Lower Bounds on the Expressivity of Recurrent Neural Language Models
2405.19222
0
0
🧠
Abstract
The recent successes and spread of large neural language models (LMs) call for a thorough understanding of their computational ability. Describing their computational abilities through LMs' emph{representational capacity} is a lively area of research. However, investigation into the representational capacity of neural LMs has predominantly focused on their ability to emph{recognize} formal languages. For example, recurrent neural networks (RNNs) with Heaviside activations are tightly linked to regular languages, i.e., languages defined by finite-state automata (FSAs). Such results, however, fall short of describing the capabilities of RNN emph{language models} (LMs), which are definitionally emph{distributions} over strings. We take a fresh look at the representational capacity of RNN LMs by connecting them to emph{probabilistic} FSAs and demonstrate that RNN LMs with linearly bounded precision can express arbitrary regular LMs.
Create account to get full access
Overview
- This paper examines the expressivity, or representational power, of recurrent neural language models (RNNLMs) - a type of deep learning model commonly used for natural language processing tasks.
- The authors investigate the theoretical limits of what RNNLMs can represent, providing lower bounds on their expressivity.
- This work builds on prior research on the expressive capacity of state-space models and the capabilities of large language models.
Plain English Explanation
The paper looks at how powerful recurrent neural network language models (RNNLMs) can be. RNNLMs are a type of deep learning model commonly used for tasks like text generation and language understanding. The authors investigate the theoretical limits of what these models can represent - in other words, the boundaries of their expressivity or representational power.
They provide mathematical proofs that establish lower bounds on the expressivity of RNNLMs. This means they show the minimum level of complexity that these models can capture, based on their underlying structure and architecture.
This work builds on previous research that has examined the expressive capacity of similar state-space models as well as the capabilities and limitations of large language models more broadly.
Technical Explanation
The authors prove several theoretical results about the expressivity of RNNLMs. First, they show that RNNLMs with a fixed hidden state size cannot recognize all regular languages - a fundamental class of formal languages. This establishes a lower bound on the expressivity of these models.
Next, the authors demonstrate that RNNLMs can, however, represent all context-free languages - a more expressive class of formal languages. This is done by constructing an RNNLM that can simulate a push-down automaton, which is a fundamental model of computation for context-free languages.
The paper also presents results on the representational capacity of linear recurrent neural networks, a restricted form of RNNLMs, and their ability to recognize regular languages.
Critical Analysis
The authors acknowledge several limitations of their work. First, the theoretical results are based on idealized models of RNNLMs, and may not fully capture the behavior of practical, trained models. Additionally, the paper does not address the learnability or trainability of these models, which are important practical considerations.
Some readers may also wish the paper explored the implications of these theoretical bounds more thoroughly. For example, how do the expressivity limitations of RNNLMs compare to other model classes, such as transformers or convolutional networks? And what are the potential real-world consequences of these constraints for language modeling and generation tasks?
Nevertheless, this work makes valuable contributions to our fundamental understanding of the representational power of recurrent neural language models. The proofs and insights presented here can help guide the development of more expressive and capable models for natural language processing.
Conclusion
This paper establishes lower bounds on the expressivity of recurrent neural language models, showing that while they can represent a wide range of formal languages, there are fundamental limitations to their representational power.
These theoretical results build on prior work and provide important insights into the capabilities and constraints of this widely-used class of language models. By better understanding the inherent expressivity of RNNLMs, researchers can work to develop more powerful architectures and training techniques to push the boundaries of natural language understanding and generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
On the Representational Capacity of Recurrent Neural Language Models
Franz Nowak, Anej Svete, Li Du, Ryan Cotterell
0
0
This work investigates the computational expressivity of language models (LMs) based on recurrent neural networks (RNNs). Siegelmann and Sontag (1992) famously showed that RNNs with rational weights and hidden states and unbounded computation time are Turing complete. However, LMs define weightings over strings in addition to just (unweighted) language membership and the analysis of the computational power of RNN LMs (RLMs) should reflect this. We extend the Turing completeness result to the probabilistic case, showing how a rationally weighted RLM with unbounded computation time can simulate any deterministic probabilistic Turing machine (PTM) with rationally weighted transitions. Since, in practice, RLMs work in real-time, processing a symbol at every time step, we treat the above result as an upper bound on the expressivity of RLMs. We also provide a lower bound by showing that under the restriction to real-time computation, such models can simulate deterministic real-time rational PTMs.
