LLM-Based Robust Product Classification in Commerce and Compliance

0

Sign in to get full access
Overview
- Examines the use of large language models (LLMs) for robust product classification in commerce and compliance applications
- Focuses on improving the accuracy and robustness of product categorization, which is crucial for regulatory compliance and e-commerce workflows
- Proposes an LLM-based approach that leverages transfer learning to enhance performance and generalization
Plain English Explanation
This research paper explores the use of large language models (LLMs) for improving product classification in commerce and regulatory compliance. Product categorization is an essential task in e-commerce and regulatory compliance, as it helps ensure that products are properly identified and adhere to relevant laws and regulations.
The researchers recognized that existing product classification methods can sometimes struggle with accuracy and robustness, especially when dealing with the diverse and constantly evolving world of commercial products. To address this, they developed an LLM-based approach that leverages transfer learning to enhance the performance and generalization of the product classification system.
The key idea is to use the rich knowledge and language understanding capabilities of LLMs, which have been trained on vast amounts of text data, and adapt them to the specific task of product categorization. This allows the system to better handle the nuances and complexities of real-world product descriptions, ultimately improving the accuracy and robustness of the classification process.
Technical Explanation
The researchers proposed an LLM-based approach for robust product classification that consists of several key components:
-
LLM Fine-tuning: They started with a pre-trained LLM, such as BERT or GPT-3, and fine-tuned it on a large dataset of product descriptions and their corresponding category labels. This process allows the LLM to learn the associations between product text and their appropriate classifications.
-
Ensemble Modeling: To further improve the classification performance and robustness, the researchers explored using an ensemble of LLMs trained on different subsets of the data or with slightly different configurations. This ensemble approach combines the strengths of multiple models to achieve better overall accuracy.
-
Robust Loss Functions: The researchers experimented with different loss functions, including focal loss and adversarial training, to make the classification model more robust to noisy or adversarial inputs, further enhancing its real-world performance.
Through extensive experiments on various product classification benchmarks, the researchers demonstrated that their LLM-based approach significantly outperformed traditional machine learning methods, especially in terms of handling product descriptions that are ambiguous or contain rare, uncommon terms.
Critical Analysis
The researchers acknowledge several caveats and limitations of their work:
- The performance of the LLM-based approach is still dependent on the quality and diversity of the training data, which can be challenging to obtain and curate at scale.
- While the ensemble modeling and robust loss functions improve robustness, there may still be scenarios where the classification system struggles, such as when faced with completely novel product types or adversarial attacks.
- The computational and memory requirements of the LLM-based approach are generally higher than traditional machine learning models, which could be a concern for deployment in resource-constrained environments.
Additionally, the researchers do not address potential biases or fairness issues that may arise from the use of LLMs in product classification, which is an important consideration for real-world applications.
Conclusion
This research paper presents a promising approach for leveraging large language models to improve the accuracy and robustness of product classification in commerce and compliance applications. By fine-tuning LLMs and using ensemble modeling and robust loss functions, the researchers have demonstrated significant performance gains over traditional methods.
While the proposed approach has some limitations and caveats, it represents an important step forward in addressing the challenges of product categorization in the dynamic and complex world of e-commerce and regulatory compliance. As LLM research continues to advance, further improvements in this area could have far-reaching implications for businesses, consumers, and regulators alike.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LLM-Based Robust Product Classification in Commerce and Compliance
Sina Gholamian, Gianfranco Romani, Bartosz Rudnikowicz, Laura Skylaki
Product classification is a crucial task in international trade, as compliance regulations are verified and taxes and duties are applied based on product categories. Manual classification of products is time-consuming and error-prone, and the sheer volume of products imported and exported renders the manual process infeasible. Consequently, e-commerce platforms and enterprises involved in international trade have turned to automatic product classification using machine learning. However, current approaches do not consider the real-world challenges associated with product classification, such as very abbreviated and incomplete product descriptions. In addition, recent advancements in generative Large Language Models (LLMs) and their reasoning capabilities are mainly untapped in product classification and e-commerce. In this research, we explore the real-life challenges of industrial classification and we propose data perturbations that allow for realistic data simulation. Furthermore, we employ LLM-based product classification to improve the robustness of the prediction in presence of incomplete data. Our research shows that LLMs with in-context learning outperform the supervised approaches in the clean-data scenario. Additionally, we illustrate that LLMs are significantly more robust than the supervised approaches when data attacks are present.
Read more8/13/2024
👀
0
Investigating LLM Applications in E-Commerce
Chester Palen-Michel, Ruixiang Wang, Yipeng Zhang, David Yu, Canran Xu, Zhe Wu
The emergence of Large Language Models (LLMs) has revolutionized natural language processing in various applications especially in e-commerce. One crucial step before the application of such LLMs in these fields is to understand and compare the performance in different use cases in such tasks. This paper explored the efficacy of LLMs in the e-commerce domain, focusing on instruction-tuning an open source LLM model with public e-commerce datasets of varying sizes and comparing the performance with the conventional models prevalent in industrial applications. We conducted a comprehensive comparison between LLMs and traditional pre-trained language models across specific tasks intrinsic to the e-commerce domain, namely classification, generation, summarization, and named entity recognition (NER). Furthermore, we examined the effectiveness of the current niche industrial application of very large LLM, using in-context learning, in e-commerce specific tasks. Our findings indicate that few-shot inference with very large LLMs often does not outperform fine-tuning smaller pre-trained models, underscoring the importance of task-specific model optimization.Additionally, we investigated different training methodologies such as single-task training, mixed-task training, and LoRA merging both within domain/tasks and between different tasks. Through rigorous experimentation and analysis, this paper offers valuable insights into the potential effectiveness of LLMs to advance natural language processing capabilities within the e-commerce industry.
