Low algorithmic delay implementation of convolutional beamformer for online joint source separation and dereverberation

0
Sign in to get full access
Overview
- This paper presents a low algorithmic delay implementation of a convolutional beamformer for online joint source separation and dereverberation.
- The proposed approach aims to address the challenges of real-time processing and low latency in speech enhancement tasks.
- It combines independent vector analysis (IVA) with a sample-truncating technique to achieve low algorithmic delay while maintaining separation and dereverberation performance.
Plain English Explanation
The paper describes a new method for processing audio signals in real-time to improve speech quality. The key challenge is to do this with minimal delay, as any lag can be disruptive for applications like video conferencing or virtual assistants.
The researchers use a technique called independent vector analysis (IVA) to separate different sound sources, like a person's voice from background noise. IVA works by identifying the unique statistical properties of each sound source and separating them out.
However, standard IVA approaches can introduce significant delay. To address this, the researchers combine IVA with a "sample-truncating" technique. This means they only process a small chunk of the audio signal at a time, rather than waiting for the full signal. This reduces the overall delay while still maintaining the separation and noise-reduction benefits of IVA.
The result is a system that can perform real-time speech enhancement - separating the voice from background noise and echoes - with much lower delay than previous methods. This could enable more seamless and natural-sounding communication in applications like [<a href="https://aimodels.fyi/papers/arxiv/deep-low-latency-joint-speech-transmission-enhancement">real-time speech transmission</a>], [<a href="https://aimodels.fyi/papers/arxiv/multi-stage-speech-bandwidth-extension-flexible-sampling">bandwidth extension</a>], and [<a href="https://aimodels.fyi/papers/arxiv/beast-online-joint-beat-downbeat-tracking-based">online music processing</a>].
Technical Explanation
The paper proposes a low algorithmic delay implementation of a convolutional beamformer for online joint source separation and dereverberation. It combines [<a href="https://aimodels.fyi/papers/arxiv/buddy-single-channel-blind-unsupervised-dereverberation-diffusion">independent vector analysis (IVA)</a>] with a sample-truncating technique to achieve low latency while maintaining separation and dereverberation performance.
The key aspects of the approach are:
-
Convolutional Beamformer: The system uses a convolutional beamformer model, which can capture complex acoustic propagation effects like reverberation, compared to simpler time-invariant beamformers.
-
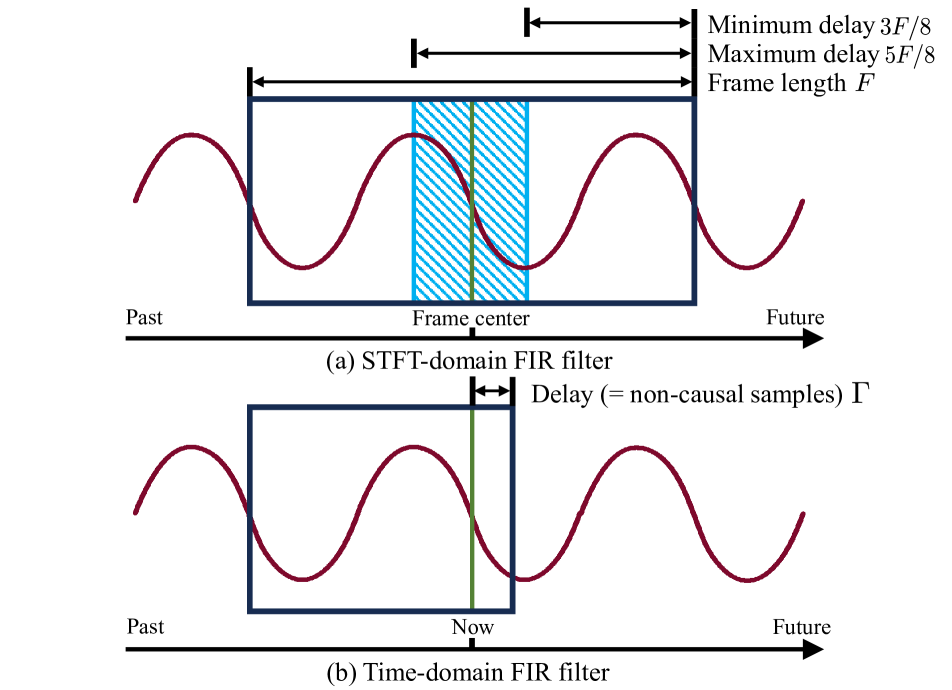
Sample-Truncating IVA: To reduce algorithmic delay, the researchers apply IVA to a truncated segment of the input audio, rather than the full signal. This "sample-truncating" approach trades off some separation/dereverberation performance for lower latency.
-
Online Processing: The system operates in an online fashion, processing the audio in real-time without requiring any future information. This is important for low-latency applications.
The paper evaluates the proposed method on speech separation and dereverberation tasks, comparing it to prior approaches. The results show that the sample-truncating IVA can achieve significantly lower algorithmic delay while still providing meaningful speech enhancement.
Critical Analysis
The paper presents a novel and practical approach to the challenge of low-latency speech enhancement. The combination of IVA and sample-truncation is an interesting technical solution, and the online, real-time processing capability is a valuable capability.
However, the paper does not extensively discuss the potential limitations or tradeoffs of this approach. For example, it's unclear how the separation and dereverberation performance scales as the truncation length is reduced to achieve lower delay. There may be a point where the quality degrades unacceptably.
Additionally, the paper focuses solely on objective metrics like signal-to-noise ratio and does not evaluate the perceptual quality of the enhanced speech. Real-world applications may have specific requirements around intelligibility, naturalness, and user satisfaction that are not captured by the reported metrics.
Further research could explore the robustness of the approach to different acoustic environments, speaker characteristics, and noise types. Comparisons to [<a href="https://aimodels.fyi/papers/arxiv/determined-multichannel-blind-source-separation-clustered-source">other low-latency speech enhancement methods</a>] would also help contextualize the strengths and limitations of this technique.
Conclusion
This paper presents a novel low-latency implementation of a convolutional beamformer for joint source separation and dereverberation. By combining IVA with a sample-truncating approach, the researchers have developed a system capable of real-time speech enhancement with significantly reduced algorithmic delay.
The technical contributions of this work could enable more seamless and natural-sounding communication in applications like video conferencing, virtual assistants, and online music processing. Further research is needed to fully understand the performance tradeoffs and perceptual quality of the enhanced speech, but this paper represents an important step towards low-latency speech processing solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Low algorithmic delay implementation of convolutional beamformer for online joint source separation and dereverberation
Kaien Mo, Xianrui Wang, Yichen Yang, Shoji Makino, Jingdong Chen
Blind-audio-source-separation (BASS) techniques, particularly those with low latency, play an important role in a wide range of real-time systems, e.g., hearing aids, in-car hand-free voice communication, real-time human-machine interaction, etc. Most existing BASS algorithms are deduced to run on batch mode, and therefore large latency is unavoidable. Recently, some online algorithms were developed, which achieve separation on a frame-by-frame basis in the short-time-Fourier-transform (STFT) domain and the latency is significantly reduced as compared to those batch methods. However, the latency with these algorithms may still be too long for many real-time systems to bear. To further reduce latency while achieving good separation performance, we propose in this work to integrate a weighted prediction error (WPE) module into a non-causal sample-truncating-based independent vector analysis (NST-IVA). The resulting algorithm can maintain the algorithmic delay as NST-IVA if the delay with WPE is appropriately controlled while achieving significantly better performance, which is validated by simulations.
Read more6/17/2024