5/31/2024
🤯
On Efficiently Representing Regular Languages as RNNs
Anej Svete, Robin Shing Moon Chan, Ryan Cotterell
0
0
Recent work by Hewitt et al. (2020) provides an interpretation of the empirical success of recurrent neural networks (RNNs) as language models (LMs). It shows that RNNs can efficiently represent bounded hierarchical structures that are prevalent in human language. This suggests that RNNs' success might be linked to their ability to model hierarchy. However, a closer inspection of Hewitt et al.'s (2020) construction shows that it is not inherently limited to hierarchical structures. This poses a natural question: What other classes of LMs can RNNs efficiently represent? To this end, we generalize Hewitt et al.'s (2020) construction and show that RNNs can efficiently represent a larger class of LMs than previously claimed -- specifically, those that can be represented by a pushdown automaton with a bounded stack and a specific stack update function. Altogether, the efficiency of representing this diverse class of LMs with RNN LMs suggests novel interpretations of their inductive bias.
6/19/2024
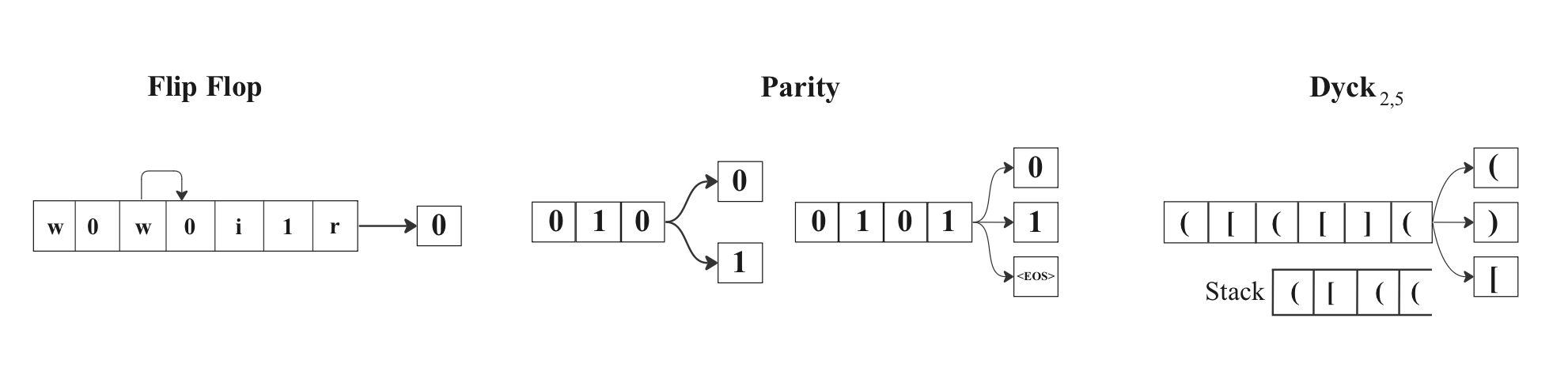
The Expressive Capacity of State Space Models: A Formal Language Perspective
Yash Sarrof, Yana Veitsman, Michael Hahn
0
0
Recently, recurrent models based on linear state space models (SSMs) have shown promising performance in language modeling (LM), competititve with transformers. However, there is little understanding of the in-principle abilities of such models, which could provide useful guidance to the search for better LM architectures. We present a comprehensive theoretical study of the capacity of such SSMs as it compares to that of transformers and traditional RNNs. We find that SSMs and transformers have overlapping but distinct strengths. In star-free state tracking, SSMs implement straightforward and exact solutions to problems that transformers struggle to represent exactly. They can also model bounded hierarchical structure with optimal memory even without simulating a stack. On the other hand, we identify a design choice in current SSMs that limits their expressive power. We discuss implications for SSM and LM research, and verify results empirically on a recent SSM, Mamba.
