R^2AG: Incorporating Retrieval Information into Retrieval Augmented Generation
2406.13249
0
0

Abstract
Retrieval augmented generation (RAG) has been applied in many scenarios to augment large language models (LLMs) with external documents provided by retrievers. However, a semantic gap exists between LLMs and retrievers due to differences in their training objectives and architectures. This misalignment forces LLMs to passively accept the documents provided by the retrievers, leading to incomprehension in the generation process, where the LLMs are burdened with the task of distinguishing these documents using their inherent knowledge. This paper proposes R$^2$AG, a novel enhanced RAG framework to fill this gap by incorporating Retrieval information into Retrieval Augmented Generation. Specifically, R$^2$AG utilizes the nuanced features from the retrievers and employs a R$^2$-Former to capture retrieval information. Then, a retrieval-aware prompting strategy is designed to integrate retrieval information into LLMs' generation. Notably, R$^2$AG suits low-source scenarios where LLMs and retrievers are frozen. Extensive experiments across five datasets validate the effectiveness, robustness, and efficiency of R$^2$AG. Our analysis reveals that retrieval information serves as an anchor to aid LLMs in the generation process, thereby filling the semantic gap.
Create account to get full access
Related Works
Retrieval-Augmented Generation
Retrieval-augmented generation (RAG) is a technique that combines language models with information retrieval to improve the performance of natural language generation tasks. The evaluation-retrieval-augmented-generation-survey paper provides a comprehensive survey of RAG models and their applications.
Collaborative Retrieval-Augmented Generation
The duetrag-collaborative-retrieval-augmented-generation paper explores a collaborative approach to retrieval-augmented generation, where the retriever and generator work together to produce high-quality outputs.
Blended Retrieval-Augmented Generation
The blended-rag-improving-rag-retriever-augmented-generation paper presents a "blended" RAG model that combines the strengths of different retrieval and generation approaches.
Retrieval-Augmented Generation Surveys
The retrieval-augmented-generation-ai-generated-content-survey and unveil-duality-retrieval-augmented-generation-theoretical-analysis papers provide valuable overviews of the state of the art in retrieval-augmented generation and its theoretical foundations.
Overview
The R2AG paper explores a novel approach to incorporating retrieval information into retrieval-augmented generation models. The key idea is to use the retrieval output as a form of "guidance" for the generation process, which can lead to improvements in the coherence and relevance of the generated text.
Plain English Explanation
Retrieval-augmented generation (RAG) is a technique that combines language models, which generate text, with information retrieval, which finds relevant information from a database. The R2AG paper proposes a new way to incorporate the retrieval information into the generation process.
The core idea is to use the output of the retrieval system as a form of "guidance" for the language model. This means that the language model uses the retrieved information to help it generate more coherent and relevant text. For example, if the retrieval system finds information about a particular topic, the language model can use that information to generate text that is more focused and on-topic.
This approach can lead to improvements in the quality and relevance of the generated text, which is important for applications like question-answering, summarization, and content generation.
Technical Explanation
The R2AG paper introduces a novel architecture that incorporates retrieval information into the retrieval-augmented generation process. The key components of the R2AG model are:
- Retriever: The retriever module is responsible for finding relevant information from a database given an input query.
- Generator: The generator module is a language model that uses the retrieved information to generate coherent and relevant text.
- Retrieval-to-Generation (R2G) Module: This is the core innovation of the R2AG model. The R2G module takes the retrieval output and transforms it into a form that can be used as guidance for the language model during the generation process.
The R2AG model is trained end-to-end, where the retriever, R2G module, and generator are optimized jointly to produce high-quality outputs. The authors demonstrate the effectiveness of their approach on several benchmark datasets, showing improvements over traditional RAG models.
Critical Analysis
The R2AG paper presents a promising approach to improving retrieval-augmented generation, but there are a few potential limitations and areas for further research:
-
Scalability: The R2AG model relies on a separate retriever module, which may not be scalable to very large knowledge bases or databases. Exploring ways to integrate the retrieval and generation components more tightly could improve the model's scalability.
-
Interpretability: The R2AG model is a complex neural network architecture, which can make it challenging to understand how the retrieval information is being used to guide the generation process. Providing more interpretability and explainability could be a valuable addition to the research.
