LoQT: Low Rank Adapters for Quantized Training
2405.16528
0
0
Abstract
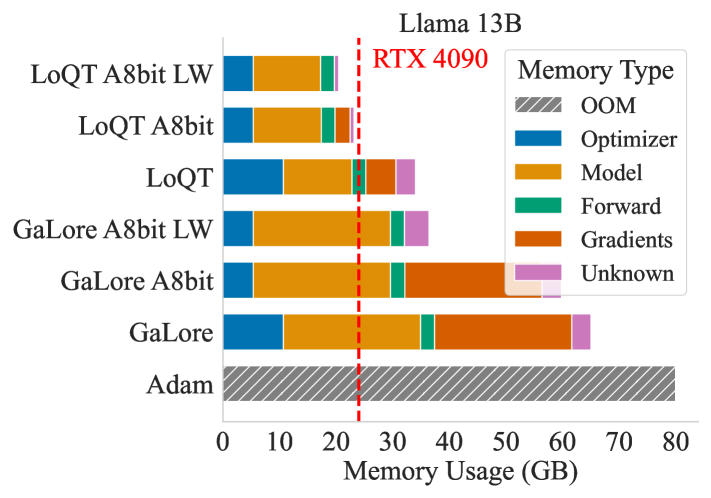
Training of large neural networks requires significant computational resources. Despite advances using low-rank adapters and quantization, pretraining of models such as LLMs on consumer hardware has not been possible without model sharding, offloading during training, or per-layer gradient updates. To address these limitations, we propose LoQT, a method for efficiently training quantized models. LoQT uses gradient-based tensor factorization to initialize low-rank trainable weight matrices that are periodically merged into quantized full-rank weight matrices. Our approach is suitable for both pretraining and fine-tuning of models, which we demonstrate experimentally for language modeling and downstream task adaptation. We find that LoQT enables efficient training of models up to 7B parameters on a consumer-grade 24GB GPU. We also demonstrate the feasibility of training a 13B parameter model using per-layer gradient updates on the same hardware.
Create account to get full access
Overview
• This paper introduces LoQT, a novel method for low-rank adaptation during quantized training of large language models. • The key idea is to use low-rank adapters that can be efficiently quantized, enabling significant model size reduction with minimal accuracy loss. • The authors demonstrate the effectiveness of LoQT on several benchmark tasks, showing it outperforms prior approaches for quantized training.
Plain English Explanation
Large language models like those used for tasks like text generation and translation can require a lot of memory and computation to run. One way to make these models more efficient is quantization, which reduces the precision of the numerical values used to represent the model's parameters. This can significantly reduce the model size and speed up inference, but can also hurt accuracy.
The LoQT method introduced in this paper aims to address this challenge. The core idea is to use low-rank adapters - small neural network layers that are added to the main model. These adapters can be quantized to low bit-widths (e.g. 4-bits) while preserving most of the model's accuracy.
By only quantizing the adapters and keeping the main model parameters at full precision, LoQT can achieve substantial model size reduction (up to 50%) with minimal accuracy loss, outperforming prior quantization-aware fine-tuning and post-training quantization methods.
Technical Explanation
The key technical innovation in LoQT is the use of low-rank adapters - small neural network layers that are added to the main model architecture. These adapters can be efficiently quantized to low bit-widths (e.g. 4-bits) while the main model parameters remain at full precision.
The authors first perform a singular value decomposition (SVD) on the weight matrices of the main model layers. They then replace each full-rank layer with a low-rank adapter consisting of a linear projection down to a low-rank space, followed by a linear projection back up to the original dimensionality.
These low-rank adapters are then quantized using various techniques like APTQ and ADPQ, while the main model weights remain unquantized. This allows LoQT to achieve significant model size reduction with only a small drop in accuracy.
The authors evaluate LoQT on several language modeling and text classification benchmarks, showing it outperforms prior quantization-aware fine-tuning and post-training quantization methods in terms of both model size and accuracy.
Critical Analysis
The LoQT approach seems promising for enabling efficient quantization of large language models. The use of low-rank adapters is a clever way to isolate the quantization to a small portion of the model, preserving the accuracy of the main parameters.
However, the paper does not address some potential limitations:
- The overhead of the low-rank adapters may offset some of the savings from quantization, especially for very small models.
- The method may not generalize as well to other model architectures beyond the Transformer-based models studied here.
- There could be challenges in deploying LoQT in real-world scenarios with tight memory/latency constraints.
Further research is needed to better understand the tradeoffs and limitations of the LoQT approach, as well as to explore extensions to other domains and model types.
Conclusion
The LoQT method introduced in this paper offers an effective new approach for quantizing large language models with minimal accuracy degradation. By leveraging low-rank adapters that can be efficiently quantized, LoQT demonstrates significant model size reductions of up to 50% while outperforming prior quantization techniques.
