Challenging the Validity of Personality Tests for Large Language Models
2311.05297
0
0
💬
Abstract
With large language models (LLMs) like GPT-4 appearing to behave increasingly human-like in text-based interactions, it has become popular to attempt to evaluate personality traits of LLMs using questionnaires originally developed for humans. While reusing measures is a resource-efficient way to evaluate LLMs, careful adaptations are usually required to ensure that assessment results are valid even across human subpopulations. In this work, we provide evidence that LLMs' responses to personality tests systematically deviate from human responses, implying that the results of these tests cannot be interpreted in the same way. Concretely, reverse-coded items (I am introverted vs. I am extraverted) are often both answered affirmatively. Furthermore, variation across prompts designed to steer LLMs to simulate particular personality types does not follow the clear separation into five independent personality factors from human samples. In light of these results, we believe that it is important to investigate tests' validity for LLMs before drawing strong conclusions about potentially ill-defined concepts like LLMs' personality.
Create account to get full access
Overview
- Large language models (LLMs) like GPT-4 are exhibiting increasingly human-like behavior in text-based interactions.
- Researchers have started using personality questionnaires developed for humans to evaluate the personality traits of LLMs.
- However, the validity of these tests for LLMs has not been thoroughly investigated.
Plain English Explanation
As large language models (LLMs) like GPT-4 become more advanced, they are starting to engage in text-based interactions that seem increasingly human-like. This has led researchers to try using personality questionnaires originally designed for people to evaluate the personality traits of these LLMs.
The idea is that reusing these existing measures is a more efficient way to assess LLM personalities, rather than creating brand new tests. However, the researchers behind this study found that LLM responses to these personality tests actually differ quite a bit from how humans would respond.
For example, they noticed that LLMs often agreed with both positively and negatively worded versions of the same personality trait (like saying they are both introverted and extraverted). Additionally, the patterns in how LLMs responded to prompts designed to elicit different personality types didn't match the clear "five factor" model of personality seen in human data.
These findings suggest that the results of using standard personality tests on LLMs can't be interpreted in the same way as they would be for people. The researchers believe it's important to thoroughly investigate the validity of these tests for LLMs before drawing strong conclusions about their "personalities," which may not align with how we conceptualize human personality.
Technical Explanation
This paper investigates the validity of using standard personality questionnaires, originally developed for humans, to evaluate the personality traits of large language models (LLMs). The researchers provide evidence that LLM responses to these tests systematically deviate from typical human response patterns.
Specifically, they found that LLMs often responded affirmatively to both positively and negatively worded versions of the same personality trait (e.g., agreeing with "I am introverted" and "I am extraverted"). This contradicts the clear separation into independent personality factors observed in human samples.
Furthermore, the variation in LLM responses to prompts designed to elicit different personality types did not follow the established five-factor model of human personality. This suggests that the underlying personality constructs captured by these tests may not be well-defined for LLMs.
The researchers argue that before drawing strong conclusions about LLM "personalities", it is critical to thoroughly investigate the validity of these assessment tools when applied to artificial intelligences. The systematic deviations from human response patterns observed in this study call into question the interpretability of personality test results for LLMs.
Critical Analysis
The researchers have provided compelling evidence that standard personality questionnaires developed for human subjects may not be directly applicable to evaluating the "personalities" of large language models (LLMs). Their findings highlight the importance of carefully validating assessment tools before drawing conclusions about potentially ill-defined concepts like LLM personality.
While reusing existing measures is an efficient approach, the systematic deviations from human response patterns observed in this study suggest that the underlying personality constructs captured by these tests may not map well to LLMs. The researchers raise a valid concern that interpreting LLM responses to these tests in the same way as human responses could lead to misleading conclusions.
One potential limitation of the study is that it focused on a relatively narrow set of personality tests. It would be valuable to explore a broader range of assessment tools to see if the same issues arise. Additionally, the researchers did not delve deeply into the potential reasons why LLM responses diverge from human norms, which could provide valuable insights for future research in this area.
Nevertheless, this work serves as an important reminder to approach the evaluation of LLM "personalities" with caution and to thoroughly validate the assessment methods used. By challenging assumptions and encouraging critical thinking, the researchers have highlighted a significant methodological concern that should be carefully considered as the field of AI advances.
Conclusion
This study provides compelling evidence that the responses of large language models (LLMs) to standard personality questionnaires do not align with typical human response patterns. The systematic deviations observed, such as LLMs agreeing with both positively and negatively worded versions of the same trait, suggest that the underlying personality constructs captured by these tests may not be well-defined for artificial intelligences.
