Monocular Localization with Semantics Map for Autonomous Vehicles
2406.03835
0
0

Abstract
Accurate and robust localization remains a significant challenge for autonomous vehicles. The cost of sensors and limitations in local computational efficiency make it difficult to scale to large commercial applications. Traditional vision-based approaches focus on texture features that are susceptible to changes in lighting, season, perspective, and appearance. Additionally, the large storage size of maps with descriptors and complex optimization processes hinder system performance. To balance efficiency and accuracy, we propose a novel lightweight visual semantic localization algorithm that employs stable semantic features instead of low-level texture features. First, semantic maps are constructed offline by detecting semantic objects, such as ground markers, lane lines, and poles, using cameras or LiDAR sensors. Then, online visual localization is performed through data association of semantic features and map objects. We evaluated our proposed localization framework in the publicly available KAIST Urban dataset and in scenarios recorded by ourselves. The experimental results demonstrate that our method is a reliable and practical localization solution in various autonomous driving localization tasks.
Create account to get full access
Overview
- This paper presents a monocular localization system for autonomous vehicles that uses a semantic map to improve localization accuracy.
- The system combines visual features extracted from a monocular camera with semantic information from a pre-built map to determine the vehicle's precise location.
- The authors evaluate their approach on real-world datasets and demonstrate improved localization performance compared to existing methods.
Plain English Explanation
The researchers have developed a new way for self-driving cars to figure out exactly where they are on the road. Typically, these cars use sensors like cameras and lasers to try to match what they see around them with a pre-made map. However, this can be challenging in complex urban environments with lots of moving objects and changing conditions.
To address this, the researchers' system combines the visual information from a single camera with semantic data from a detailed map of the driving environment. The semantic map includes information about things like the types of objects (e.g. buildings, trees, road signs) and their locations. By matching this semantic data with what the camera sees, the system can more accurately pinpoint the vehicle's position.
The researchers tested their approach on real-world driving datasets and found that it outperformed existing localization methods. This could be an important step towards making self-driving cars more reliable and precise in navigating the real world.
Technical Explanation
The paper presents a monocular localization system for autonomous vehicles that leverages a pre-built semantic map to improve localization accuracy. The system combines visual features extracted from a single camera with semantic information from the map to determine the vehicle's precise location.
The key components of the system include:
- A monocular camera that captures visual data from the vehicle's perspective.
- A pre-built semantic map that encodes information about the types and locations of objects in the environment (e.g. buildings, trees, road signs).
- A matching algorithm that aligns the visual features observed by the camera with the semantic data in the map to infer the vehicle's position.
The authors evaluate their approach on real-world driving datasets and demonstrate that it outperforms existing monocular localization methods. The semantic information from the map helps resolve ambiguities that can arise when relying solely on visual features, leading to more accurate and robust localization.
Critical Analysis
The paper presents a compelling approach to improving localization for autonomous vehicles, but there are a few potential limitations and areas for further research:
- The system relies on a pre-built semantic map, which may be challenging or expensive to create and maintain in the real world. [Related to Real-Time 3D Semantic Occupancy Prediction for Autonomous Vehicles]
- The evaluation is conducted on a limited set of datasets, and it's unclear how well the system would generalize to more diverse driving environments. [Related to Mapping High-Level Semantic Regions in Indoor Environments]
- The paper does not address how the system would handle dynamic changes in the environment, such as construction or new objects, which could affect the accuracy of the semantic map. [Related to Collaborative Semantic Occupancy Prediction with Hybrid Feature Fusion]
- The authors do not explore the potential for open-set recognition, where the system could detect and incorporate new semantic elements not present in the original map. [Related to Open-Set 3D Semantic Instance Maps from Vision]
- The paper does not discuss how the proposed approach could be integrated with other localization techniques, such as those using multiple sensors or prior information about the vehicle's state. [Related to Bayesian Simultaneous Localization and Multi-Lane Tracking Using]
Overall, the paper presents a promising approach, but further research is needed to address these potential limitations and explore the system's real-world applicability and robustness.
