MapVision: CVPR 2024 Autonomous Grand Challenge Mapless Driving Tech Report
2406.10125
0
0

Abstract
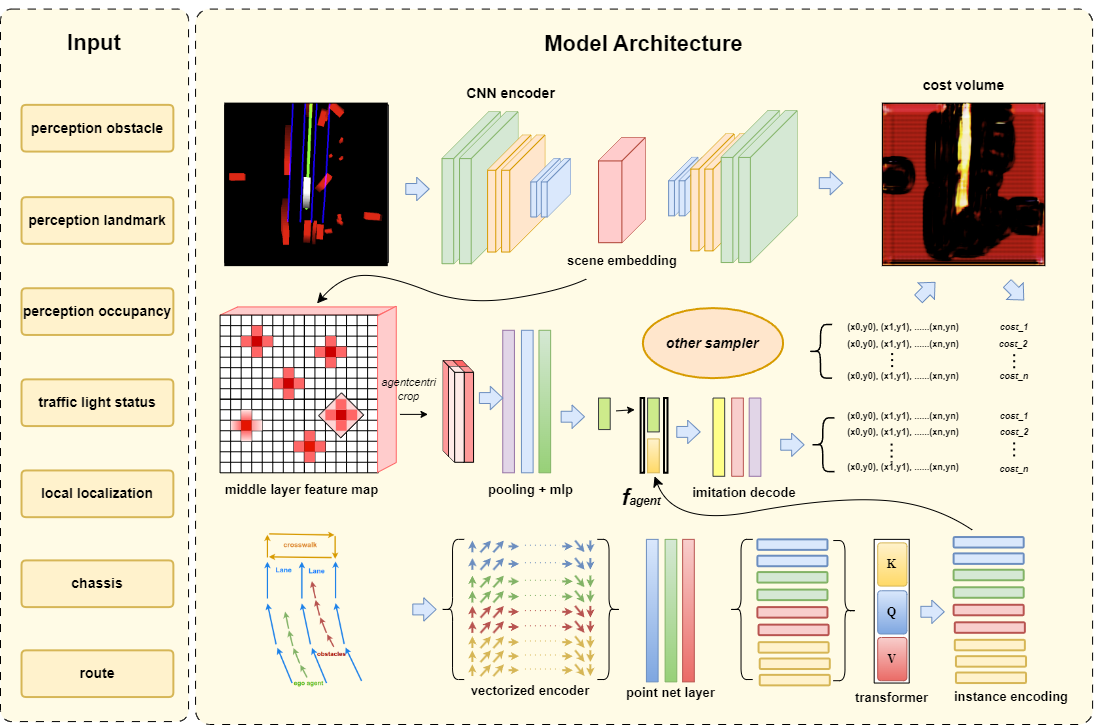
Autonomous driving without high-definition (HD) maps demands a higher level of active scene understanding. In this competition, the organizers provided the multi-perspective camera images and standard-definition (SD) maps to explore the boundaries of scene reasoning capabilities. We found that most existing algorithms construct Bird's Eye View (BEV) features from these multi-perspective images and use multi-task heads to delineate road centerlines, boundary lines, pedestrian crossings, and other areas. However, these algorithms perform poorly at the far end of roads and struggle when the primary subject in the image is occluded. Therefore, in this competition, we not only used multi-perspective images as input but also incorporated SD maps to address this issue. We employed map encoder pre-training to enhance the network's geometric encoding capabilities and utilized YOLOX to improve traffic element detection precision. Additionally, for area detection, we innovatively introduced LDTR and auxiliary tasks to achieve higher precision. As a result, our final OLUS score is 0.58.
Create account to get full access
Overview
- The paper presents MapVision, a novel approach for autonomous driving in challenging environments without relying on high-definition (HD) maps.
- The system uses a combination of deep learning models to perceive the environment, estimate the vehicle's location, and plan a safe driving trajectory.
- The proposed method was evaluated in the CVPR 2024 Autonomous Grand Challenge, where it demonstrated robust performance in complex, mapless scenarios.
Plain English Explanation
The researchers developed a system called MapVision that allows self-driving cars to navigate without the need for detailed maps of the environment. This is an important capability, as creating and maintaining highly accurate maps can be very costly and time-consuming, especially in dynamic or changing environments.