-
Robustness: The paper does not thoroughly explore the robustness of the R2AG model to noisy or incomplete retrieval results. Understanding the model's sensitivity to retrieval errors could inform future improvements.
-
Generalization: The experiments in the paper focus on specific tasks and datasets. Evaluating the R2AG model's ability to generalize to a wider range of generation tasks and domains would be a valuable next step.
Overall, the R2AG paper presents an interesting and promising approach to incorporating retrieval information into generation models. Further research exploring the model's limitations and potential improvements could have significant implications for the field of natural language processing.
Conclusion
The R2AG paper introduces a novel approach to retrieval-augmented generation that uses the retrieval output as guidance for the language model during the generation process. This can lead to improvements in the coherence and relevance of the generated text, which is important for a wide range of applications.
While the paper presents promising results, there are also opportunities for further research to address potential limitations, such as scalability, interpretability, robustness, and generalization. Overall, the R2AG model represents an important step forward in the field of retrieval-augmented generation and natural language processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⛏️
Evaluation of Retrieval-Augmented Generation: A Survey
Hao Yu, Aoran Gan, Kai Zhang, Shiwei Tong, Qi Liu, Zhaofeng Liu
0
0
Retrieval-Augmented Generation (RAG) has emerged as a pivotal innovation in natural language processing, enhancing generative models by incorporating external information retrieval. Evaluating RAG systems, however, poses distinct challenges due to their hybrid structure and reliance on dynamic knowledge sources. We consequently enhanced an extensive survey and proposed an analysis framework for benchmarks of RAG systems, RAGR (Retrieval, Generation, Additional Requirement), designed to systematically analyze RAG benchmarks by focusing on measurable outputs and established truths. Specifically, we scrutinize and contrast multiple quantifiable metrics of the Retrieval and Generation component, such as relevance, accuracy, and faithfulness, of the internal links within the current RAG evaluation methods, covering the possible output and ground truth pairs. We also analyze the integration of additional requirements of different works, discuss the limitations of current benchmarks, and propose potential directions for further research to address these shortcomings and advance the field of RAG evaluation. In conclusion, this paper collates the challenges associated with RAG evaluation. It presents a thorough analysis and examination of existing methodologies for RAG benchmark design based on the proposed RGAR framework.
5/14/2024
🛸
DuetRAG: Collaborative Retrieval-Augmented Generation
Dian Jiao, Li Cai, Jingsheng Huang, Wenqiao Zhang, Siliang Tang, Yueting Zhuang
0
0
Retrieval-Augmented Generation (RAG) methods augment the input of Large Language Models (LLMs) with relevant retrieved passages, reducing factual errors in knowledge-intensive tasks. However, contemporary RAG approaches suffer from irrelevant knowledge retrieval issues in complex domain questions (e.g., HotPot QA) due to the lack of corresponding domain knowledge, leading to low-quality generations. To address this issue, we propose a novel Collaborative Retrieval-Augmented Generation framework, DuetRAG. Our bootstrapping philosophy is to simultaneously integrate the domain fintuning and RAG models to improve the knowledge retrieval quality, thereby enhancing generation quality. Finally, we demonstrate DuetRAG' s matches with expert human researchers on HotPot QA.
5/24/2024

Retrieval-Augmented Generation for AI-Generated Content: A Survey
Penghao Zhao, Hailin Zhang, Qinhan Yu, Zhengren Wang, Yunteng Geng, Fangcheng Fu, Ling Yang, Wentao Zhang, Jie Jiang, Bin Cui
0
0
Advancements in model algorithms, the growth of foundational models, and access to high-quality datasets have propelled the evolution of Artificial Intelligence Generated Content (AIGC). Despite its notable successes, AIGC still faces hurdles such as updating knowledge, handling long-tail data, mitigating data leakage, and managing high training and inference costs. Retrieval-Augmented Generation (RAG) has recently emerged as a paradigm to address such challenges. In particular, RAG introduces the information retrieval process, which enhances the generation process by retrieving relevant objects from available data stores, leading to higher accuracy and better robustness. In this paper, we comprehensively review existing efforts that integrate RAG technique into AIGC scenarios. We first classify RAG foundations according to how the retriever augments the generator, distilling the fundamental abstractions of the augmentation methodologies for various retrievers and generators. This unified perspective encompasses all RAG scenarios, illuminating advancements and pivotal technologies that help with potential future progress. We also summarize additional enhancements methods for RAG, facilitating effective engineering and implementation of RAG systems. Then from another view, we survey on practical applications of RAG across different modalities and tasks, offering valuable references for researchers and practitioners. Furthermore, we introduce the benchmarks for RAG, discuss the limitations of current RAG systems, and suggest potential directions for future research. Github: https://github.com/PKU-DAIR/RAG-Survey.