Read more8/26/2024
💬
0
A survey on fairness of large language models in e-commerce: progress, application, and challenge
Qingyang Ren, Zilin Jiang, Jinghan Cao, Sijia Li, Chiqu Li, Yiyang Liu, Shuning Huo, Tiange He, Yuan Chen
This survey explores the fairness of large language models (LLMs) in e-commerce, examining their progress, applications, and the challenges they face. LLMs have become pivotal in the e-commerce domain, offering innovative solutions and enhancing customer experiences. This work presents a comprehensive survey on the applications and challenges of LLMs in e-commerce. The paper begins by introducing the key principles underlying the use of LLMs in e-commerce, detailing the processes of pretraining, fine-tuning, and prompting that tailor these models to specific needs. It then explores the varied applications of LLMs in e-commerce, including product reviews, where they synthesize and analyze customer feedback; product recommendations, where they leverage consumer data to suggest relevant items; product information translation, enhancing global accessibility; and product question and answer sections, where they automate customer support. The paper critically addresses the fairness challenges in e-commerce, highlighting how biases in training data and algorithms can lead to unfair outcomes, such as reinforcing stereotypes or discriminating against certain groups. These issues not only undermine consumer trust, but also raise ethical and legal concerns. Finally, the work outlines future research directions, emphasizing the need for more equitable and transparent LLMs in e-commerce. It advocates for ongoing efforts to mitigate biases and improve the fairness of these systems, ensuring they serve diverse global markets effectively and ethically. Through this comprehensive analysis, the survey provides a holistic view of the current landscape of LLMs in e-commerce, offering insights into their potential and limitations, and guiding future endeavors in creating fairer and more inclusive e-commerce environments.
Read more6/26/2024
0
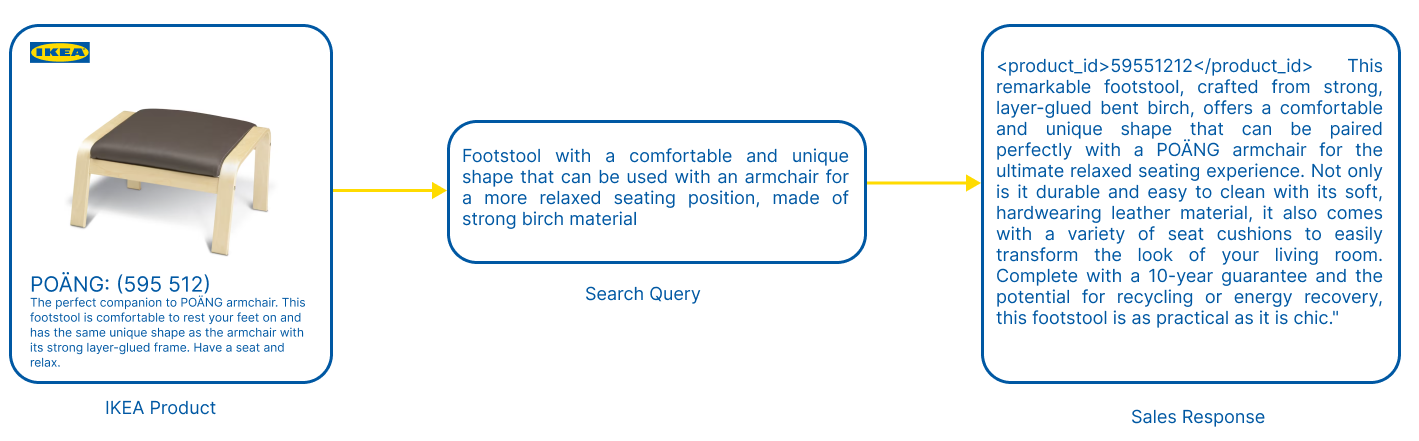
Learn by Selling: Equipping Large Language Models with Product Knowledge for Context-Driven Recommendations
Sarthak Anand, Yutong Jiang, Giorgi Kokaia
The rapid evolution of large language models (LLMs) has opened up new possibilities for applications such as context-driven product recommendations. However, the effectiveness of these models in this context is heavily reliant on their comprehensive understanding of the product inventory. This paper presents a novel approach to equipping LLMs with product knowledge by training them to respond contextually to synthetic search queries that include product IDs. We delve into an extensive analysis of this method, evaluating its effectiveness, outlining its benefits, and highlighting its constraints. The paper also discusses the potential improvements and future directions for this approach, providing a comprehensive understanding of the role of LLMs in product recommendations.
Read more7/31/2024