Instead of relying on pre-existing maps, MapVision uses a suite of deep learning models to perceive its surroundings, figure out where it is located, and plan a safe path forward. The system takes in data from the vehicle's sensors, such as cameras and LiDAR, and processes this information to build a comprehensive understanding of the scene. It can detect obstacles, identify drivable areas, and estimate the car's position relative to its environment.
[letsmap-unsupervised-representation-learning-semantic-bev-mapping] Using this information, MapVision can then plan an optimal route through the environment, avoiding hazards and navigating smoothly to its destination. This allows the self-driving car to operate effectively even in areas where detailed maps may not be available, such as construction zones, rural roads, or rapidly changing urban environments.
The researchers put MapVision to the test in the CVPR 2024 Autonomous Grand Challenge, a high-profile competition that evaluates the capabilities of self-driving technologies. In this challenging, mapless scenario, MapVision demonstrated robust performance, showcasing its potential to enable more flexible and adaptable autonomous driving systems.
Technical Explanation
The core of the MapVision system is a deep neural network architecture that combines several specialized models for different perception and planning tasks. At the heart of the system is a [monocular-localization-semantics-map-autonomous-vehicles] semantic mapping module that constructs a detailed bird's-eye-view representation of the environment using monocular camera input.
This semantic mapping module is trained in an unsupervised manner to learn a compact, yet informative, representation of the scene, capturing essential elements like drivable surfaces, obstacles, and lane markings. By leveraging this rich semantic understanding of the environment, the system can then accurately localize the vehicle within the scene and plan an optimal trajectory.
The [gad-generative-learning-hd-map-free-autonomous] trajectory planning component of MapVision uses a generative adversarial network (GAN) to learn how to navigate through complex, mapless environments. The GAN is trained on a large dataset of driving demonstrations, enabling it to generate driving policies that mimic human-like behavior while avoiding collisions and staying within the bounds of the drivable area.
To further improve the robustness of the system, the researchers incorporated techniques from [benchmarking-improving-birds-eye-view-perception-robustness], which specifically address the challenges of perception in diverse, real-world driving conditions. This includes methods for enhancing the accuracy and reliability of the semantic mapping module, even in the face of occlusions, lighting changes, or other environmental factors.
Critical Analysis
The MapVision approach represents a significant step forward in the field of autonomous driving, as it demonstrates the potential for reliable, map-free navigation in complex environments. By shifting the focus from reliance on pre-built maps to a more dynamic, perception-driven approach, the researchers have opened up new avenues for developing autonomous systems that can adapt to a wider range of scenarios.
However, the paper does acknowledge some limitations and areas for further research. For example, the performance of the system may be sensitive to the quality and coverage of the training data used to develop the various deep learning models. Expanding the diversity of the training data, or exploring techniques for domain adaptation, could help improve the system's robustness to new and unseen environments.
Additionally, the researchers note that the computational requirements of the MapVision system may be a practical concern, as the real-time processing of sensor data and planning of trajectories must be done efficiently on-board the vehicle. Optimizing the neural network architectures and exploring hardware acceleration techniques could be important next steps to address this challenge.
Finally, while the CVPR 2024 Autonomous Grand Challenge provided a valuable testbed for evaluating the system's performance, it would be beneficial to further validate the approach in real-world driving scenarios, where additional factors, such as interactions with other road users and dynamic obstacles, could pose additional challenges.
Conclusion
The MapVision system represents a significant advancement in the field of autonomous driving, demonstrating the potential for reliable navigation in complex, mapless environments. By leveraging deep learning models for perception, localization, and trajectory planning, the researchers have developed a flexible and adaptive approach that can operate effectively without the need for detailed, pre-built maps.
