LLMs Know What They Need: Leveraging a Missing Information Guided Framework to Empower Retrieval-Augmented Generation
2404.14043
0
0
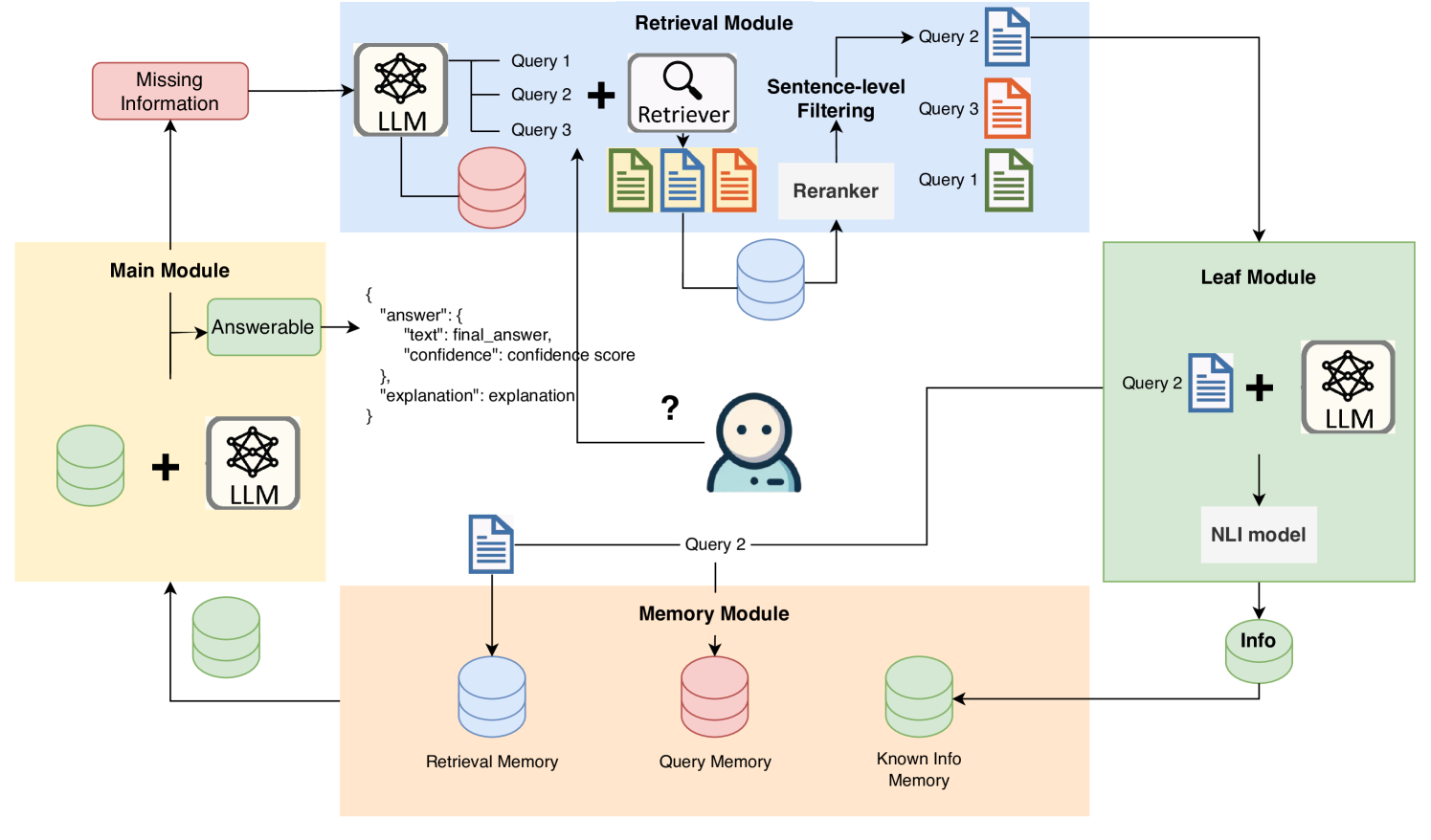
Abstract
Retrieval-Augmented Generation (RAG) demonstrates great value in alleviating outdated knowledge or hallucination by supplying LLMs with updated and relevant knowledge. However, there are still several difficulties for RAG in understanding complex multi-hop query and retrieving relevant documents, which require LLMs to perform reasoning and retrieve step by step. Inspired by human's reasoning process in which they gradually search for the required information, it is natural to ask whether the LLMs could notice the missing information in each reasoning step. In this work, we first experimentally verified the ability of LLMs to extract information as well as to know the missing. Based on the above discovery, we propose a Missing Information Guided Retrieve-Extraction-Solving paradigm (MIGRES), where we leverage the identification of missing information to generate a targeted query that steers the subsequent knowledge retrieval. Besides, we design a sentence-level re-ranking filtering approach to filter the irrelevant content out from document, along with the information extraction capability of LLMs to extract useful information from cleaned-up documents, which in turn to bolster the overall efficacy of RAG. Extensive experiments conducted on multiple public datasets reveal the superiority of the proposed MIGRES method, and analytical experiments demonstrate the effectiveness of our proposed modules.
