LLM Questionnaire Completion for Automatic Psychiatric Assessment
2406.06636
0
0

Abstract
We employ a Large Language Model (LLM) to convert unstructured psychological interviews into structured questionnaires spanning various psychiatric and personality domains. The LLM is prompted to answer these questionnaires by impersonating the interviewee. The obtained answers are coded as features, which are used to predict standardized psychiatric measures of depression (PHQ-8) and PTSD (PCL-C), using a Random Forest regressor. Our approach is shown to enhance diagnostic accuracy compared to multiple baselines. It thus establishes a novel framework for interpreting unstructured psychological interviews, bridging the gap between narrative-driven and data-driven approaches for mental health assessment.
Create account to get full access
Overview
- This paper provides a template for citing papers in the ArXiv style, which includes the author names, title, page numbers, and DOI.
- The template is generated using LaTeXML, a tool for converting LaTeX documents to HTML.
- The paper includes information about the HTML structure, CSS styles, and JavaScript used to create the template.
Plain English Explanation
This paper presents a template for citing research papers that have been published on the ArXiv preprint server. The template includes the key information that is typically included in a citation, such as the author names, the title of the paper, the page numbers, and the digital object identifier (DOI).
The template was created using a tool called LaTeXML, which is able to convert LaTeX documents, a common format for academic papers, into HTML. The paper provides details about the HTML structure, CSS styles, and JavaScript code that were used to generate the template. This information can be helpful for researchers or institutions that need to consistently format citations for ArXiv papers.
Technical Explanation
The paper describes a template for citing ArXiv papers in an HTML format. The template was generated using LaTeXML, a tool that can convert LaTeX documents into HTML. The HTML structure includes standard elements like the <head> and <body> tags, as well as links to external CSS and JavaScript files that provide styling and interactive features.
The CSS files referenced include styles for the Bootstrap framework, the ArXiv-specific styles, and custom styles for the LaTeXML output. The JavaScript files provide functionality for things like adding feedback overlays and generating screenshots of the page.
Overall, this template provides a consistent and standardized way to cite ArXiv papers in an HTML format, which can be useful for creating online bibliographies or including citations directly in web content.
Critical Analysis
The template provided in this paper offers a convenient way to format citations for ArXiv papers in a consistent and visually appealing way. However, it is important to note that this is a generic template and may need to be customized further for specific use cases or institutional requirements.
Additionally, while the use of external CSS and JavaScript libraries can enhance the styling and interactivity of the citations, it is important to ensure that these dependencies are properly managed and maintained over time. Relying on third-party resources that may become outdated or discontinued could potentially cause issues for users of the template in the future.
It would also be valuable for the authors to provide more guidance on how to integrate this template into existing workflows or content management systems. This could include sample code snippets or instructions for easily embedding the citations within web pages or other documents.
Conclusion
This paper presents a useful template for citing ArXiv papers in an HTML format. The template, which was generated using the LaTeXML tool, provides a consistent way to include key bibliographic information such as author names, titles, page numbers, and DOIs.
The template's use of external CSS and JavaScript libraries adds visual appeal and interactive features, but care must be taken to ensure the long-term sustainability of these dependencies. Additionally, the authors could provide more guidance on how to integrate the template into various workflows and content management systems.
Overall, this template can be a valuable resource for researchers, institutions, and anyone else who needs to consistently cite ArXiv papers on the web.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Automating PTSD Diagnostics in Clinical Interviews: Leveraging Large Language Models for Trauma Assessments
Sichang Tu, Abigail Powers, Natalie Merrill, Negar Fani, Sierra Carter, Stephen Doogan, Jinho D. Choi
0
0
The shortage of clinical workforce presents significant challenges in mental healthcare, limiting access to formal diagnostics and services. We aim to tackle this shortage by integrating a customized large language model (LLM) into the workflow, thus promoting equity in mental healthcare for the general population. Although LLMs have showcased their capability in clinical decision-making, their adaptation to severe conditions like Post-traumatic Stress Disorder (PTSD) remains largely unexplored. Therefore, we collect 411 clinician-administered diagnostic interviews and devise a novel approach to obtain high-quality data. Moreover, we build a comprehensive framework to automate PTSD diagnostic assessments based on interview contents by leveraging two state-of-the-art LLMs, GPT-4 and Llama-2, with potential for broader clinical diagnoses. Our results illustrate strong promise for LLMs, tested on our dataset, to aid clinicians in diagnostic validation. To the best of our knowledge, this is the first AI system that fully automates assessments for mental illness based on clinician-administered interviews.
