Efficient Compression of Multitask Multilingual Speech Models
2405.00966
0
0
Abstract
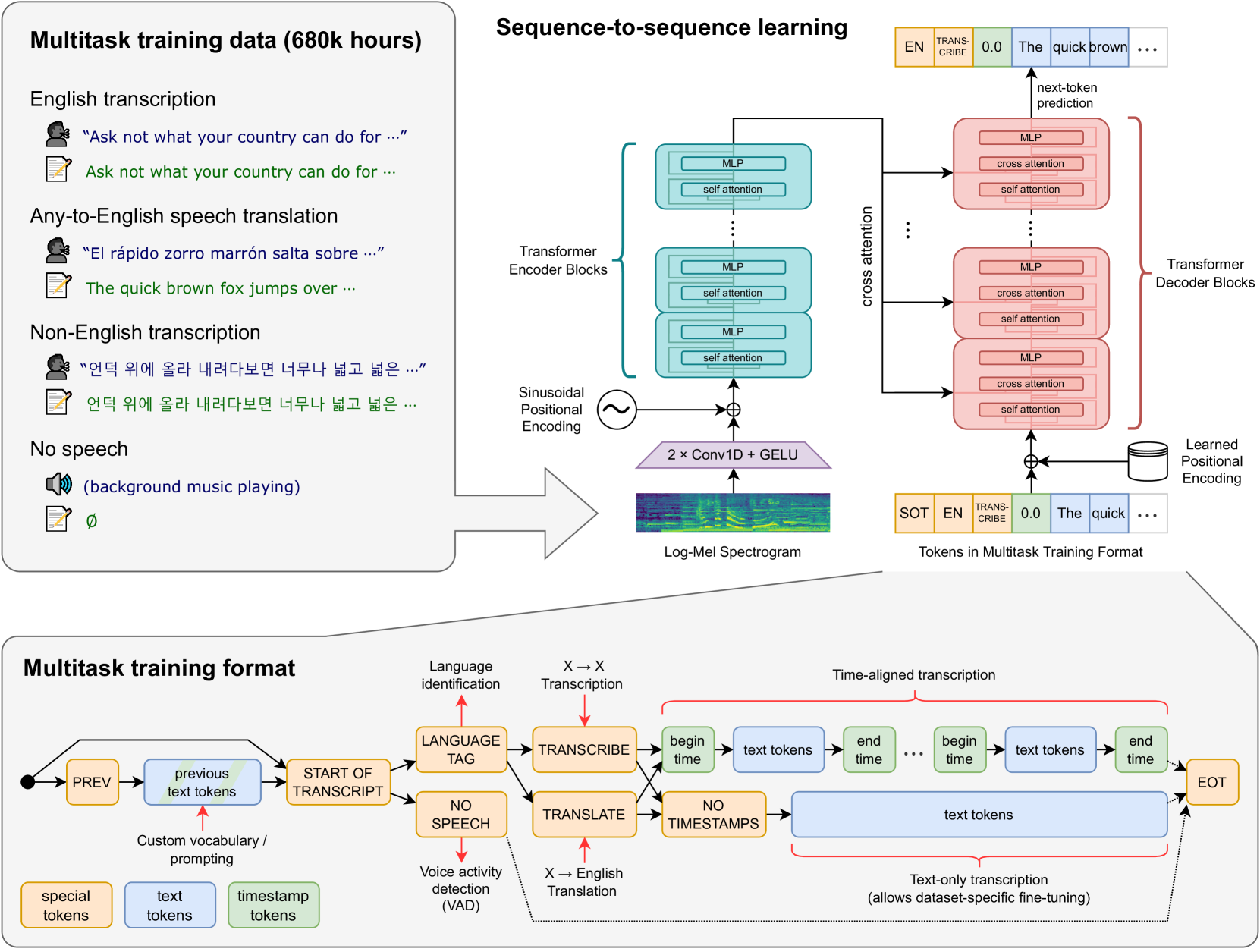
Whisper is a multitask and multilingual speech model covering 99 languages. It yields commendable automatic speech recognition (ASR) results in a subset of its covered languages, but the model still underperforms on a non-negligible number of under-represented languages, a problem exacerbated in smaller model versions. In this work, we examine its limitations, demonstrating the presence of speaker-related (gender, age) and model-related (resourcefulness and model size) bias. Despite that, we show that only model-related bias are amplified by quantization, impacting more low-resource languages and smaller models. Searching for a better compression approach, we propose DistilWhisper, an approach that is able to bridge the performance gap in ASR for these languages while retaining the advantages of multitask and multilingual capabilities. Our approach involves two key strategies: lightweight modular ASR fine-tuning of whisper-small using language-specific experts, and knowledge distillation from whisper-large-v2. This dual approach allows us to effectively boost ASR performance while keeping the robustness inherited from the multitask and multilingual pre-training. Results demonstrate that our approach is more effective than standard fine-tuning or LoRA adapters, boosting performance in the targeted languages for both in- and out-of-domain test sets, while introducing only a negligible parameter overhead at inference.
