M3GIA: A Cognition Inspired Multilingual and Multimodal General Intelligence Ability Benchmark

0
Sign in to get full access
Overview
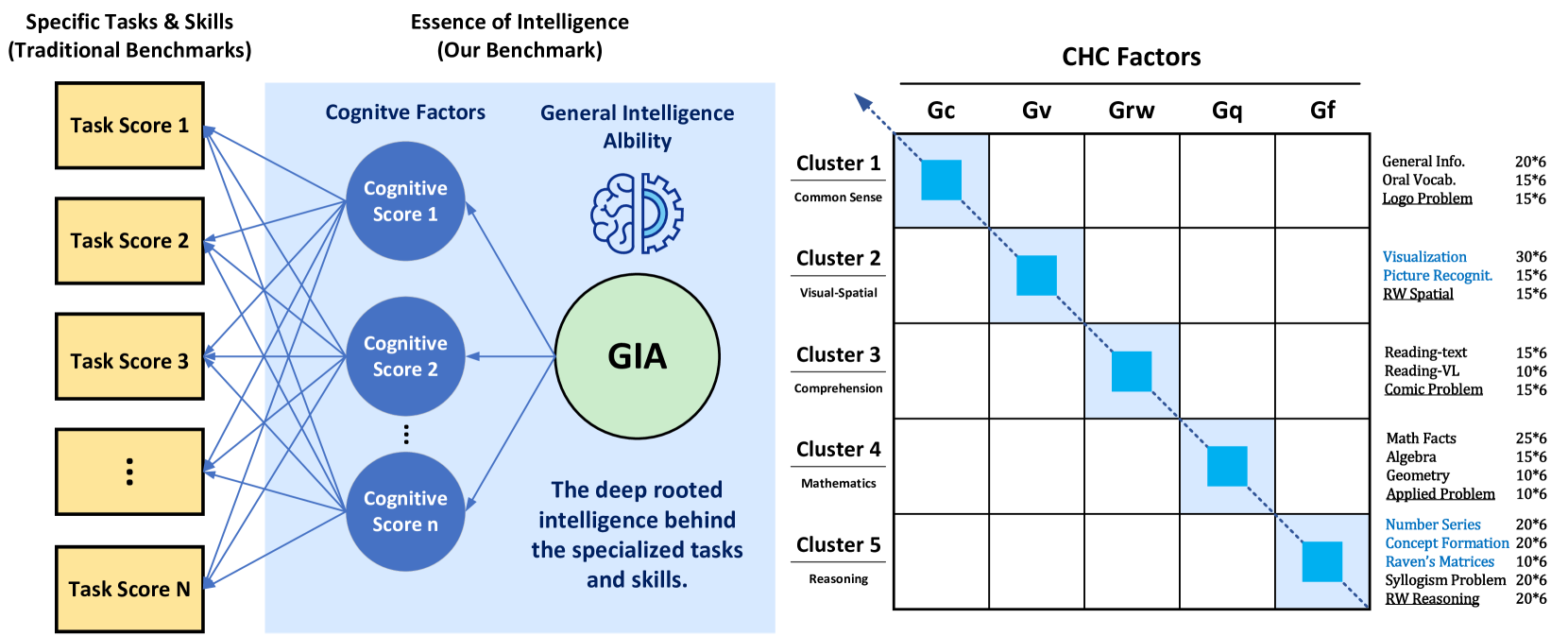
- This paper introduces M3GIA, a new benchmark for evaluating the general intelligence abilities of AI systems across multiple languages and modalities.
- The benchmark is inspired by human cognition and aims to assess a wide range of cognitive skills, including language understanding, reasoning, problem-solving, and multimodal perception.
- The paper outlines the design and implementation of the M3GIA benchmark, as well as the results of initial experiments conducted using state-of-the-art AI models.
Plain English Explanation
The M3GIA benchmark is a new way to test the general intelligence of AI systems. It's inspired by how humans learn and think, and it's designed to evaluate a wide range of cognitive abilities, like understanding language, solving problems, and processing information from different sources (like text, images, and audio).
The researchers who created M3GIA wanted to develop a more comprehensive and challenging way to assess the capabilities of AI models. Many existing benchmarks tend to focus on specific tasks or skills, but the M3GIA benchmark aims to capture a broader range of cognitive abilities that are important for general intelligence.
