LoRA-Whisper: Parameter-Efficient and Extensible Multilingual ASR
2406.06619
0
0

Abstract
Recent years have witnessed significant progress in multilingual automatic speech recognition (ASR), driven by the emergence of end-to-end (E2E) models and the scaling of multilingual datasets. Despite that, two main challenges persist in multilingual ASR: language interference and the incorporation of new languages without degrading the performance of the existing ones. This paper proposes LoRA-Whisper, which incorporates LoRA matrix into Whisper for multilingual ASR, effectively mitigating language interference. Furthermore, by leveraging LoRA and the similarities between languages, we can achieve better performance on new languages while upholding consistent performance on original ones. Experiments on a real-world task across eight languages demonstrate that our proposed LoRA-Whisper yields a relative gain of 18.5% and 23.0% over the baseline system for multilingual ASR and language expansion respectively.
Create account to get full access
Overview
- This paper presents LoRA-Whisper, a parameter-efficient and extensible multilingual Automatic Speech Recognition (ASR) model.
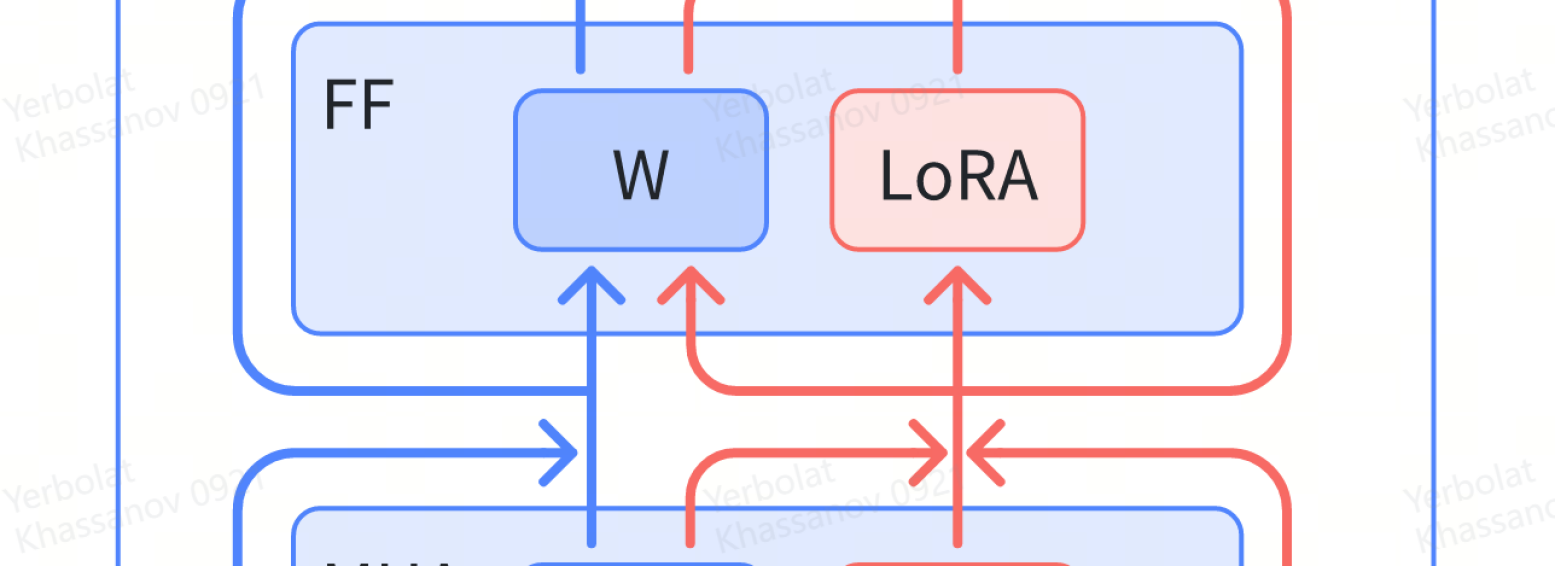
- LoRA-Whisper leverages the Lightweight Adaptation (LoRA) technique to fine-tune the Whisper model, a state-of-the-art multilingual ASR model, for specific language pairs or domains.