Create account to get full access
Overview
- This paper presents research on large-scale multilingual automatic speech recognition (ASR) systems and their applications.
- The researchers explore techniques for improving the robustness and performance of ASR models, particularly in the context of under-resourced languages.
- The paper covers a range of topics, including the anatomy of industrial-scale multilingual ASR systems, incorporating the Whisper model for speech assessment, and language model fine-tuning for endangered languages.
Plain English Explanation
The researchers in this study have been working on developing advanced speech recognition systems that can understand a wide variety of languages, including those that may not have as much available data or resources.
One of the key focus areas is Anatomy of Industrial-Scale Multilingual ASR, which looks at the inner workings of large-scale speech recognition systems that are designed to handle multiple languages. This is important because building these kinds of systems requires overcoming significant technical challenges.
Another aspect of the research explores incorporating the Whisper model to improve the robustness and accuracy of speech assessment. Whisper is a powerful AI model that was developed by OpenAI, and the researchers wanted to see how it could be used to enhance existing speech recognition capabilities.
The paper also dives into fine-tuning language models for endangered or under-resourced languages, such as Hawaiian. This is crucial work, as it can help preserve and revitalize these languages by making them more accessible through advanced technology.
Additionally, the researchers looked at how well the Whisper model handles Swiss German, which is a dialect that can be challenging for speech recognition systems. By evaluating the model's performance on this task, they gained valuable insights that can inform future improvements.
Finally, the paper explores techniques for automatically restoring diacritics in speech data sets. Diacritics are the small accent marks or symbols that appear above or below letters in some languages, and they can be important for accurate pronunciation and understanding.
Overall, this research is aimed at advancing the state of the art in multilingual speech recognition, with a focus on making these technologies more accessible and useful for a wide range of languages and applications.
Technical Explanation
The paper presents several key research contributions in the field of large-scale multilingual automatic speech recognition (ASR) systems.
In the Anatomy of Industrial-Scale Multilingual ASR section, the researchers delve into the technical details of building and deploying these complex systems. They discuss the architectural considerations, data requirements, and engineering challenges involved in creating ASR models that can handle hundreds of languages simultaneously.
The researchers also explore incorporating the Whisper model as a way to enhance the robustness and accuracy of speech assessment. Whisper, developed by OpenAI, is a state-of-the-art speech recognition model that the team aimed to leverage for improved performance.
Another focus area is fine-tuning language models for endangered or under-resourced languages, such as Hawaiian. The researchers describe their approach to adapting large language models to these low-resource scenarios, which is crucial for preserving and revitalizing these languages.
The paper also includes a qualitative evaluation of how well the Whisper model performs on Swiss German, a dialect that can be challenging for speech recognition systems. By assessing the model's strengths and weaknesses in this context, the researchers gained insights that can inform future improvements.
Finally, the researchers present their work on automatically restoring diacritics in speech data sets. Diacritics are important for accurate pronunciation and understanding, and the team developed techniques to address this task.
Critical Analysis
The researchers acknowledge several caveats and limitations in their work. For example, they note that the performance of their multilingual ASR systems may still be inferior to specialized, monolingual models in certain languages or domains. Additionally, the fine-tuning approaches for low-resource languages may be constrained by the availability of training data.
While the researchers have made impressive strides in advancing the state of the art in multilingual speech recognition, there are still significant challenges that need to be addressed. For instance, the ability to accurately handle regional dialects and accents remains an area for further improvement.
Furthermore, the ethical implications of deploying large-scale, AI-powered speech recognition systems, particularly in the context of endangered languages, warrant careful consideration. The researchers could have delved deeper into the potential risks and mitigation strategies to ensure these technologies are used responsibly and in alignment with the needs and values of the affected communities.
