LLM Attributor: Interactive Visual Attribution for LLM Generation

0

Sign in to get full access
Overview
- This paper introduces LLM Attributor, an interactive visual tool for understanding the training data attribution of large language models (LLMs).
- LLM Attributor allows users to explore how different parts of a generated text are influenced by the model's training data.
- The tool provides visual feedback on the origins of text, helping users better understand and audit the capabilities and limitations of LLMs.
Plain English Explanation
LLM Attributor is a new tool that helps people understand where the text generated by large language models (LLMs) comes from. LLMs are AI systems trained on massive amounts of text data, and they can generate human-like text on a wide range of topics. However, it's not always clear how the model's training data influences the output.
LLM Attributor addresses this by providing an interactive visual interface. Users can input a piece of text generated by an LLM, and the tool will highlight different parts of the text, showing where the information likely came from in the model's training data. This allows users to explore the origins of the generated text and gain insights into the model's capabilities and limitations.
For example, if an LLM generates a paragraph about a historical event, LLM Attributor could indicate which sentences were likely derived from history textbooks in the training data, versus which sentences may have been pieced together from other sources like news articles or websites. This transparency helps users better understand how the model works and can lead to more informed use and interpretation of LLM outputs.
Technical Explanation
The LLM Attributor system works by leveraging recent advancements in large language model interpretability. It first uses techniques like attention visualization and gradient-based saliency mapping to identify which parts of the input text are most influential in generating the output. It then cross-references these influential text segments against the model's training data to determine the likely sources.
The tool presents this information visually, with the generated text highlighted and color-coded to indicate the inferred origins. Users can interact with the visualization, exploring how changes to the input affect the attributed sources. This allows for interactive investigation of the model's behavior and biases.
The paper describes the implementation of LLM Attributor and presents case studies demonstrating its use in understanding the outputs of prominent language models like GPT-3. The results show that the tool can provide valuable insights, helping users gain a more nuanced perspective on the capabilities and limitations of these powerful AI systems.
Critical Analysis
The authors acknowledge that LLM Attributor has some limitations. The tool relies on heuristic approaches to infer training data sources, which may not always be fully accurate. Additionally, the visualization techniques used could potentially overwhelm users with too much information, requiring careful design to maintain clarity.
Another potential issue is that the tool only provides insights into the origins of the generated text, without addressing higher-level questions of factual accuracy, coherence, or ethical implications. Users would still need to critically evaluate the overall quality and appropriateness of the LLM outputs.
That said, LLM Attributor represents an important step forward in LLM interpretability and transparency. By giving users a window into the model's inner workings, the tool empowers a more nuanced understanding and responsible use of these powerful AI systems. Further research could explore ways to expand the tool's capabilities and integrate it more deeply into LLM development and deployment workflows.
Conclusion
LLM Attributor is a valuable new tool that helps users understand the origins and biases of text generated by large language models. By providing interactive visual feedback on the training data sources underlying LLM outputs, the tool fosters a more transparent and informed use of these AI systems. As LLMs continue to advance and become more widely deployed, tools like LLM Attributor will be crucial for ensuring they are developed and applied responsibly.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LLM Attributor: Interactive Visual Attribution for LLM Generation
Seongmin Lee, Zijie J. Wang, Aishwarya Chakravarthy, Alec Helbling, ShengYun Peng, Mansi Phute, Duen Horng Chau, Minsuk Kahng
While large language models (LLMs) have shown remarkable capability to generate convincing text across diverse domains, concerns around its potential risks have highlighted the importance of understanding the rationale behind text generation. We present LLM Attributor, a Python library that provides interactive visualizations for training data attribution of an LLM's text generation. Our library offers a new way to quickly attribute an LLM's text generation to training data points to inspect model behaviors, enhance its trustworthiness, and compare model-generated text with user-provided text. We describe the visual and interactive design of our tool and highlight usage scenarios for LLaMA2 models fine-tuned with two different datasets: online articles about recent disasters and finance-related question-answer pairs. Thanks to LLM Attributor's broad support for computational notebooks, users can easily integrate it into their workflow to interactively visualize attributions of their models. For easier access and extensibility, we open-source LLM Attributor at https://github.com/poloclub/ LLM-Attribution. The video demo is available at https://youtu.be/mIG2MDQKQxM.
Read more4/3/2024
0
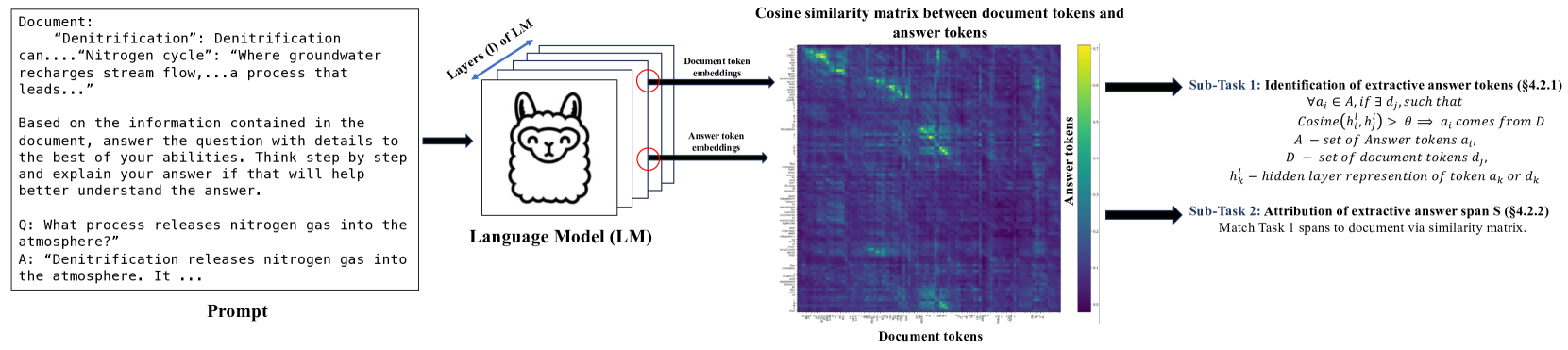
Peering into the Mind of Language Models: An Approach for Attribution in Contextual Question Answering
Anirudh Phukan, Shwetha Somasundaram, Apoorv Saxena, Koustava Goswami, Balaji Vasan Srinivasan
With the enhancement in the field of generative artificial intelligence (AI), contextual question answering has become extremely relevant. Attributing model generations to the input source document is essential to ensure trustworthiness and reliability. We observe that when large language models (LLMs) are used for contextual question answering, the output answer often consists of text copied verbatim from the input prompt which is linked together with glue text generated by the LLM. Motivated by this, we propose that LLMs have an inherent awareness from where the text was copied, likely captured in the hidden states of the LLM. We introduce a novel method for attribution in contextual question answering, leveraging the hidden state representations of LLMs. Our approach bypasses the need for extensive model retraining and retrieval model overhead, offering granular attributions and preserving the quality of generated answers. Our experimental results demonstrate that our method performs on par or better than GPT-4 at identifying verbatim copied segments in LLM generations and in attributing these segments to their source. Importantly, our method shows robust performance across various LLM architectures, highlighting its broad applicability. Additionally, we present Verifiability-granular, an attribution dataset which has token level annotations for LLM generations in the contextual question answering setup.
Read more5/29/2024
💬
0
Source Attribution for Large Language Model-Generated Data
Jingtan Wang, Xinyang Lu, Zitong Zhao, Zhongxiang Dai, Chuan-Sheng Foo, See-Kiong Ng, Bryan Kian Hsiang Low
The impressive performances of Large Language Models (LLMs) and their immense potential for commercialization have given rise to serious concerns over the Intellectual Property (IP) of their training data. In particular, the synthetic texts generated by LLMs may infringe the IP of the data being used to train the LLMs. To this end, it is imperative to be able to perform source attribution by identifying the data provider who contributed to the generation of a synthetic text by an LLM. In this paper, we show that this problem can be tackled by watermarking, i.e., by enabling an LLM to generate synthetic texts with embedded watermarks that contain information about their source(s). We identify the key properties of such watermarking frameworks (e.g., source attribution accuracy, robustness against adversaries), and propose a source attribution framework that satisfies these key properties due to our algorithmic designs. Our framework enables an LLM to learn an accurate mapping from the generated texts to data providers, which sets the foundation for effective source attribution. Extensive empirical evaluations show that our framework achieves effective source attribution.
Read more9/26/2024

