Localisation of Regularised and Multiview Support Vector Machine Learning

0
🏋️
Sign in to get full access
Overview
- The paper proves representer theorems for a localized version of the regularized and multiview support vector machine (SVM) learning problem.
- This problem involves operator-valued positive semidefinite kernels and their reproducing kernel Hilbert spaces (RKHSs).
- The results cover general cases when convex or nonconvex loss functions and finite or infinite-dimensional input spaces are considered.
- The framework allows for infinite-dimensional input spaces and nonconvex loss functions in some special cases, particularly when the loss functions are Gâteaux differentiable.
- Detailed calculations are provided for the exponential least-square loss function, leading to partially nonlinear equations that can be solved using a particular unconstrained potential reduction Newton's approximation method.
Plain English Explanation
The paper discusses a type of machine learning model called a Support Vector Machine (SVM). SVMs are a popular way to classify data into different categories.
The researchers looked at a specific version of the SVM problem that involves operator-valued kernels and the mathematical spaces they live in, called Reproducing Kernel Hilbert Spaces (RKHSs).
They proved some theoretical results, called representer theorems, which describe the structure of the solutions to this SVM problem. These results apply to cases where the loss function (the measure of how well the model is performing) can be either convex or non-convex, and the input data can be either finite or infinite-dimensional.
The researchers also looked at a specific loss function called the exponential least-square loss. They showed that this leads to partially nonlinear equations, which can be solved using a particular optimization method.
Technical Explanation
The paper proves representer theorems for a localized version of the regularized and multiview SVM learning problem introduced in previous work. This problem involves operator-valued positive semidefinite kernels and their RKHSs.
The results cover general cases where the loss function can be convex or nonconvex, and the input space can be finite or infinite-dimensional. The researchers show that the general framework allows for infinite-dimensional input spaces and nonconvex loss functions in some special cases, particularly when the loss functions are Gâteaux differentiable.
For the specific case of the exponential least-square loss function, the paper provides detailed calculations that lead to partially nonlinear equations. The researchers propose using a particular unconstrained potential reduction Newton's approximation method to solve these equations.
Critical Analysis
The paper presents a comprehensive theoretical analysis of the SVM problem with operator-valued kernels and nonconvex loss functions. The researchers have clearly built upon previous work in this area and have made significant advances in understanding the structure of the solutions to this problem.
One potential limitation of the research is the focus on a specific loss function, the exponential least-square loss. While the authors provide a detailed analysis of this case, it would be valuable to see how their methods and insights extend to a broader range of loss functions, especially those that are more commonly used in practice.
Additionally, the paper does not provide any empirical evaluation of the proposed methods. It would be helpful to see how the theoretical results translate to practical performance on real-world datasets and tasks. This could help assess the practical implications and potential impact of the research.
Overall, the paper makes important contributions to the understanding of SVM problems with operator-valued kernels and nonconvex loss functions. The theoretical insights and the proposed optimization methods are likely to be of interest to researchers and practitioners working in this area of machine learning.
Conclusion
This paper presents a comprehensive theoretical analysis of a localized version of the regularized and multiview SVM learning problem involving operator-valued kernels and RKHSs. The researchers prove representer theorems that describe the structure of the solutions to this problem under various conditions, including convex or nonconvex loss functions and finite or infinite-dimensional input spaces.
The detailed analysis of the exponential least-square loss function and the proposed optimization method for the resulting partially nonlinear equations are particularly noteworthy. These contributions provide a solid foundation for further research and potential applications in areas where operator-valued kernels and nonconvex loss functions are relevant.
While the paper focuses primarily on the theoretical aspects, empirical validation and exploration of the practical implications of the proposed framework would be valuable next steps to assess its real-world impact. Overall, this work represents an important advancement in the understanding and analysis of SVM-based learning problems with complex mathematical structures.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏋️
0
Localisation of Regularised and Multiview Support Vector Machine Learning
Aurelian Gheondea, Cankat Tilki
We prove a few representer theorems for a localised version of the regularised and multiview support vector machine learning problem introduced by H.Q. Minh, L. Bazzani, and V. Murino, Journal of Machine Learning Research, 17(2016) 1-72, that involves operator valued positive semidefinite kernels and their reproducing kernel Hilbert spaces. The results concern general cases when convex or nonconvex loss functions and finite or infinite dimensional input spaces are considered. We show that the general framework allows infinite dimensional input spaces and nonconvex loss functions for some special cases, in particular in case the loss functions are Gateaux differentiable. Detailed calculations are provided for the exponential least square loss function that lead to partially nonlinear equations for which a particular unconstrained potential reduction Newton's approximation method can be used.