- The key advantages of LoRA-Whisper include: 1) greatly reduced parameter requirements compared to full fine-tuning, 2) the ability to add new languages or domains without retraining the entire model, and 3) strong performance across a range of multilingual ASR benchmarks.
Plain English Explanation
The paper introduces LoRA-Whisper, a new approach to training multilingual speech recognition models. Typical speech models require a large number of parameters and must be entirely retrained when adding support for new languages. LoRA-Whisper solves this by using a technique called Lightweight Adaptation (LoRA) to fine-tune the existing Whisper model for specific languages or domains.
With LoRA-Whisper, only a small number of additional parameters need to be trained, rather than the entire model. This makes the process much more efficient and allows new languages to be added without retraining the entire system from scratch. The researchers show that LoRA-Whisper achieves strong performance on a variety of multilingual speech recognition benchmarks, while vastly reducing the parameter requirements compared to full fine-tuning.
Overall, LoRA-Whisper represents an important advance in making multilingual speech models more practical and accessible, by reducing the cost and complexity of supporting new languages. This could enable the development of more inclusive and widely-applicable speech recognition systems.
Technical Explanation
The key technical innovation in LoRA-Whisper is the use of the Lightweight Adaptation (LoRA) technique to fine-tune the pre-trained Whisper model. LoRA allows the model to be adapted to new language pairs or domains by training only a small number of additional parameters, rather than updating the entire set of model weights.
The researchers demonstrate that LoRA-Whisper achieves comparable or superior performance to fully fine-tuned Whisper models across a range of multilingual ASR benchmarks, including CommonVoice, MLS, and KGT-ASR, while using only a fraction of the trainable parameters.
Furthermore, the modular design of LoRA-Whisper allows new languages or domains to be added incrementally, without the need to retrain the entire model. This makes the system more scalable and adaptable to evolving requirements, compared to traditional fine-tuning approaches.
Critical Analysis
The paper provides a thorough evaluation of LoRA-Whisper's performance and efficiency, demonstrating its advantages over full fine-tuning. However, the authors acknowledge that LoRA-Whisper may not be suitable for all use cases, particularly those requiring high-accuracy speech recognition for a small number of languages.
Additionally, the paper does not address the potential for language bias or fairness issues that can arise in multilingual models, which is an important consideration for real-world deployments. Further research may be needed to assess and mitigate these concerns.
Overall, LoRA-Whisper represents a promising approach to improving the scalability and cost-effectiveness of multilingual speech recognition systems. However, as with any new technology, it will be important to continue evaluating its strengths, limitations, and potential societal impacts as it evolves.
Conclusion
In summary, the LoRA-Whisper paper presents a novel technique for fine-tuning multilingual speech recognition models in a parameter-efficient and extensible manner. By leveraging the LoRA method, the researchers demonstrate that LoRA-Whisper can achieve strong performance on a variety of multilingual ASR benchmarks while using significantly fewer trainable parameters than traditional fine-tuning approaches.