The researchers tested some of the latest AI models using the M3GIA benchmark, and the results provide insights into the current state of AI and the progress that still needs to be made to achieve true general intelligence.
Technical Explanation
The M3GIA benchmark is designed to assess the general intelligence abilities of AI systems across multiple languages and modalities. It is inspired by the cognitive abilities of humans, who can seamlessly integrate information from various sources and apply their knowledge to solve a wide range of problems.
The benchmark consists of a diverse set of tasks that cover various aspects of cognition, including language understanding, reasoning, problem-solving, and multimodal perception. These tasks are designed to be challenging and require the integration of knowledge from different domains.
The researchers evaluated several state-of-the-art AI models, including language models, vision-language models, and multimodal reasoning models, on the M3GIA benchmark. The results provide insights into the current capabilities and limitations of these models, highlighting areas where further research and development are needed to achieve more general and flexible intelligence.
Critical Analysis
The M3GIA benchmark represents a significant step forward in the evaluation of AI systems, as it aims to capture a more comprehensive and realistic assessment of general intelligence abilities. By incorporating multiple languages and modalities, the benchmark challenges AI models to demonstrate their adaptability and flexibility, which is crucial for achieving human-like intelligence.
However, the benchmark also faces some limitations. The tasks included in the benchmark may not fully capture the depth and complexity of human cognition, and there are still open questions about how to effectively measure and compare the general intelligence of different AI systems.
Additionally, the benchmark relies on the availability of high-quality datasets and the successful integration of various technological components, which can be challenging to achieve in practice. Further research and development will be needed to refine and expand the M3GIA benchmark to make it an even more robust and comprehensive tool for AI evaluation.
Conclusion
The M3GIA benchmark is a valuable contribution to the field of AI research, as it provides a new and more comprehensive approach to evaluating the general intelligence capabilities of AI systems. By assessing a wide range of cognitive skills across multiple languages and modalities, the benchmark has the potential to drive progress towards the development of more flexible, adaptable, and human-like artificial intelligence.
The results of the initial experiments conducted using M3GIA highlight both the current strengths and limitations of state-of-the-art AI models, and they suggest that there is still significant work to be done to achieve the level of general intelligence that is observed in human cognition. Nonetheless, the M3GIA benchmark represents an important step forward in the pursuit of true artificial general intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
M3GIA: A Cognition Inspired Multilingual and Multimodal General Intelligence Ability Benchmark
Wei Song, Yadong Li, Jianhua Xu, Guowei Wu, Lingfeng Ming, Kexin Yi, Weihua Luo, Houyi Li, Yi Du, Fangda Guo, Kaicheng Yu
As recent multi-modality large language models (MLLMs) have shown formidable proficiency on various complex tasks, there has been increasing attention on debating whether these models could eventually mirror human intelligence. However, existing benchmarks mainly focus on evaluating solely on task performance, such as the accuracy of identifying the attribute of an object. Combining well-developed cognitive science to understand the intelligence of MLLMs beyond superficial achievements remains largely unexplored. To this end, we introduce the first cognitive-driven multi-lingual and multi-modal benchmark to evaluate the general intelligence ability of MLLMs, dubbed M3GIA. Specifically, we identify five key cognitive factors based on the well-recognized Cattell-Horn-Carrol (CHC) model of intelligence and propose a novel evaluation metric. In addition, since most MLLMs are trained to perform in different languages, a natural question arises: is language a key factor influencing the cognitive ability of MLLMs? As such, we go beyond English to encompass other languages based on their popularity, including Chinese, French, Spanish, Portuguese and Korean, to construct our M3GIA. We make sure all the data relevant to the cultural backgrounds are collected from their native context to avoid English-centric bias. We collected a significant corpus of data from human participants, revealing that the most advanced MLLM reaches the lower boundary of human intelligence in English. Yet, there remains a pronounced disparity in the other five languages assessed. We also reveals an interesting winner takes all phenomenon that are aligned with the discovery in cognitive studies. Our benchmark will be open-sourced, with the aspiration of facilitating the enhancement of cognitive capabilities in MLLMs.
Read more6/17/2024

34
Evidence of interrelated cognitive-like capabilities in large language models: Indications of artificial general intelligence or achievement?