Read more7/10/2024
🧠
0
Variation Spaces for Multi-Output Neural Networks: Insights on Multi-Task Learning and Network Compression
Joseph Shenouda, Rahul Parhi, Kangwook Lee, Robert D. Nowak
This paper introduces a novel theoretical framework for the analysis of vector-valued neural networks through the development of vector-valued variation spaces, a new class of reproducing kernel Banach spaces. These spaces emerge from studying the regularization effect of weight decay in training networks with activations like the rectified linear unit (ReLU). This framework offers a deeper understanding of multi-output networks and their function-space characteristics. A key contribution of this work is the development of a representer theorem for the vector-valued variation spaces. This representer theorem establishes that shallow vector-valued neural networks are the solutions to data-fitting problems over these infinite-dimensional spaces, where the network widths are bounded by the square of the number of training data. This observation reveals that the norm associated with these vector-valued variation spaces encourages the learning of features that are useful for multiple tasks, shedding new light on multi-task learning with neural networks. Finally, this paper develops a connection between weight-decay regularization and the multi-task lasso problem. This connection leads to novel bounds for layer widths in deep networks that depend on the intrinsic dimensions of the training data representations. This insight not only deepens the understanding of the deep network architectural requirements, but also yields a simple convex optimization method for deep neural network compression. The performance of this compression procedure is evaluated on various architectures.
Read more7/25/2024
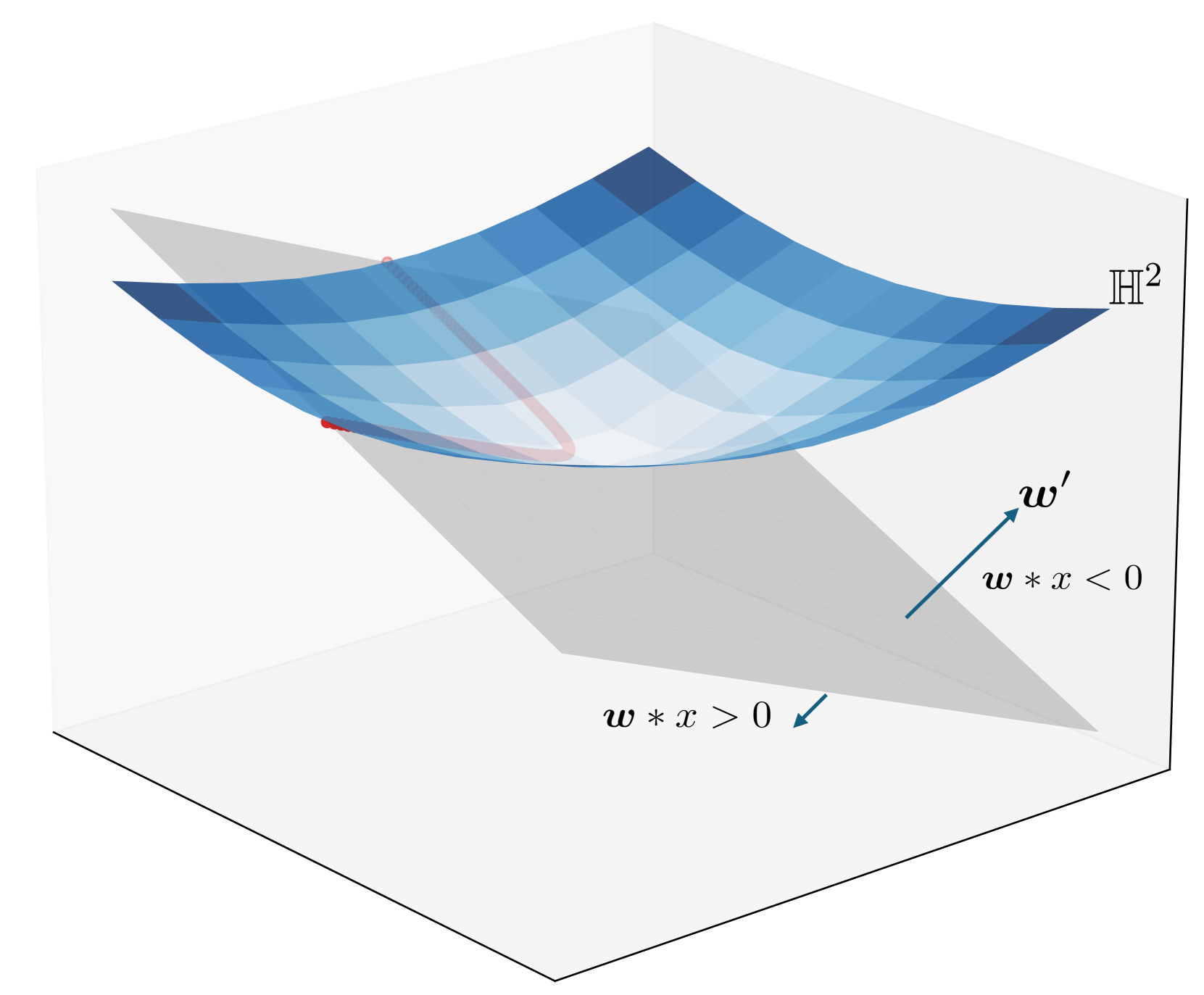
0
Convex Relaxation for Solving Large-Margin Classifiers in Hyperbolic Space
Sheng Yang, Peihan Liu, Cengiz Pehlevan
Hyperbolic spaces have increasingly been recognized for their outstanding performance in handling data with inherent hierarchical structures compared to their Euclidean counterparts. However, learning in hyperbolic spaces poses significant challenges. In particular, extending support vector machines to hyperbolic spaces is in general a constrained non-convex