Create account to get full access
Overview
- This paper explores a new framework called "Missing Information Guided" (MIG) that aims to improve the performance of retrieval-augmented generation (RAG) models.
- The key idea is to leverage the language model's own assessment of its knowledge gaps to guide the retrieval process and enhance the overall performance of the RAG system.
- The authors conduct several experiments to validate the effectiveness of the MIG framework and compare it to traditional RAG approaches.
Plain English Explanation
The paper's main focus is on a new technique called "Missing Information Guided" (MIG) that can help improve the performance of a type of AI model called a "retrieval-augmented generation" (RAG) model. RAG models combine a language model (which can generate human-like text) with a retrieval system (which can find relevant information from a database) to answer questions or complete tasks.
The key insight behind MIG is that the language model itself often knows when it is missing important information needed to answer a question or complete a task. By using this self-awareness of its own knowledge gaps, the MIG framework can guide the retrieval system to find the most relevant information to fill those gaps. This can lead to better overall performance compared to traditional RAG approaches.
The researchers conduct several experiments to test the MIG framework and compare it to other RAG techniques. They find that the MIG approach is effective in improving the performance of RAG models on various tasks.
Technical Explanation
The paper proposes a new framework called "Missing Information Guided" (MIG) to enhance the performance of retrieval-augmented generation (RAG) models. RAG models combine a language model, which can generate human-like text, with a retrieval system, which can find relevant information from a database, to tackle tasks like question answering.
The key innovation of the MIG framework is to leverage the language model's own assessment of its knowledge gaps to guide the retrieval process. The authors hypothesize that the language model can often identify what information it is missing to fully answer a question or complete a task. By using this self-awareness of knowledge gaps, the MIG framework can direct the retrieval system to find the most relevant information to fill those gaps, leading to improved overall performance.
The authors conduct several experiments to validate the effectiveness of the MIG framework. They compare the MIG approach to traditional RAG models on various tasks, such as [internal link: https://aimodels.fyi/papers/arxiv/improving-retrieval-rag-based-question-answering-models] question answering and [internal link: https://aimodels.fyi/papers/arxiv/unlocking-multi-view-insights-knowledge-dense-retrieval] knowledge-dense retrieval. The results show that the MIG framework can significantly outperform traditional RAG models, suggesting that enabling the language model to guide the retrieval process is a promising direction for improving retrieval-augmented generation.
Critical Analysis
The paper presents a thoughtful and well-designed approach to improving RAG models through the MIG framework. However, the authors acknowledge several limitations and areas for further research.
One potential issue is that the MIG framework relies on the language model's ability to accurately assess its own knowledge gaps, which may not always be reliable. [internal link: https://aimodels.fyi/papers/arxiv/how-faithful-are-rag-models-quantifying-tug] The paper mentions the need for further research on the faithfulness of language models in identifying their own limitations.
Additionally, the paper focuses on specific tasks like question answering and knowledge-dense retrieval. It would be valuable to see how the MIG framework performs on a broader range of applications, such as [internal link: https://aimodels.fyi/papers/arxiv/blended-rag-improving-rag-retriever-augmented-generation] generation tasks or [internal link: https://aimodels.fyi/papers/arxiv/improving-medical-reasoning-through-retrieval-self-reflection] tasks that require multi-step reasoning or self-reflection.
Overall, the MIG framework is a promising approach that could significantly improve the performance of RAG models. However, further research is needed to address the potential limitations and explore the broader applicability of this technique.
Conclusion
The paper introduces a new "Missing Information Guided" (MIG) framework for improving retrieval-augmented generation (RAG) models. The key innovation is to leverage the language model's own assessment of its knowledge gaps to guide the retrieval process, leading to better overall performance compared to traditional RAG approaches.
The experiments conducted in the paper demonstrate the effectiveness of the MIG framework on tasks like question answering and knowledge-dense retrieval. While the approach shows promise, the authors also identify areas for further research, such as investigating the faithfulness of language models in identifying their own limitations and exploring the framework's performance on a broader range of applications.