6/4/2024
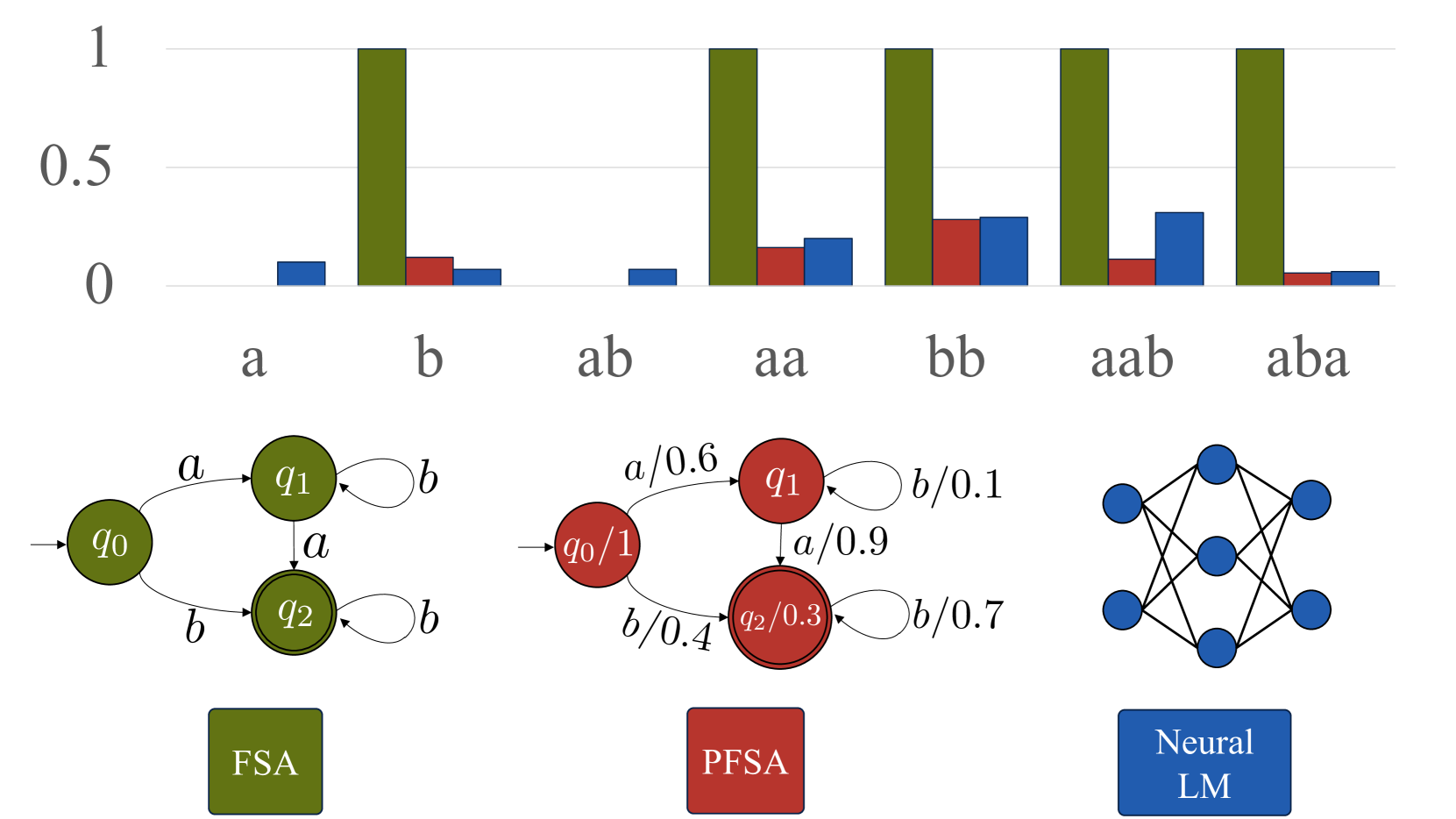
What Languages are Easy to Language-Model? A Perspective from Learning Probabilistic Regular Languages
Nadav Borenstein, Anej Svete, Robin Chan, Josef Valvoda, Franz Nowak, Isabelle Augenstein, Eleanor Chodroff, Ryan Cotterell
0
0
What can large language models learn? By definition, language models (LM) are distributions over strings. Therefore, an intuitive way of addressing the above question is to formalize it as a matter of learnability of classes of distributions over strings. While prior work in this direction focused on assessing the theoretical limits, in contrast, we seek to understand the empirical learnability. Unlike prior empirical work, we evaluate neural LMs on their home turf-learning probabilistic languages-rather than as classifiers of formal languages. In particular, we investigate the learnability of regular LMs (RLMs) by RNN and Transformer LMs. We empirically test the learnability of RLMs as a function of various complexity parameters of the RLM and the hidden state size of the neural LM. We find that the RLM rank, which corresponds to the size of linear space spanned by the logits of its conditional distributions, and the expected length of sampled strings are strong and significant predictors of learnability for both RNNs and Transformers. Several other predictors also reach significance, but with differing patterns between RNNs and Transformers.
6/12/2024