The successful performance of MapVision in the CVPR 2024 Autonomous Grand Challenge suggests that this technology could be a crucial enabler for the widespread deployment of self-driving vehicles, particularly in areas where the creation and maintenance of high-definition maps may be impractical or cost-prohibitive. As the researchers continue to refine and expand the capabilities of the system, it could pave the way for more robust, versatile, and accessible autonomous driving solutions in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

LGmap: Local-to-Global Mapping Network for Online Long-Range Vectorized HD Map Construction
Kuang Wu, Sulei Nian, Can Shen, Chuan Yang, Zhanbin Li
0
0
This report introduces the first-place winning solution for the Autonomous Grand Challenge 2024 - Mapless Driving. In this report, we introduce a novel online mapping pipeline LGmap, which adept at long-range temporal model. Firstly, we propose symmetric view transformation(SVT), a hybrid view transformation module. Our approach overcomes the limitations of forward sparse feature representation and utilizing depth perception and SD prior information. Secondly, we propose hierarchical temporal fusion(HTF) module. It employs temporal information from local to global, which empowers the construction of long-range HD map with high stability. Lastly, we propose a novel ped-crossing resampling. The simplified ped crossing representation accelerates the instance attention based decoder convergence performance. Our method achieves 0.66 UniScore in the Mapless Driving OpenLaneV2 test set.
6/21/2024

LetsMap: Unsupervised Representation Learning for Semantic BEV Mapping
Nikhil Gosala, Kursat Petek, B Ravi Kiran, Senthil Yogamani, Paulo Drews-Jr, Wolfram Burgard, Abhinav Valada
0
0
Semantic Bird's Eye View (BEV) maps offer a rich representation with strong occlusion reasoning for various decision making tasks in autonomous driving. However, most BEV mapping approaches employ a fully supervised learning paradigm that relies on large amounts of human-annotated BEV ground truth data. In this work, we address this limitation by proposing the first unsupervised representation learning approach to generate semantic BEV maps from a monocular frontal view (FV) image in a label-efficient manner. Our approach pretrains the network to independently reason about scene geometry and scene semantics using two disjoint neural pathways in an unsupervised manner and then finetunes it for the task of semantic BEV mapping using only a small fraction of labels in the BEV. We achieve label-free pretraining by exploiting spatial and temporal consistency of FV images to learn scene geometry while relying on a novel temporal masked autoencoder formulation to encode the scene representation. Extensive evaluations on the KITTI-360 and nuScenes datasets demonstrate that our approach performs on par with the existing state-of-the-art approaches while using only 1% of BEV labels and no additional labeled data.
5/30/2024

Monocular Localization with Semantics Map for Autonomous Vehicles
Jixiang Wan, Xudong Zhang, Shuzhou Dong, Yuwei Zhang, Yuchen Yang, Ruoxi Wu, Ye Jiang, Jijunnan Li, Jinquan Lin, Ming Yang
0
0
Accurate and robust localization remains a significant challenge for autonomous vehicles. The cost of sensors and limitations in local computational efficiency make it difficult to scale to large commercial applications. Traditional vision-based approaches focus on texture features that are susceptible to changes in lighting, season, perspective, and appearance. Additionally, the large storage size of maps with descriptors and complex optimization processes hinder system performance. To balance efficiency and accuracy, we propose a novel lightweight visual semantic localization algorithm that employs stable semantic features instead of low-level texture features. First, semantic maps are constructed offline by detecting semantic objects, such as ground markers, lane lines, and poles, using cameras or LiDAR sensors. Then, online visual localization is performed through data association of semantic features and map objects. We evaluated our proposed localization framework in the publicly available KAIST Urban dataset and in scenarios recorded by ourselves. The experimental results demonstrate that our method is a reliable and practical localization solution in various autonomous driving localization tasks.
6/7/2024
GAD-Generative Learning for HD Map-Free Autonomous Driving
Weijian Sun, Yanbo Jia, Qi Zeng, Zihao Liu, Jiang Liao, Yue Li, Xianfeng Li
0
0
Deep-learning-based techniques have been widely adopted for autonomous driving software stacks for mass production in recent years, focusing primarily on perception modules, with some work extending this method to prediction modules. However, the downstream planning and control modules are still designed with hefty handcrafted rules, dominated by optimization-based methods such as quadratic programming or model predictive control. This results in a performance bottleneck for autonomous driving systems in that corner cases simply cannot be solved by enumerating hand-crafted rules. We present a deep-learning-based approach that brings prediction, decision, and planning modules together with the attempt to overcome the rule-based methods' deficiency in real-world applications of autonomous driving, especially for urban scenes. The DNN model we proposed is solely trained with 10 hours of human driver data, and it supports all mass-production ADAS features available on the market to date. This method is deployed onto a Jiyue test car with no modification to its factory-ready sensor set and compute platform. the feasibility, usability, and commercial potential are demonstrated in this article.
6/3/2024