6/3/2024
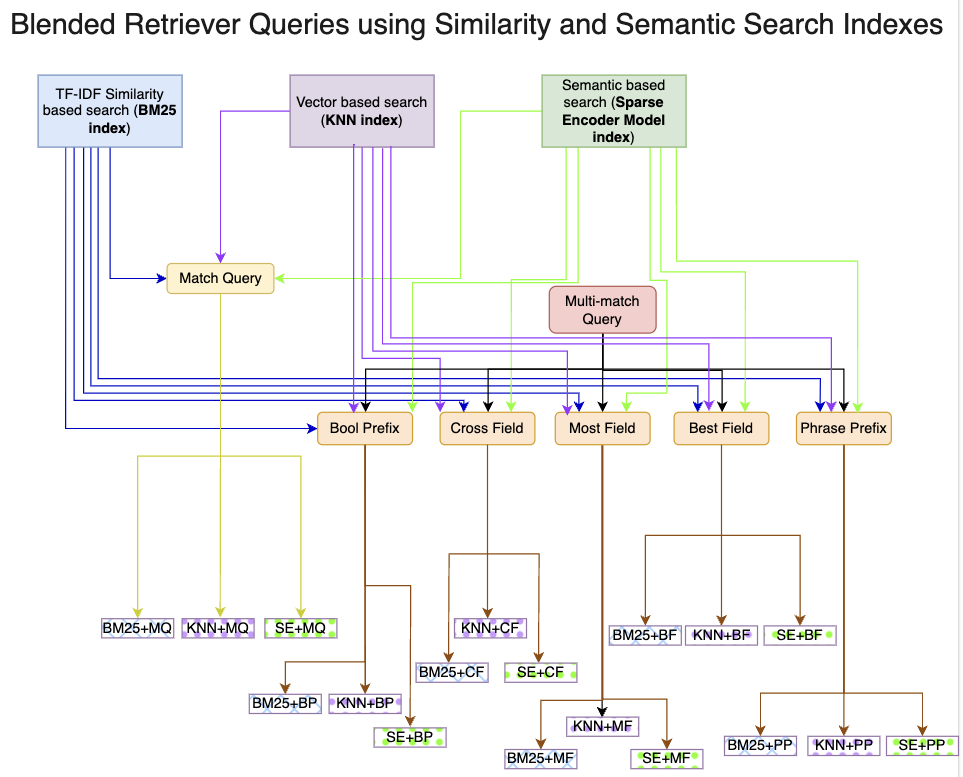
Blended RAG: Improving RAG (Retriever-Augmented Generation) Accuracy with Semantic Search and Hybrid Query-Based Retrievers
Kunal Sawarkar, Abhilasha Mangal, Shivam Raj Solanki
0
0
Retrieval-Augmented Generation (RAG) is a prevalent approach to infuse a private knowledge base of documents with Large Language Models (LLM) to build Generative Q&A (Question-Answering) systems. However, RAG accuracy becomes increasingly challenging as the corpus of documents scales up, with Retrievers playing an outsized role in the overall RAG accuracy by extracting the most relevant document from the corpus to provide context to the LLM. In this paper, we propose the 'Blended RAG' method of leveraging semantic search techniques, such as Dense Vector indexes and Sparse Encoder indexes, blended with hybrid query strategies. Our study achieves better retrieval results and sets new benchmarks for IR (Information Retrieval) datasets like NQ and TREC-COVID datasets. We further extend such a 'Blended Retriever' to the RAG system to demonstrate far superior results on Generative Q&A datasets like SQUAD, even surpassing fine-tuning performance.
4/12/2024