The Machine Psychology of Cooperation: Can GPT models operationalise prompts for altruism, cooperation, competitiveness and selfishness in economic games?

0
✅
Sign in to get full access
Overview
- The study investigated the capability of the GPT-3.5 large language model (LLM) to operationalize natural language descriptions of different social behaviors in two classic economic games: the repeated Prisoner's Dilemma and the one-shot Dictator Game.
- The researchers used a within-subject experimental design, where they manipulated the prompt describing the simulated persona's cooperative and competitive stances.
- They then assessed the resulting simulacra's level of cooperation in each social dilemma, considering the effect of different partner conditions for the repeated game.
Plain English Explanation
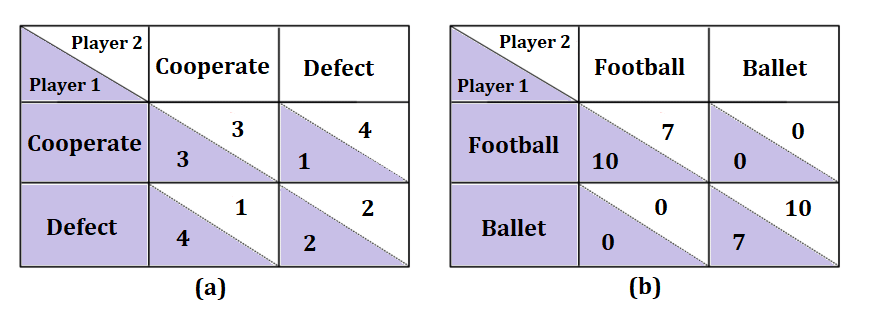
The researchers wanted to see if a powerful AI language model like GPT-3.5 could understand and act out different types of social behaviors, like cooperation, competition, altruism, and self-interest. To test this, they used a well-known psychology experiment setup called the Prisoner's Dilemma and the Dictator Game.
In the Prisoner's Dilemma, two "prisoners" have to decide whether to cooperate with each other or betray one another. In the Dictator Game, one person (the "dictator") decides how to divide a resource between themselves and another person.
The researchers gave the AI language model a prompt that described a person with a certain social stance, like being cooperative or competitive. They then had the AI play these games and looked at how it behaved - whether it cooperated, competed, or acted selfishly. They found that the AI could, to some extent, translate the descriptions of social behavior into the appropriate actions in the games, especially in the one-shot Dictator Game.
For the repeated Prisoner's Dilemma, the AI's behavior sometimes resembled "conditional reciprocity," where it would cooperate if its partner cooperated, but compete if the partner competed. The researchers also saw some evidence of altruistic behavior from the AI in later versions of the model.
This research has important implications for using AI chatbots in situations that involve cooperation, like in negotiations over shared resources. The AI could potentially act as a mediator or facilitator, helping people work together more effectively.
Technical Explanation
The researchers conducted a within-subject experiment to assess the capability of the GPT-3.5 large language model (LLM) to operationalize natural language descriptions of cooperative, competitive, altruistic, and self-interested behavior in two classic social dilemmas: the repeated Prisoner's Dilemma and the one-shot Dictator Game.
The researchers used a similar protocol to that used in experimental psychology studies with human subjects, where they provided a prompt to the LLM to create a simulated persona with different cooperative and competitive stances. They then assessed the resulting simulacra's level of cooperation in each social dilemma, taking into account the effect of different partner conditions for the repeated Prisoner's Dilemma game.
The results provide evidence that LLMs can, to some extent, translate natural language descriptions of different cooperative stances into corresponding descriptions of appropriate task behavior, particularly in the one-shot Dictator Game. There is some evidence of behavior resembling conditional reciprocity for the cooperative simulacra in the repeated Prisoner's Dilemma, and for the later version of the model, there is evidence of altruistic behavior.
The study has potential implications for using LLM chatbots in task environments that involve cooperation, such as using chatbots as mediators and facilitators in public-goods negotiations. See related work on using LLMs for negotiation and cooperation.
Critical Analysis
The paper provides a well-designed experiment to explore the capability of LLMs to operationalize different social behaviors, but it also acknowledges several limitations and areas for further research.
One key limitation is that the study only used a single LLM (GPT-3.5) and a limited set of social dilemma tasks. It would be valuable to see how other LLM architectures and a broader range of social interaction scenarios would fare. Additional research is needed to fully assess the nature and limitations of LLMs in this domain.
Another potential concern is the extent to which the LLM's behavior truly reflects an understanding of the social dynamics, versus simply pattern-matching the prompted descriptions to appropriate game moves. Further investigation into the underlying mechanisms and decision-making processes of the LLM would help clarify this.
There are also important questions around the potential for LLMs to engage in strategic deception or manipulation, which was not explored in this particular study. Understanding the ethical implications of using LLMs in social interaction scenarios is a critical area for continued research.
Conclusion
This study provides valuable insights into the capability of large language models like GPT-3.5 to operationalize natural language descriptions of different social behaviors in classic economic games. The results suggest that LLMs can, to some extent, translate these descriptions into corresponding task behaviors, particularly in one-shot interactions.
The findings have important implications for the potential use of LLM-powered chatbots as mediators or facilitators in cooperative task environments, such as public-goods negotiations. However, further research is needed to fully understand the limitations and ethical considerations of deploying LLMs in social interaction scenarios.
Overall, this study contributes to the growing body of work on the capabilities and limitations of large language models, and highlights the need for continued exploration and caution as these powerful AI systems are applied to more complex social and interactive domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
✅
0
The Machine Psychology of Cooperation: Can GPT models operationalise prompts for altruism, cooperation, competitiveness and selfishness in economic games?
Steve Phelps, Yvan I. Russell
We investigated the capability of the GPT-3.5 large language model (LLM) to operationalize natural language descriptions of cooperative, competitive, altruistic, and self-interested behavior in two social dilemmas: the repeated Prisoners Dilemma and the one-shot Dictator Game. Using a within-subject experimental design, we used a prompt to describe the task environment using a similar protocol to that used in experimental psychology studies with human subjects. We tested our research question by manipulating the part of our prompt which was used to create a simulated persona with different cooperative and competitive stances. We then assessed the resulting simulacras' level of cooperation in each social dilemma, taking into account the effect of different partner conditions for the repeated game. Our results provide evidence that LLMs can, to some extent, translate natural language descriptions of different cooperative stances into corresponding descriptions of appropriate task behaviour, particularly in the one-shot game. There is some evidence of behaviour resembling conditional reciprocity for the cooperative simulacra in the repeated game, and for the later version of the model there is evidence of altruistic behaviour. Our study has potential implications for using LLM chatbots in task environments that involve cooperation, e.g. using chatbots as mediators and facilitators in public-goods negotiations.
Read more7/2/2024
0
The Good, the Bad, and the Hulk-like GPT: Analyzing Emotional Decisions of Large Language Models in Cooperation and Bargaining Games
Mikhail Mozikov, Nikita Severin, Valeria Bodishtianu, Maria Glushanina, Mikhail Baklashkin, Andrey V. Savchenko, Ilya Makarov
Behavior study experiments are an important part of society modeling and understanding human interactions. In practice, many behavioral experiments encounter challenges related to internal and external validity, reproducibility, and social bias due to the complexity of social interactions and cooperation in human user studies. Recent advances in Large Language Models (LLMs) have provided researchers with a new promising tool for the simulation of human behavior. However, existing LLM-based simulations operate under the unproven hypothesis that LLM agents behave similarly to humans as well as ignore a crucial factor in human decision-making: emotions. In this paper, we introduce a novel methodology and the framework to study both, the decision-making of LLMs and their alignment with human behavior under emotional states. Experiments with GPT-3.5 and GPT-4 on four games from two different classes of behavioral game theory showed that emotions profoundly impact the performance of LLMs, leading to the development of more optimal strategies. While there is a strong alignment between the behavioral responses of GPT-3.5 and human participants, particularly evident in bargaining games, GPT-4 exhibits consistent behavior, ignoring induced emotions for rationality decisions. Surprisingly, emotional prompting, particularly with `anger' emotion, can disrupt the superhuman alignment of GPT-4, resembling human emotional responses.
Read more6/6/2024