0
GAugLLM: Improving Graph Contrastive Learning for Text-Attributed Graphs with Large Language Models
Yi Fang, Dongzhe Fan, Daochen Zha, Qiaoyu Tan
This work studies self-supervised graph learning for text-attributed graphs (TAGs) where nodes are represented by textual attributes. Unlike traditional graph contrastive methods that perturb the numerical feature space and alter the graph's topological structure, we aim to improve view generation through language supervision. This is driven by the prevalence of textual attributes in real applications, which complement graph structures with rich semantic information. However, this presents challenges because of two major reasons. First, text attributes often vary in length and quality, making it difficulty to perturb raw text descriptions without altering their original semantic meanings. Second, although text attributes complement graph structures, they are not inherently well-aligned. To bridge the gap, we introduce GAugLLM, a novel framework for augmenting TAGs. It leverages advanced large language models like Mistral to enhance self-supervised graph learning. Specifically, we introduce a mixture-of-prompt-expert technique to generate augmented node features. This approach adaptively maps multiple prompt experts, each of which modifies raw text attributes using prompt engineering, into numerical feature space. Additionally, we devise a collaborative edge modifier to leverage structural and textual commonalities, enhancing edge augmentation by examining or building connections between nodes. Empirical results across five benchmark datasets spanning various domains underscore our framework's ability to enhance the performance of leading contrastive methods as a plug-in tool. Notably, we observe that the augmented features and graph structure can also enhance the performance of standard generative methods, as well as popular graph neural networks. The open-sourced implementation of our GAugLLM is available at Github.
Read more6/19/2024