David Ili'c, Gilles E. Gignac
Large language models (LLMs) are advanced artificial intelligence (AI) systems that can perform a variety of tasks commonly found in human intelligence tests, such as defining words, performing calculations, and engaging in verbal reasoning. There are also substantial individual differences in LLM capacities. Given the consistent observation of a positive manifold and general intelligence factor in human samples, along with group-level factors (e.g., crystallized intelligence), we hypothesized that LLM test scores may also exhibit positive intercorrelations, which could potentially give rise to an artificial general ability (AGA) factor and one or more group-level factors. Based on a sample of 591 LLMs and scores from 12 tests aligned with fluid reasoning (Gf), domain-specific knowledge (Gkn), reading/writing (Grw), and quantitative knowledge (Gq), we found strong empirical evidence for a positive manifold and a general factor of ability. Additionally, we identified a combined Gkn/Grw group-level factor. Finally, the number of LLM parameters correlated positively with both general factor of ability and Gkn/Grw factor scores, although the effects showed diminishing returns. We interpreted our results to suggest that LLMs, like human cognitive abilities, may share a common underlying efficiency in processing information and solving problems, though whether LLMs manifest primarily achievement/expertise rather than intelligence remains to be determined. Finally, while models with greater numbers of parameters exhibit greater general cognitive-like abilities, akin to the connection between greater neuronal density and human general intelligence, other characteristics must also be involved.
Read more9/12/2024
🤔
0
GAOKAO-MM: A Chinese Human-Level Benchmark for Multimodal Models Evaluation
Yi Zong, Xipeng Qiu
The Large Vision-Language Models (LVLMs) have demonstrated great abilities in image perception and language understanding. However, existing multimodal benchmarks focus on primary perception abilities and commonsense knowledge which are insufficient to reflect the comprehensive capabilities of LVLMs. We propose GAOKAO-MM, a multimodal benchmark based on the Chinese College Entrance Examination (GAOKAO), comprising of 8 subjects and 12 types of images, such as diagrams, function graphs, maps and photos. GAOKAO-MM derives from native Chinese context and sets human-level requirements for the model's abilities, including perception, understanding, knowledge and reasoning. We evaluate 10 LVLMs and find that the accuracies of all of them are lower than 50%, with GPT-4-Vison (48.1%), Qwen-VL-Plus (41.2%) and Gemini-Pro-Vision (35.1%) ranking in the top three positions. The results of our multi-dimension analysis indicate that LVLMs have moderate distance towards Artificial General Intelligence (AGI) and provide insights facilitating the development of multilingual LVLMs.
Read more8/7/2024
🤔
0
CMMMU: A Chinese Massive Multi-discipline Multimodal Understanding Benchmark
Ge Zhang, Xinrun Du, Bei Chen, Yiming Liang, Tongxu Luo, Tianyu Zheng, Kang Zhu, Yuyang Cheng, Chunpu Xu, Shuyue Guo, Haoran Zhang, Xingwei Qu, Junjie Wang, Ruibin Yuan, Yizhi Li, Zekun Wang, Yudong Liu, Yu-Hsuan Tsai, Fengji Zhang, Chenghua Lin, Wenhao Huang, Jie Fu
As the capabilities of large multimodal models (LMMs) continue to advance, evaluating the performance of LMMs emerges as an increasing need. Additionally, there is an even larger gap in evaluating the advanced knowledge and reasoning abilities of LMMs in non-English contexts such as Chinese. We introduce CMMMU, a new Chinese Massive Multi-discipline Multimodal Understanding benchmark designed to evaluate LMMs on tasks demanding college-level subject knowledge and deliberate reasoning in a Chinese context. CMMMU is inspired by and strictly follows the annotation and analysis pattern of MMMU. CMMMU includes 12k manually collected multimodal questions from college exams, quizzes, and textbooks, covering six core disciplines: Art & Design, Business, Science, Health & Medicine, Humanities & Social Science, and Tech & Engineering, like its companion, MMMU. These questions span 30 subjects and comprise 39 highly heterogeneous image types, such as charts, diagrams, maps, tables, music sheets, and chemical structures. CMMMU focuses on complex perception and reasoning with domain-specific knowledge in the Chinese context. We evaluate 11 open-source LLMs and one proprietary GPT-4V(ision). Even GPT-4V only achieves accuracies of 42%, indicating a large space for improvement. CMMMU will boost the community to build the next-generation LMMs towards expert artificial intelligence and promote the democratization of LMMs by providing diverse language contexts.
Read more9/10/2024