0
Nicer Than Humans: How do Large Language Models Behave in the Prisoner's Dilemma?
Nicol'o Fontana, Francesco Pierri, Luca Maria Aiello
The behavior of Large Language Models (LLMs) as artificial social agents is largely unexplored, and we still lack extensive evidence of how these agents react to simple social stimuli. Testing the behavior of AI agents in classic Game Theory experiments provides a promising theoretical framework for evaluating the norms and values of these agents in archetypal social situations. In this work, we investigate the cooperative behavior of three LLMs (Llama2, Llama3, and GPT3.5) when playing the Iterated Prisoner's Dilemma against random adversaries displaying various levels of hostility. We introduce a systematic methodology to evaluate an LLM's comprehension of the game rules and its capability to parse historical gameplay logs for decision-making. We conducted simulations of games lasting for 100 rounds and analyzed the LLMs' decisions in terms of dimensions defined in the behavioral economics literature. We find that all models tend not to initiate defection but act cautiously, favoring cooperation over defection only when the opponent's defection rate is low. Overall, LLMs behave at least as cooperatively as the typical human player, although our results indicate some substantial differences among models. In particular, Llama2 and GPT3.5 are more cooperative than humans, and especially forgiving and non-retaliatory for opponent defection rates below 30%. More similar to humans, Llama3 exhibits consistently uncooperative and exploitative behavior unless the opponent always cooperates. Our systematic approach to the study of LLMs in game theoretical scenarios is a step towards using these simulations to inform practices of LLM auditing and alignment.
Read more9/20/2024

0
Are Large Language Models Aligned with People's Social Intuitions for Human-Robot Interactions?
Lennart Wachowiak, Andrew Coles, Oya Celiktutan, Gerard Canal
Large language models (LLMs) are increasingly used in robotics, especially for high-level action planning. Meanwhile, many robotics applications involve human supervisors or collaborators. Hence, it is crucial for LLMs to generate socially acceptable actions that align with people's preferences and values. In this work, we test whether LLMs capture people's intuitions about behavior judgments and communication preferences in human-robot interaction (HRI) scenarios. For evaluation, we reproduce three HRI user studies, comparing the output of LLMs with that of real participants. We find that GPT-4 strongly outperforms other models, generating answers that correlate strongly with users' answers in two studies $unicode{x2014}$ the first study dealing with selecting the most appropriate communicative act for a robot in various situations ($r_s$ = 0.82), and the second with judging the desirability, intentionality, and surprisingness of behavior ($r_s$ = 0.83). However, for the last study, testing whether people judge the behavior of robots and humans differently, no model achieves strong correlations. Moreover, we show that vision models fail to capture the essence of video stimuli and that LLMs tend to rate different communicative acts and behavior desirability higher than people.
Read more7/10/2024