Overall, the research presented in this paper represents a valuable contribution to the field of multilingual speech recognition. However, the authors could have provided a more nuanced discussion of the limitations, trade-offs, and broader societal implications of their work.
Conclusion
This research paper explores a range of techniques and approaches for building robust, large-scale multilingual automatic speech recognition (ASR) systems. The key focus areas include the anatomy of industrial-scale multilingual ASR, incorporating the Whisper model for speech assessment, fine-tuning language models for under-resourced languages, evaluating the Whisper model's performance on Swiss German, and automating the restoration of diacritics in speech data sets.
The researchers have made significant advancements in addressing the technical challenges involved in creating multilingual ASR systems that can handle hundreds of languages simultaneously. Their work has the potential to enhance the accessibility and usefulness of speech recognition technologies for a wide range of applications and communities, including those with endangered or under-resourced languages.
However, the paper also highlights the need for further research to address the remaining limitations and potential ethical considerations of deploying these powerful AI-driven speech recognition systems at scale. Ongoing efforts to improve robustness, accuracy, and fairness will be crucial as these technologies continue to evolve and be integrated into real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

LoRA-Whisper: Parameter-Efficient and Extensible Multilingual ASR
Zheshu Song, Jianheng Zhuo, Yifan Yang, Ziyang Ma, Shixiong Zhang, Xie Chen
0
0
Recent years have witnessed significant progress in multilingual automatic speech recognition (ASR), driven by the emergence of end-to-end (E2E) models and the scaling of multilingual datasets. Despite that, two main challenges persist in multilingual ASR: language interference and the incorporation of new languages without degrading the performance of the existing ones. This paper proposes LoRA-Whisper, which incorporates LoRA matrix into Whisper for multilingual ASR, effectively mitigating language interference. Furthermore, by leveraging LoRA and the similarities between languages, we can achieve better performance on new languages while upholding consistent performance on original ones. Experiments on a real-world task across eight languages demonstrate that our proposed LoRA-Whisper yields a relative gain of 18.5% and 23.0% over the baseline system for multilingual ASR and language expansion respectively.
6/12/2024
New!Less is More: Accurate Speech Recognition & Translation without Web-Scale Data
Krishna C. Puvvada, Piotr .Zelasko, He Huang, Oleksii Hrinchuk, Nithin Rao Koluguri, Kunal Dhawan, Somshubra Majumdar, Elena Rastorgueva, Zhehuai Chen, Vitaly Lavrukhin, Jagadeesh Balam, Boris Ginsburg
0
0
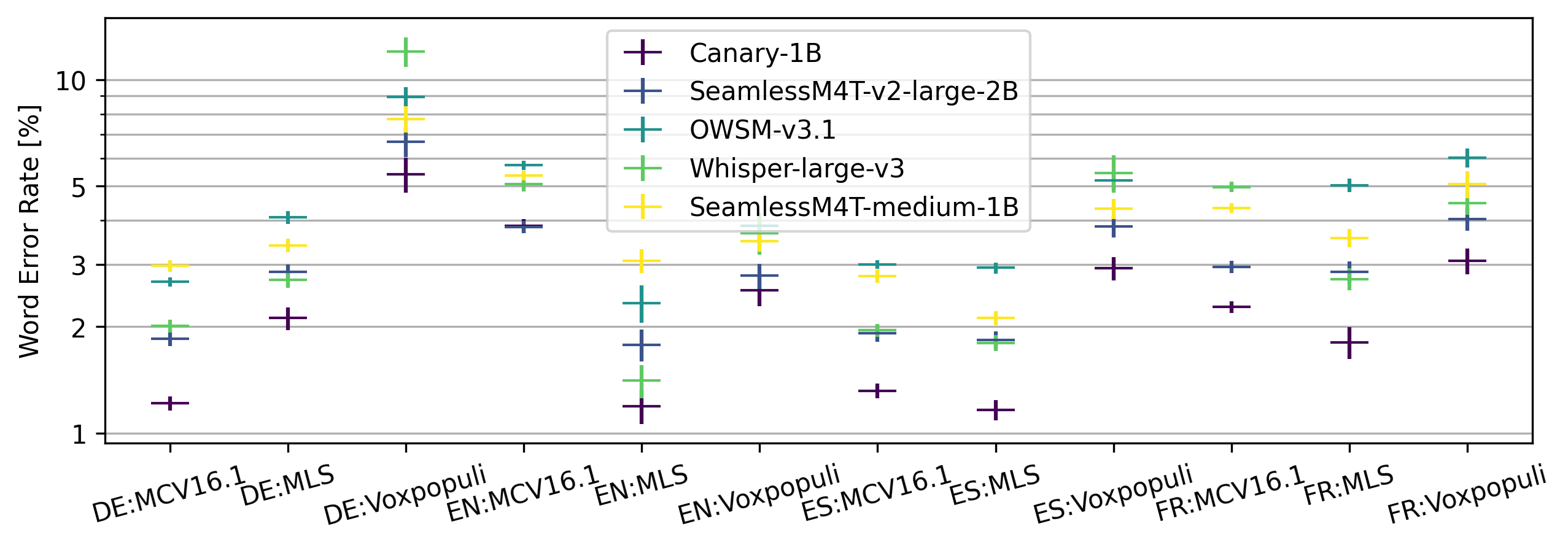