0
DSP-informed bandwidth extension using locally-conditioned excitation and linear time-varying filter subnetworks
Shahan Nercessian, Alexey Lukin, Johannes Imort
In this paper, we propose a dual-stage architecture for bandwidth extension (BWE) increasing the effective sampling rate of speech signals from 8 kHz to 48 kHz. Unlike existing end-to-end deep learning models, our proposed method explicitly models BWE using excitation and linear time-varying (LTV) filter stages. The excitation stage broadens the spectrum of the input, while the filtering stage properly shapes it based on outputs from an acoustic feature predictor. To this end, an acoustic feature loss term can implicitly promote the excitation subnetwork to produce white spectra in the upper frequency band to be synthesized. Experimental results demonstrate that the added inductive bias provided by our approach can improve upon BWE results using the generators from both SEANet or HiFi-GAN as exciters, and that our means of adapting processing with acoustic feature predictions is more effective than that used in HiFi-GAN-2. Secondary contributions include extensions of the SEANet model to accommodate local conditioning information, as well as the application of HiFi-GAN-2 for the BWE problem.
Read more7/23/2024
🤔
0
BAST: Binaural Audio Spectrogram Transformer for Binaural Sound Localization
Sheng Kuang, Jie Shi, Kiki van der Heijden, Siamak Mehrkanoon
Accurate sound localization in a reverberation environment is essential for human auditory perception. Recently, Convolutional Neural Networks (CNNs) have been utilized to model the binaural human auditory pathway. However, CNN shows barriers in capturing the global acoustic features. To address this issue, we propose a novel end-to-end Binaural Audio Spectrogram Transformer (BAST) model to predict the sound azimuth in both anechoic and reverberation environments. Two modes of implementation, i.e. BAST-SP and BAST-NSP corresponding to BAST model with shared and non-shared parameters respectively, are explored. Our model with subtraction interaural integration and hybrid loss achieves an angular distance of 1.29 degrees and a Mean Square Error of 1e-3 at all azimuths, significantly surpassing CNN based model. The exploratory analysis of the BAST's performance on the left-right hemifields and anechoic and reverberation environments shows its generalization ability as well as the feasibility of binaural Transformers in sound localization. Furthermore, the analysis of the attention maps is provided to give additional insights on the interpretation of the localization process in a natural reverberant environment.
Read more8/9/2024

0
New!Ultra-Low Latency Speech Enhancement - A Comprehensive Study
Haibin Wu, Sebastian Braun
Speech enhancement models should meet very low latency requirements typically smaller than 5 ms for hearing assistive devices. While various low-latency techniques have been proposed, comparing these methods in a controlled setup using DNNs remains blank. Previous papers have variations in task, training data, scripts, and evaluation settings, which make fair comparison impossible. Moreover, all methods are tested on small, simulated datasets, making it difficult to fairly assess their performance in real-world conditions, which could impact the reliability of scientific findings. To address these issues, we comprehensively investigate various low-latency techniques using consistent training on large-scale data and evaluate with more relevant metrics on real-world data. Specifically, we explore the effectiveness of asymmetric windows, learnable windows, adaptive time domain filterbanks, and the future-frame prediction technique. Additionally, we examine whether increasing the model size can compensate for the reduced window size, as well as the novel Mamba architecture in low-latency environments.
Read more9/17/2024