optimization problem. Previous and popular attempts to solve hyperbolic SVMs, primarily using projected gradient descent, are generally sensitive to hyperparameters and initializations, often leading to suboptimal solutions. In this work, by first rewriting the problem into a polynomial optimization, we apply semidefinite relaxation and sparse moment-sum-of-squares relaxation to effectively approximate the optima. From extensive empirical experiments, these methods are shown to perform better than the projected gradient descent approach.
Read more5/28/2024

0
Multiview learning with twin parametric margin SVM
A. Quadir, M. Tanveer
Multiview learning (MVL) seeks to leverage the benefits of diverse perspectives to complement each other, effectively extracting and utilizing the latent information within the dataset. Several twin support vector machine-based MVL (MvTSVM) models have been introduced and demonstrated outstanding performance in various learning tasks. However, MvTSVM-based models face significant challenges in the form of computational complexity due to four matrix inversions, the need to reformulate optimization problems in order to employ kernel-generated surfaces for handling non-linear cases, and the constraint of uniform noise assumption in the training data. Particularly in cases where the data possesses a heteroscedastic error structure, these challenges become even more pronounced. In view of the aforementioned challenges, we propose multiview twin parametric margin support vector machine (MvTPMSVM). MvTPMSVM constructs parametric margin hyperplanes corresponding to both classes, aiming to regulate and manage the impact of the heteroscedastic noise structure existing within the data. The proposed MvTPMSVM model avoids the explicit computation of matrix inversions in the dual formulation, leading to enhanced computational efficiency. We perform an extensive assessment of the MvTPMSVM model using benchmark datasets such as UCI, KEEL, synthetic, and Animals with Attributes (AwA). Our experimental results, coupled with rigorous statistical analyses, confirm the superior generalization capabilities of the proposed MvTPMSVM model compared to the baseline models. The source code of the proposed MvTPMSVM model is available at url{https://github.com/mtanveer1/MvTPMSVM}.
Read more8/13/2024