Overall, the MIG framework represents a significant step forward in enhancing the capabilities of RAG models, with the potential to unlock new possibilities in areas like question answering, knowledge management, and decision support.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

R^2AG: Incorporating Retrieval Information into Retrieval Augmented Generation
Fuda Ye, Shuangyin Li, Yongqi Zhang, Lei Chen
0
0
Retrieval augmented generation (RAG) has been applied in many scenarios to augment large language models (LLMs) with external documents provided by retrievers. However, a semantic gap exists between LLMs and retrievers due to differences in their training objectives and architectures. This misalignment forces LLMs to passively accept the documents provided by the retrievers, leading to incomprehension in the generation process, where the LLMs are burdened with the task of distinguishing these documents using their inherent knowledge. This paper proposes R$^2$AG, a novel enhanced RAG framework to fill this gap by incorporating Retrieval information into Retrieval Augmented Generation. Specifically, R$^2$AG utilizes the nuanced features from the retrievers and employs a R$^2$-Former to capture retrieval information. Then, a retrieval-aware prompting strategy is designed to integrate retrieval information into LLMs' generation. Notably, R$^2$AG suits low-source scenarios where LLMs and retrievers are frozen. Extensive experiments across five datasets validate the effectiveness, robustness, and efficiency of R$^2$AG. Our analysis reveals that retrieval information serves as an anchor to aid LLMs in the generation process, thereby filling the semantic gap.
6/21/2024
Improving Retrieval for RAG based Question Answering Models on Financial Documents
Spurthi Setty, Katherine Jijo, Eden Chung, Natan Vidra
0
0
The effectiveness of Large Language Models (LLMs) in generating accurate responses relies heavily on the quality of input provided, particularly when employing Retrieval Augmented Generation (RAG) techniques. RAG enhances LLMs by sourcing the most relevant text chunk(s) to base queries upon. Despite the significant advancements in LLMs' response quality in recent years, users may still encounter inaccuracies or irrelevant answers; these issues often stem from suboptimal text chunk retrieval by RAG rather than the inherent capabilities of LLMs. To augment the efficacy of LLMs, it is crucial to refine the RAG process. This paper explores the existing constraints of RAG pipelines and introduces methodologies for enhancing text retrieval. It delves into strategies such as sophisticated chunking techniques, query expansion, the incorporation of metadata annotations, the application of re-ranking algorithms, and the fine-tuning of embedding algorithms. Implementing these approaches can substantially improve the retrieval quality, thereby elevating the overall performance and reliability of LLMs in processing and responding to queries.
4/12/2024
💬
A Survey on RAG Meets LLMs: Towards Retrieval-Augmented Large Language Models
Wenqi Fan, Yujuan Ding, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat-Seng Chua, Qing Li
0
0
As one of the most advanced techniques in AI, Retrieval-Augmented Generation (RAG) can offer reliable and up-to-date external knowledge, providing huge convenience for numerous tasks. Particularly in the era of AI-Generated Content (AIGC), the powerful capacity of retrieval in providing additional knowledge enables RAG to assist existing generative AI in producing high-quality outputs. Recently, Large Language Models (LLMs) have demonstrated revolutionary abilities in language understanding and generation, while still facing inherent limitations, such as hallucinations and out-of-date internal knowledge. Given the powerful abilities of RAG in providing the latest and helpful auxiliary information, Retrieval-Augmented Large Language Models (RA-LLMs) have emerged to harness external and authoritative knowledge bases, rather than solely relying on the model's internal knowledge, to augment the generation quality of LLMs. In this survey, we comprehensively review existing research studies in RA-LLMs, covering three primary technical perspectives: architectures, training strategies, and applications. As the preliminary knowledge, we briefly introduce the foundations and recent advances of LLMs. Then, to illustrate the practical significance of RAG for LLMs, we systematically review mainstream relevant work by their architectures, training strategies, and application areas, detailing specifically the challenges of each and the corresponding capabilities of RA-LLMs. Finally, to deliver deeper insights, we discuss current limitations and several promising directions for future research. Updated information about this survey can be found at https://advanced-recommender-systems.github.io/RAG-Meets-LLMs/
6/18/2024

Unlocking Multi-View Insights in Knowledge-Dense Retrieval-Augmented Generation
Guanhua Chen, Wenhan Yu, Lei Sha
0
0
While Retrieval-Augmented Generation (RAG) plays a crucial role in the application of Large Language Models (LLMs), existing retrieval methods in knowledge-dense domains like law and medicine still suffer from a lack of multi-perspective views, which are essential for improving interpretability and reliability. Previous research on multi-view retrieval often focused solely on different semantic forms of queries, neglecting the expression of specific domain knowledge perspectives. This paper introduces a novel multi-view RAG framework, MVRAG, tailored for knowledge-dense domains that utilizes intention-aware query rewriting from multiple domain viewpoints to enhance retrieval precision, thereby improving the effectiveness of the final inference. Experiments conducted on legal and medical case retrieval demonstrate significant improvements in recall and precision rates with our framework. Our multi-perspective retrieval approach unleashes the potential of multi-view information enhancing RAG tasks, accelerating the further application of LLMs in knowledge-intensive fields.
4/22/2024