Recent advances in speech recognition and translation rely on hundreds of thousands of hours of Internet speech data. We argue that state-of-the art accuracy can be reached without relying on web-scale data. Canary - multilingual ASR and speech translation model, outperforms current state-of-the-art models - Whisper, OWSM, and Seamless-M4T on English, French, Spanish, and German languages, while being trained on an order of magnitude less data than these models. Three key factors enables such data-efficient model: (1) a FastConformer-based attention encoder-decoder architecture (2) training on synthetic data generated with machine translation and (3) advanced training techniques: data-balancing, dynamic data blending, dynamic bucketing and noise-robust fine-tuning. The model, weights, and training code will be open-sourced.
7/1/2024

Simul-Whisper: Attention-Guided Streaming Whisper with Truncation Detection
Haoyu Wang, Guoqiang Hu, Guodong Lin, Wei-Qiang Zhang, Jian Li
0
0
As a robust and large-scale multilingual speech recognition model, Whisper has demonstrated impressive results in many low-resource and out-of-distribution scenarios. However, its encoder-decoder structure hinders its application to streaming speech recognition. In this paper, we introduce Simul-Whisper, which uses the time alignment embedded in Whisper's cross-attention to guide auto-regressive decoding and achieve chunk-based streaming ASR without any fine-tuning of the pre-trained model. Furthermore, we observe the negative effect of the truncated words at the chunk boundaries on the decoding results and propose an integrate-and-fire-based truncation detection model to address this issue. Experiments on multiple languages and Whisper architectures show that Simul-Whisper achieves an average absolute word error rate degradation of only 1.46% at a chunk size of 1 second, which significantly outperforms the current state-of-the-art baseline.
6/17/2024
One-pass Multiple Conformer and Foundation Speech Systems Compression and Quantization Using An All-in-one Neural Model
Zhaoqing Li, Haoning Xu, Tianzi Wang, Shoukang Hu, Zengrui Jin, Shujie Hu, Jiajun Deng, Mingyu Cui, Mengzhe Geng, Xunying Liu
0
0
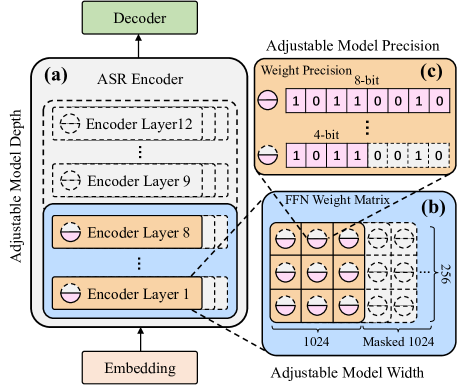
We propose a novel one-pass multiple ASR systems joint compression and quantization approach using an all-in-one neural model. A single compression cycle allows multiple nested systems with varying Encoder depths, widths, and quantization precision settings to be simultaneously constructed without the need to train and store individual target systems separately. Experiments consistently demonstrate the multiple ASR systems compressed in a single all-in-one model produced a word error rate (WER) comparable to, or lower by up to 1.01% absolute (6.98% relative) than individually trained systems of equal complexity. A 3.4x overall system compression and training time speed-up was achieved. Maximum model size compression ratios of 12.8x and 3.93x were obtained over the baseline Switchboard-300hr Conformer and LibriSpeech-100hr fine-tuned wav2vec2.0 models, respectively, incurring no statistically significant WER increase.
6/17/2024