Machine-learning-based particle identification with missing data

0
📊
Sign in to get full access
Overview
- This paper introduces a novel method for Particle Identification (PID) within the ALICE experiment at the Large Hadron Collider (LHC) at CERN.
- Identifying products of ultra-relativistic collisions is a crucial objective for the ALICE experiment.
- Existing PID methods rely on hand-crafted selections that compare experimental data to theoretical simulations.
- Novel approaches using machine learning models have improved performance, but struggle with incomplete data where not all particles are detected.
- The proposed method can be trained on all available data, including incomplete examples, improving PID purity and efficiency.
Plain English Explanation
The ALICE experiment at the Large Hadron Collider (LHC) in CERN is tasked with identifying the various particles produced in ultra-high-energy collisions. Typically, this is done by comparing the experimental data collected by the ALICE detectors to theoretical simulations of what the particles should look like. However, this approach has limitations, as the detectors don't always pick up signals from every single particle.
To address this, researchers have started using machine learning models to try to improve the particle identification process. These models can learn the patterns in the data and make more accurate classifications. But the machine learning techniques have trouble with the incomplete data, where some particles aren't detected - they can't be trained on examples with missing information.
In this work, the researchers propose a new method that can handle the incomplete data. Instead of ignoring the partial information, their approach is able to use all the available data, even if some of the particle signals are missing. This allows them to train more robust models that achieve better purity and efficiency in identifying the different particle types produced in the ALICE experiment.
Technical Explanation
The paper introduces a novel method for Particle Identification (PID) within the ALICE experiment at the LHC. Identifying the products of ultra-relativistic collisions is a crucial objective for ALICE. Traditional PID methods rely on hand-crafted selections that compare experimental data to theoretical simulations.
To improve upon these baseline techniques, recent approaches have used machine learning models that learn to classify the particles. However, due to limitations in detector efficiency and acceptance, the data collected often has missing values where not all particles are detected by the various ALICE subdetectors.
Machine learning models cannot be trained on these incomplete examples, so a significant portion of the data is discarded during training. The key innovation in this work is a method that can be trained on all available data, including the incomplete examples with missing values.
This approach improves the PID purity and efficiency for all the investigated particle species compared to prior techniques. The researchers demonstrate the effectiveness of their method on real data from the ALICE experiment.
Critical Analysis
The paper presents a valuable contribution by addressing the challenge of incomplete data in particle identification for the ALICE experiment. The proposed approach's ability to utilize all available data, even with missing values, is a significant advantage over prior machine learning techniques that required complete examples.
However, the paper does not provide in-depth discussion of potential limitations or caveats. For instance, it is unclear how the method would scale to higher levels of missing data, or how it might perform compared to other techniques that could impute or interpolate the missing values.
Additionally, the paper focuses on improving PID metrics like purity and efficiency, but does not explore the downstream impact on physics analyses or event reconstruction that rely on accurate particle identification. Further research could investigate these real-world implications.
Overall, the work represents an important step forward, but additional exploration of the method's limitations and potential broader applications would strengthen the critical analysis.
Conclusion
This paper introduces a novel approach for Particle Identification (PID) within the ALICE experiment at the LHC that can effectively utilize incomplete data with missing values.
The key innovation is the ability to train machine learning models on all available data, including examples where not all particles are detected by the ALICE subdetectors. This results in improved PID purity and efficiency compared to prior techniques that could only use complete data.
The work addresses an important challenge in high-energy particle physics experiments and demonstrates the potential for machine learning methods to enhance particle identification and event reconstruction, even in the face of real-world data limitations. Further research could explore the scalability, robustness, and broader implications of this approach.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
Machine-learning-based particle identification with missing data
Mi{l}osz Kasak, Kamil Deja, Maja Karwowska, Monika Jakubowska, {L}ukasz Graczykowski, Ma{l}gorzata Janik
In this work, we introduce a novel method for Particle Identification (PID) within the scope of the ALICE experiment at the Large Hadron Collider at CERN. Identifying products of ultrarelativisitc collisions delivered by the LHC is one of the crucial objectives of ALICE. Typically employed PID methods rely on hand-crafted selections, which compare experimental data to theoretical simulations. To improve the performance of the baseline methods, novel approaches use machine learning models that learn the proper assignment in a classification task. However, because of the various detection techniques used by different subdetectors, as well as the limited detector efficiency and acceptance, produced particles do not always yield signals in all of the ALICE components. This results in data with missing values. Machine learning techniques cannot be trained with such examples, so a significant part of the data is skipped during training. In this work, we propose the first method for PID that can be trained with all of the available data examples, including incomplete ones. Our approach improves the PID purity and efficiency of the selected sample for all investigated particle species.