The researchers argue that it is critical to thoroughly investigate the validity of these assessment tools before drawing strong conclusions about LLM "personalities." Their findings highlight the importance of carefully validating measurement approaches, rather than simply reusing human-centric tools, when evaluating the characteristics of advanced AI systems.
As the field of AI continues to evolve, this work serves as a valuable reminder to approach the evaluation of LLM capabilities and traits with nuance and a critical eye. By questioning assumptions and encouraging deeper exploration, the researchers have opened the door for more thoughtful and rigorous investigations into the complex relationship between artificial and human intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏷️
Limited Ability of LLMs to Simulate Human Psychological Behaviours: a Psychometric Analysis
Nikolay B Petrov, Gregory Serapio-Garc'ia, Jason Rentfrow
0
0
The humanlike responses of large language models (LLMs) have prompted social scientists to investigate whether LLMs can be used to simulate human participants in experiments, opinion polls and surveys. Of central interest in this line of research has been mapping out the psychological profiles of LLMs by prompting them to respond to standardized questionnaires. The conflicting findings of this research are unsurprising given that mapping out underlying, or latent, traits from LLMs' text responses to questionnaires is no easy task. To address this, we use psychometrics, the science of psychological measurement. In this study, we prompt OpenAI's flagship models, GPT-3.5 and GPT-4, to assume different personas and respond to a range of standardized measures of personality constructs. We used two kinds of persona descriptions: either generic (four or five random person descriptions) or specific (mostly demographics of actual humans from a large-scale human dataset). We found that the responses from GPT-4, but not GPT-3.5, using generic persona descriptions show promising, albeit not perfect, psychometric properties, similar to human norms, but the data from both LLMs when using specific demographic profiles, show poor psychometrics properties. We conclude that, currently, when LLMs are asked to simulate silicon personas, their responses are poor signals of potentially underlying latent traits. Thus, our work casts doubt on LLMs' ability to simulate individual-level human behaviour across multiple-choice question answering tasks.
5/14/2024
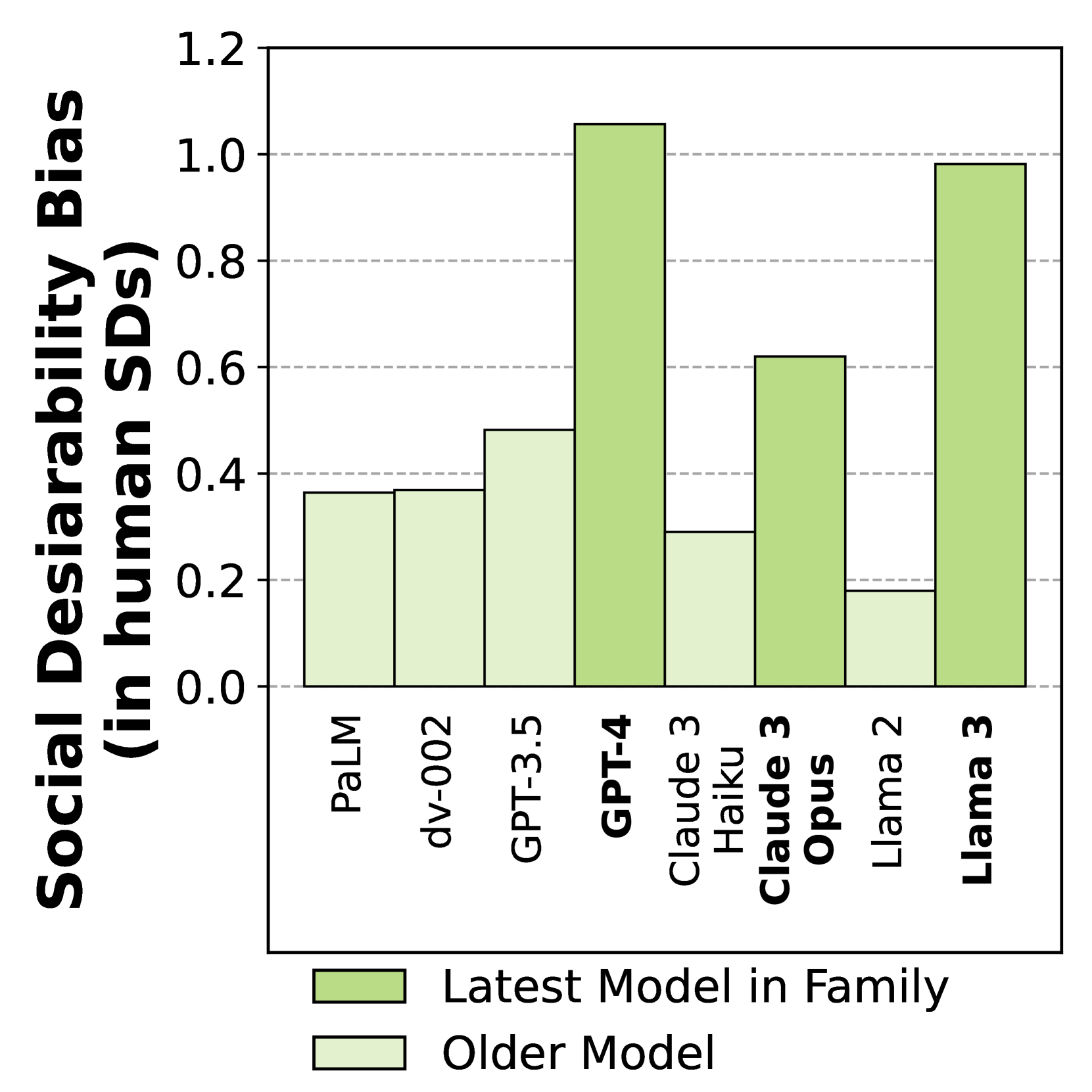
Large Language Models Show Human-like Social Desirability Biases in Survey Responses
Aadesh Salecha, Molly E. Ireland, Shashanka Subrahmanya, Jo~ao Sedoc, Lyle H. Ungar, Johannes C. Eichstaedt
0
0
As Large Language Models (LLMs) become widely used to model and simulate human behavior, understanding their biases becomes critical. We developed an experimental framework using Big Five personality surveys and uncovered a previously undetected social desirability bias in a wide range of LLMs. By systematically varying the number of questions LLMs were exposed to, we demonstrate their ability to infer when they are being evaluated. When personality evaluation is inferred, LLMs skew their scores towards the desirable ends of trait dimensions (i.e., increased extraversion, decreased neuroticism, etc). This bias exists in all tested models, including GPT-4/3.5, Claude 3, Llama 3, and