This work represents an important step forward in making powerful language models more compact and computationally efficient, with potential applications in edge devices, mobile apps, and other resource-constrained environments. As AI models continue to grow in scale and complexity, innovations like LoQT will be crucial for enabling their real-world deployment and broader societal impact.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Low-Rank Quantization-Aware Training for LLMs
Yelysei Bondarenko, Riccardo Del Chiaro, Markus Nagel
0
0
Large language models (LLMs) are omnipresent, however their practical deployment is challenging due to their ever increasing computational and memory demands. Quantization is one of the most effective ways to make them more compute and memory efficient. Quantization-aware training (QAT) methods, generally produce the best quantized performance, however it comes at the cost of potentially long training time and excessive memory usage, making it impractical when applying for LLMs. Inspired by parameter-efficient fine-tuning (PEFT) and low-rank adaptation (LoRA) literature, we propose LR-QAT -- a lightweight and memory-efficient QAT algorithm for LLMs. LR-QAT employs several components to save memory without sacrificing predictive performance: (a) low-rank auxiliary weights that are aware of the quantization grid; (b) a downcasting operator using fixed-point or double-packed integers and (c) checkpointing. Unlike most related work, our method (i) is inference-efficient, leading to no additional overhead compared to traditional PTQ; (ii) can be seen as a general extended pretraining framework, meaning that the resulting model can still be utilized for any downstream task afterwards; (iii) can be applied across a wide range of quantization settings, such as different choices quantization granularity, activation quantization, and seamlessly combined with many PTQ techniques. We apply LR-QAT to LLaMA-2/3 and Mistral model families and validate its effectiveness on several downstream tasks. Our method outperforms common post-training quantization (PTQ) approaches and reaches the same model performance as full-model QAT at the fraction of its memory usage. Specifically, we can train a 7B LLM on a single consumer grade GPU with 24GB of memory.
6/21/2024
💬
QLLM: Accurate and Efficient Low-Bitwidth Quantization for Large Language Models
Jing Liu, Ruihao Gong, Xiuying Wei, Zhiwei Dong, Jianfei Cai, Bohan Zhuang
0
0
Large Language Models (LLMs) excel in NLP, but their demands hinder their widespread deployment. While Quantization-Aware Training (QAT) offers a solution, its extensive training costs make Post-Training Quantization (PTQ) a more practical approach for LLMs. In existing studies, activation outliers in particular channels are identified as the bottleneck to PTQ accuracy. They propose to transform the magnitudes from activations to weights, which however offers limited alleviation or suffers from unstable gradients, resulting in a severe performance drop at low-bitwidth. In this paper, we propose QLLM, an accurate and efficient low-bitwidth PTQ method designed for LLMs. QLLM introduces an adaptive channel reassembly technique that reallocates the magnitude of outliers to other channels, thereby mitigating their impact on the quantization range. This is achieved by channel disassembly and channel assembly, which first breaks down the outlier channels into several sub-channels to ensure a more balanced distribution of activation magnitudes. Then similar channels are merged to maintain the original channel number for efficiency. Additionally, an adaptive strategy is designed to autonomously determine the optimal number of sub-channels for channel disassembly. To further compensate for the performance loss caused by quantization, we propose an efficient tuning method that only learns a small number of low-rank weights while freezing the pre-trained quantized model. After training, these low-rank parameters can be fused into the frozen weights without affecting inference. Extensive experiments on LLaMA-1 and LLaMA-2 show that QLLM can obtain accurate quantized models efficiently. For example, QLLM quantizes the 4-bit LLaMA-2-70B within 10 hours on a single A100-80G GPU, outperforming the previous state-of-the-art method by 7.89% on the average accuracy across five zero-shot tasks.
4/9/2024

ApiQ: Finetuning of 2-Bit Quantized Large Language Model
Baohao Liao, Christian Herold, Shahram Khadivi, Christof Monz
0
0
Memory-efficient finetuning of large language models (LLMs) has recently attracted huge attention with the increasing size of LLMs, primarily due to the constraints posed by GPU memory limitations and the effectiveness of these methods compared to full finetuning. Despite the advancements, current strategies for memory-efficient finetuning, such as QLoRA, exhibit inconsistent performance across diverse bit-width quantizations and multifaceted tasks. This inconsistency largely stems from the detrimental impact of the quantization process on preserved knowledge, leading to catastrophic forgetting and undermining the utilization of pretrained models for finetuning purposes. In this work, we introduce a novel quantization framework, ApiQ, designed to restore the lost information from quantization by concurrently initializing the LoRA components and quantizing the weights of LLMs. This approach ensures the maintenance of the original LLM's activation precision while mitigating the error propagation from shallower into deeper layers. Through comprehensive evaluations conducted on a spectrum of language tasks with various LLMs, ApiQ demonstrably minimizes activation error during quantization. Consequently, it consistently achieves superior finetuning results across various bit-widths.
6/24/2024
💬
L4Q: Parameter Efficient Quantization-Aware Fine-Tuning on Large Language Models
Hyesung Jeon, Yulhwa Kim, Jae-joon Kim
0
0
Due to the high memory and computational costs associated with Large Language Models, model compression via quantization and parameter-efficient fine-tuning (PEFT) methods, such as low-rank adaptation (LoRA), are gaining popularity. This has led to active research on quantization-aware PEFT techniques, which aim to create models with high accuracy and low memory overhead. Among quantization methods, post-training quantization (PTQ) is more commonly used in previous works than quantization-aware training (QAT), despite QAT's potential for higher accuracy. This preference is due to PTQ's low training overhead. However, PTQ-based PEFT methods often utilize high-precision parameters, making it difficult to fully exploit the efficiency of quantization. Additionally, they have limited adaptation ability due to a reduced and constrained LoRA parameter structure. To overcome these challenges, we propose L4Q, which leverages joint quantization and fine-tuning to reduce QAT's memory overhead and produce models that consist entirely of quantized weights while achieving effective adaptation to downstream tasks. By design, L4Q allows quantization parameters to reflect weight updates, while weight updates reduce quantization errors. Our experiments demonstrate that this coupled quantization and fine-tuning approach yields superior accuracy compared to decoupled fine-tuning schemes in sub-4-bit quantization. Using the LLaMA model families and instructional datasets, we showcase L4Q's capabilities in language tasks and few-shot in-context learning.
5/24/2024