Read more7/23/2024

0
Particle identification with machine learning from incomplete data in the ALICE experiment
Maja Karwowska (for the ALICE collaboration), {L}ukasz Graczykowski (for the ALICE collaboration), Kamil Deja (for the ALICE collaboration), Mi{l}osz Kasak (for the ALICE collaboration), Ma{l}gorzata Janik (for the ALICE collaboration)
The ALICE experiment at the LHC measures properties of the strongly interacting matter formed in ultrarelativistic heavy-ion collisions. Such studies require accurate particle identification (PID). ALICE provides PID information via several detectors for particles with momentum from about 100 MeV/c up to 20 GeV/c. Traditionally, particles are selected with rectangular cuts. A much better performance can be achieved with machine learning (ML) methods. Our solution uses multiple neural networks (NN) serving as binary classifiers. Moreover, we extended our particle classifier with Feature Set Embedding and attention in order to train on data with incomplete samples. We also present the integration of the ML project with the ALICE analysis software, and we discuss domain adaptation, the ML technique needed to transfer the knowledge between simulated and real experimental data.
Read more7/26/2024

0
Novel Approaches for ML-Assisted Particle Track Reconstruction and Hit Clustering
Uraz Odyurt, Nadezhda Dobreva, Zef Wolffs, Yue Zhao, Antonio Ferrer S'anchez, Roberto Ruiz de Austri Bazan, Jos'e D. Mart'in-Guerrero, Ana-Lucia Varbanescu, Sascha Caron
Track reconstruction is a vital aspect of High-Energy Physics (HEP) and plays a critical role in major experiments. In this study, we delve into unexplored avenues for particle track reconstruction and hit clustering. Firstly, we enhance the algorithmic design effort by utilising a simplified simulator (REDVID) to generate training data that is specifically composed for simplicity. We demonstrate the effectiveness of this data in guiding the development of optimal network architectures. Additionally, we investigate the application of image segmentation networks for this task, exploring their potential for accurate track reconstruction. Moreover, we approach the task from a different perspective by treating it as a hit sequence to track sequence translation problem. Specifically, we explore the utilisation of Transformer architectures for tracking purposes. Our preliminary findings are covered in detail. By considering this novel approach, we aim to uncover new insights and potential advancements in track reconstruction. This research sheds light on previously unexplored methods and provides valuable insights for the field of particle track reconstruction and hit clustering in HEP.