5/21/2024
💬
Challenging the Validity of Personality Tests for Large Language Models
Tom Suhr, Florian E. Dorner, Samira Samadi, Augustin Kelava
0
0
With large language models (LLMs) like GPT-4 appearing to behave increasingly human-like in text-based interactions, it has become popular to attempt to evaluate personality traits of LLMs using questionnaires originally developed for humans. While reusing measures is a resource-efficient way to evaluate LLMs, careful adaptations are usually required to ensure that assessment results are valid even across human subpopulations. In this work, we provide evidence that LLMs' responses to personality tests systematically deviate from human responses, implying that the results of these tests cannot be interpreted in the same way. Concretely, reverse-coded items (I am introverted vs. I am extraverted) are often both answered affirmatively. Furthermore, variation across prompts designed to steer LLMs to simulate particular personality types does not follow the clear separation into five independent personality factors from human samples. In light of these results, we believe that it is important to investigate tests' validity for LLMs before drawing strong conclusions about potentially ill-defined concepts like LLMs' personality.
6/6/2024
🏷️
Limited Ability of LLMs to Simulate Human Psychological Behaviours: a Psychometric Analysis
Nikolay B Petrov, Gregory Serapio-Garc'ia, Jason Rentfrow
0
0
The humanlike responses of large language models (LLMs) have prompted social scientists to investigate whether LLMs can be used to simulate human participants in experiments, opinion polls and surveys. Of central interest in this line of research has been mapping out the psychological profiles of LLMs by prompting them to respond to standardized questionnaires. The conflicting findings of this research are unsurprising given that mapping out underlying, or latent, traits from LLMs' text responses to questionnaires is no easy task. To address this, we use psychometrics, the science of psychological measurement. In this study, we prompt OpenAI's flagship models, GPT-3.5 and GPT-4, to assume different personas and respond to a range of standardized measures of personality constructs. We used two kinds of persona descriptions: either generic (four or five random person descriptions) or specific (mostly demographics of actual humans from a large-scale human dataset). We found that the responses from GPT-4, but not GPT-3.5, using generic persona descriptions show promising, albeit not perfect, psychometric properties, similar to human norms, but the data from both LLMs when using specific demographic profiles, show poor psychometrics properties. We conclude that, currently, when LLMs are asked to simulate silicon personas, their responses are poor signals of potentially underlying latent traits. Thus, our work casts doubt on LLMs' ability to simulate individual-level human behaviour across multiple-choice question answering tasks.
5/14/2024
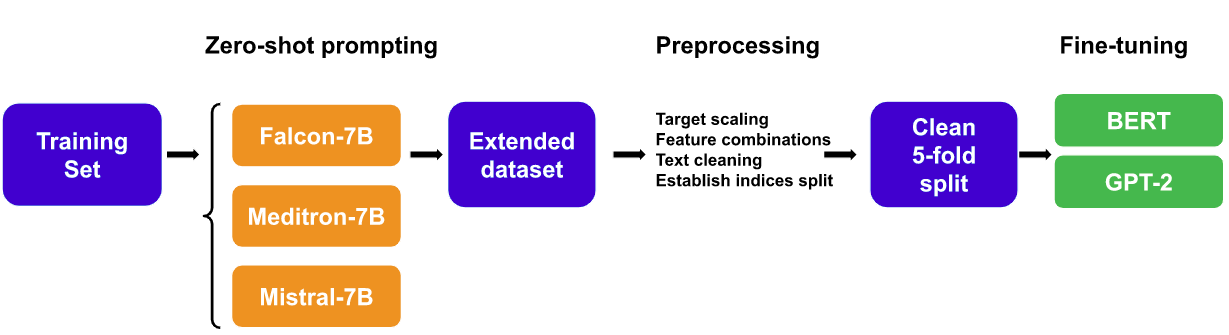
UnibucLLM: Harnessing LLMs for Automated Prediction of Item Difficulty and Response Time for Multiple-Choice Questions
Ana-Cristina Rogoz, Radu Tudor Ionescu
0
0
This work explores a novel data augmentation method based on Large Language Models (LLMs) for predicting item difficulty and response time of retired USMLE Multiple-Choice Questions (MCQs) in the BEA 2024 Shared Task. Our approach is based on augmenting the dataset with answers from zero-shot LLMs (Falcon, Meditron, Mistral) and employing transformer-based models based on six alternative feature combinations. The results suggest that predicting the difficulty of questions is more challenging. Notably, our top performing methods consistently include the question text, and benefit from the variability of LLM answers, highlighting the potential of LLMs for improving automated assessment in medical licensing exams. We make our code available https://github.com/ana-rogoz/BEA-2024.
4/23/2024