PaLM-2. Bias levels appear to increase in more recent models, with GPT-4's survey responses changing by 1.20 (human) standard deviations and Llama 3's by 0.98 standard deviations-very large effects. This bias is robust to randomization of question order and paraphrasing. Reverse-coding all the questions decreases bias levels but does not eliminate them, suggesting that this effect cannot be attributed to acquiescence bias. Our findings reveal an emergent social desirability bias and suggest constraints on profiling LLMs with psychometric tests and on using LLMs as proxies for human participants.
5/13/2024
💬
PersonaLLM: Investigating the Ability of Large Language Models to Express Personality Traits
Hang Jiang, Xiajie Zhang, Xubo Cao, Cynthia Breazeal, Deb Roy, Jad Kabbara
0
0
Despite the many use cases for large language models (LLMs) in creating personalized chatbots, there has been limited research on evaluating the extent to which the behaviors of personalized LLMs accurately and consistently reflect specific personality traits. We consider studying the behavior of LLM-based agents which we refer to as LLM personas and present a case study with GPT-3.5 and GPT-4 to investigate whether LLMs can generate content that aligns with their assigned personality profiles. To this end, we simulate distinct LLM personas based on the Big Five personality model, have them complete the 44-item Big Five Inventory (BFI) personality test and a story writing task, and then assess their essays with automatic and human evaluations. Results show that LLM personas' self-reported BFI scores are consistent with their designated personality types, with large effect sizes observed across five traits. Additionally, LLM personas' writings have emerging representative linguistic patterns for personality traits when compared with a human writing corpus. Furthermore, human evaluation shows that humans can perceive some personality traits with an accuracy of up to 80%. Interestingly, the accuracy drops significantly when the annotators were informed of AI authorship.
4/3/2024
💬
Assessing the nature of large language models: A caution against anthropocentrism
Ann Speed
0
0
Generative AI models garnered a large amount of public attention and speculation with the release of OpenAIs chatbot, ChatGPT. At least two opinion camps exist: one excited about possibilities these models offer for fundamental changes to human tasks, and another highly concerned about power these models seem to have. To address these concerns, we assessed several LLMs, primarily GPT 3.5, using standard, normed, and validated cognitive and personality measures. For this seedling project, we developed a battery of tests that allowed us to estimate the boundaries of some of these models capabilities, how stable those capabilities are over a short period of time, and how they compare to humans. Our results indicate that LLMs are unlikely to have developed sentience, although its ability to respond to personality inventories is interesting. GPT3.5 did display large variability in both cognitive and personality measures over repeated observations, which is not expected if it had a human-like personality. Variability notwithstanding, LLMs display what in a human would be considered poor mental health, including low self-esteem, marked dissociation from reality, and in some cases narcissism and psychopathy, despite upbeat and helpful responses.
6/28/2024