Read more5/28/2024
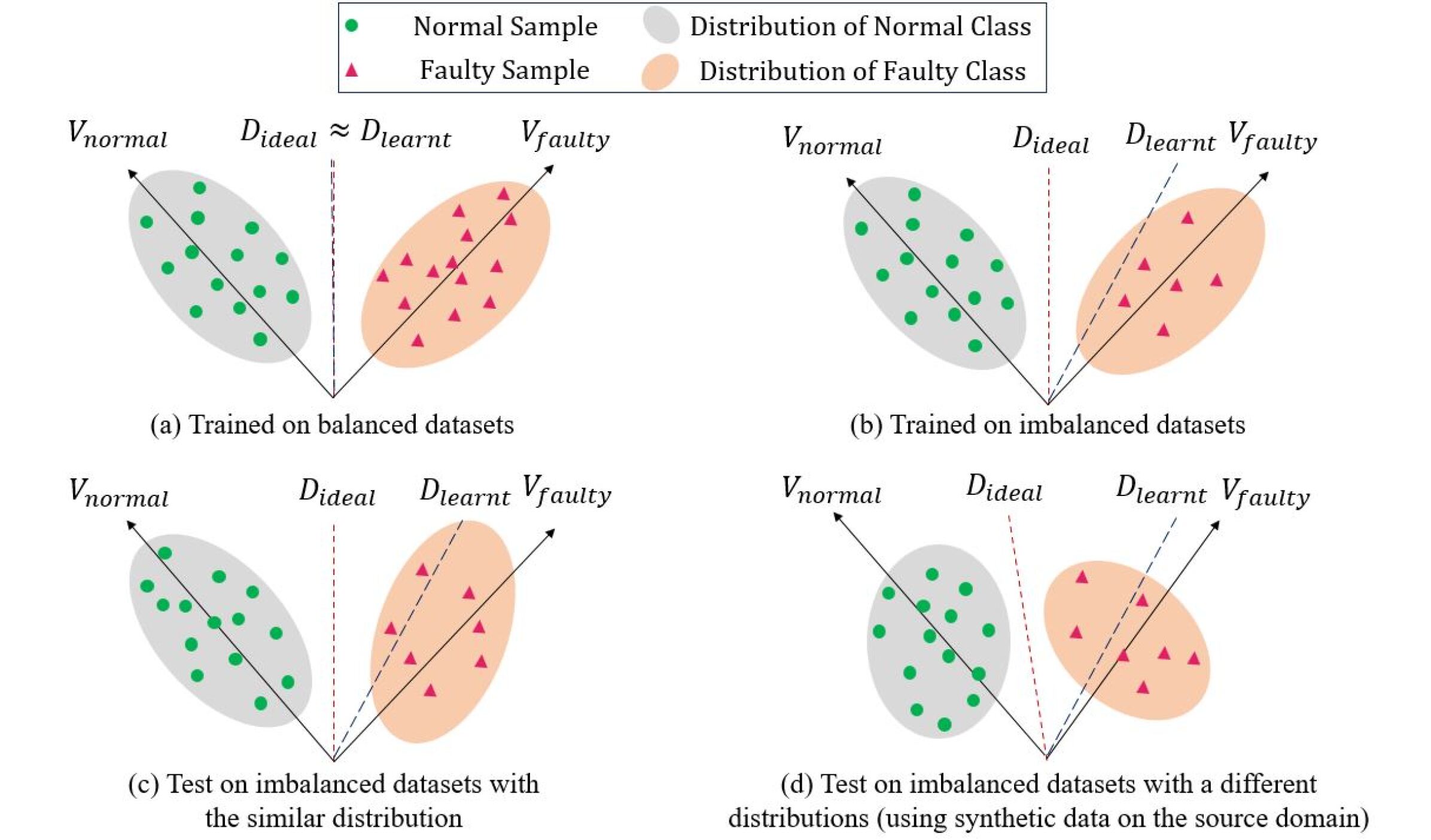
0
Physics-Informed Deep Learning and Partial Transfer Learning for Bearing Fault Diagnosis in the Presence of Highly Missing Data
Mohammadreza Kavianpour, Parisa Kavianpour, Amin Ramezani
One of the most significant obstacles in bearing fault diagnosis is a lack of labeled data for various fault types. Also, sensor-acquired data frequently lack labels and have a large amount of missing data. This paper tackles these issues by presenting the PTPAI method, which uses a physics-informed deep learning-based technique to generate synthetic labeled data. Labeled synthetic data makes up the source domain, whereas unlabeled data with missing data is present in the target domain. Consequently, imbalanced class problems and partial-set fault diagnosis hurdles emerge. To address these challenges, the RF-Mixup approach is used to handle imbalanced classes. As domain adaptation strategies, the MK-MMSD and CDAN are employed to mitigate the disparity in distribution between synthetic and actual data. Furthermore, the partial-set challenge is tackled by applying weighting methods at the class and instance levels. Experimental outcomes on the CWRU and JNU datasets indicate that the proposed approach effectively addresses these problems.
Read more6/18/2024