This work has the potential to make multilingual speech recognition more accessible and practical, by reducing the cost and complexity of supporting new languages. As the demand for inclusive and widely-applicable speech interfaces continues to grow, innovations like LoRA-Whisper may play a crucial role in driving progress in this important field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Dual-Pipeline with Low-Rank Adaptation for New Language Integration in Multilingual ASR
Yerbolat Khassanov, Zhipeng Chen, Tianfeng Chen, Tze Yuang Chong, Wei Li, Jun Zhang, Lu Lu, Yuxuan Wang
0
0
This paper addresses challenges in integrating new languages into a pre-trained multilingual automatic speech recognition (mASR) system, particularly in scenarios where training data for existing languages is limited or unavailable. The proposed method employs a dual-pipeline with low-rank adaptation (LoRA). It maintains two data flow pipelines-one for existing languages and another for new languages. The primary pipeline follows the standard flow through the pre-trained parameters of mASR, while the secondary pipeline additionally utilizes language-specific parameters represented by LoRA and a separate output decoder module. Importantly, the proposed approach minimizes the performance degradation of existing languages and enables a language-agnostic operation mode, facilitated by a decoder selection strategy. We validate the effectiveness of the proposed method by extending the pre-trained Whisper model to 19 new languages from the FLEURS dataset
6/13/2024
Efficient Compression of Multitask Multilingual Speech Models
Thomas Palmeira Ferraz
0
0
Whisper is a multitask and multilingual speech model covering 99 languages. It yields commendable automatic speech recognition (ASR) results in a subset of its covered languages, but the model still underperforms on a non-negligible number of under-represented languages, a problem exacerbated in smaller model versions. In this work, we examine its limitations, demonstrating the presence of speaker-related (gender, age) and model-related (resourcefulness and model size) bias. Despite that, we show that only model-related bias are amplified by quantization, impacting more low-resource languages and smaller models. Searching for a better compression approach, we propose DistilWhisper, an approach that is able to bridge the performance gap in ASR for these languages while retaining the advantages of multitask and multilingual capabilities. Our approach involves two key strategies: lightweight modular ASR fine-tuning of whisper-small using language-specific experts, and knowledge distillation from whisper-large-v2. This dual approach allows us to effectively boost ASR performance while keeping the robustness inherited from the multitask and multilingual pre-training. Results demonstrate that our approach is more effective than standard fine-tuning or LoRA adapters, boosting performance in the targeted languages for both in- and out-of-domain test sets, while introducing only a negligible parameter overhead at inference.
5/3/2024

MaLa-ASR: Multimedia-Assisted LLM-Based ASR
Guanrou Yang, Ziyang Ma, Fan Yu, Zhifu Gao, Shiliang Zhang, Xie Chen
0
0
As more and more information-rich data like video become available, utilizing multi-modal auxiliary information to enhance audio tasks has sparked widespread research interest. The recent surge in research on LLM-based audio models provides fresh perspectives for tackling audio tasks. Given that LLM can flexibly ingest multiple inputs, we propose MaLa-ASR, an LLM-based ASR model that can integrate textual keywords extracted from presentation slides to improve recognition of conference content. MaLa-ASR yields average WERs of 9.4% and 11.7% on the L95 and S95 subsets of the SlideSpeech corpus, representing a significant relative WER drop of 27.9% and 44.7% over the baseline model reported in SlideSpeech. MaLa-ASR underscores LLM's strong performance in speech tasks and the capability to integrate auxiliary information conveniently. By adding keywords to the input prompt, the biased word error rate (B-WER) reduces relatively by 46.0% and 44.2%, establishing a new SOTA on this dataset.
6/14/2024
🏅
PI-Whisper: An Adaptive and Incremental ASR Framework for Diverse and Evolving Speaker Characteristics
Amir Nassereldine, Dancheng Liu, Chenhui Xu, Jinjun Xiong
0
0
As edge-based automatic speech recognition (ASR) technologies become increasingly prevalent for the development of intelligent and personalized assistants, three important challenges must be addressed for these resource-constrained ASR models, i.e., adaptivity, incrementality, and inclusivity. We propose a novel ASR framework, PI-Whisper, in this work and show how it can improve an ASR's recognition capabilities adaptively by identifying different speakers' characteristics in real-time, how such an adaption can be performed incrementally without repetitive retraining, and how it can improve the equity and fairness for diverse speaker groups. More impressively, our proposed PI-Whisper framework attains all of these nice properties while still achieving state-of-the-art accuracy with up to 13.7% reduction of the word error rate (WER) with linear scalability with respect to computing resources.
6/26/2024