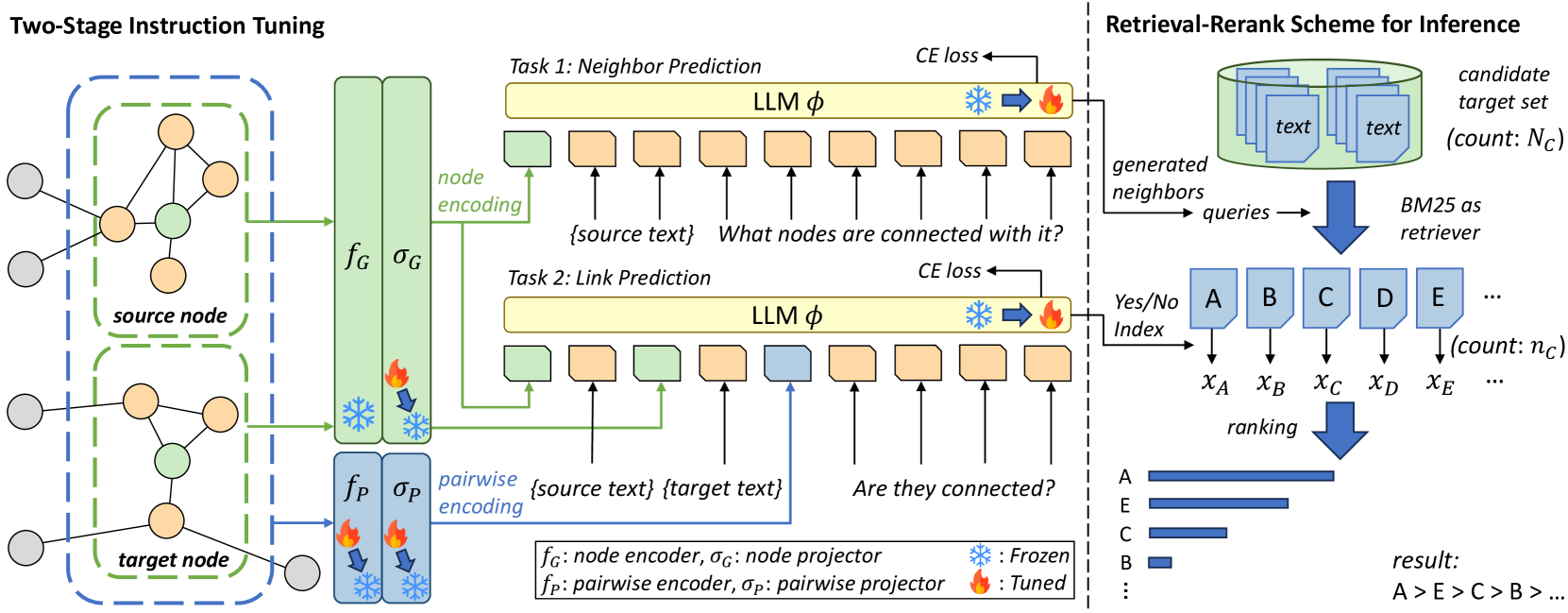
LinkGPT: Teaching Large Language Models To Predict Missing Links
Zhongmou He, Jing Zhu, Shengyi Qian, Joyce Chai, Danai Koutra
0
0
Large Language Models (LLMs) have shown promising results on various language and vision tasks. Recently, there has been growing interest in applying LLMs to graph-based tasks, particularly on Text-Attributed Graphs (TAGs). However, most studies have focused on node classification, while the use of LLMs for link prediction (LP) remains understudied. In this work, we propose a new task on LLMs, where the objective is to leverage LLMs to predict missing links between nodes in a graph. This task evaluates an LLM's ability to reason over structured data and infer new facts based on learned patterns. This new task poses two key challenges: (1) How to effectively integrate pairwise structural information into the LLMs, which is known to be crucial for LP performance, and (2) how to solve the computational bottleneck when teaching LLMs to perform LP. To address these challenges, we propose LinkGPT, the first end-to-end trained LLM for LP tasks. To effectively enhance the LLM's ability to understand the underlying structure, we design a two-stage instruction tuning approach where the first stage fine-tunes the pairwise encoder, projector, and node projector, and the second stage further fine-tunes the LLMs to predict links. To address the efficiency challenges at inference time, we introduce a retrieval-reranking scheme. Experiments show that LinkGPT can achieve state-of-the-art performance on real-world graphs as well as superior generalization in zero-shot and few-shot learning, surpassing existing benchmarks. At inference time, it can achieve $10times$ speedup while maintaining high LP accuracy.
6/10/2024