Conclusion
This paper introduces a monocular localization system for autonomous vehicles that leverages a pre-built semantic map to improve localization accuracy. By combining visual features from a single camera with semantic information about the environment, the system can more precisely determine the vehicle's position, outperforming existing monocular localization methods.
While the approach shows promise, there are several areas for further research and refinement, such as addressing the reliance on a pre-built map, ensuring robustness to dynamic changes in the environment, and exploring integrations with other localization techniques. If these challenges can be addressed, the proposed system could represent an important step towards more reliable and precise navigation for self-driving cars.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
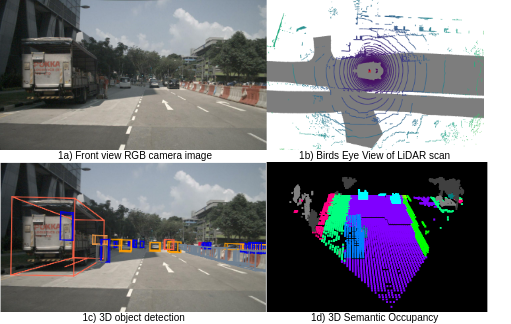
Real-time 3D semantic occupancy prediction for autonomous vehicles using memory-efficient sparse convolution
Samuel Sze, Lars Kunze
0
0
In autonomous vehicles, understanding the surrounding 3D environment of the ego vehicle in real-time is essential. A compact way to represent scenes while encoding geometric distances and semantic object information is via 3D semantic occupancy maps. State of the art 3D mapping methods leverage transformers with cross-attention mechanisms to elevate 2D vision-centric camera features into the 3D domain. However, these methods encounter significant challenges in real-time applications due to their high computational demands during inference. This limitation is particularly problematic in autonomous vehicles, where GPU resources must be shared with other tasks such as localization and planning. In this paper, we introduce an approach that extracts features from front-view 2D camera images and LiDAR scans, then employs a sparse convolution network (Minkowski Engine), for 3D semantic occupancy prediction. Given that outdoor scenes in autonomous driving scenarios are inherently sparse, the utilization of sparse convolution is particularly apt. By jointly solving the problems of 3D scene completion of sparse scenes and 3D semantic segmentation, we provide a more efficient learning framework suitable for real-time applications in autonomous vehicles. We also demonstrate competitive accuracy on the nuScenes dataset.
5/21/2024
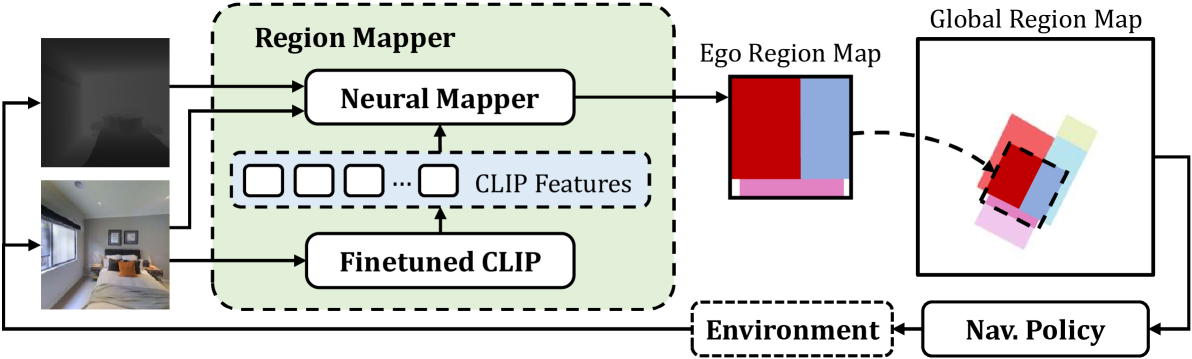
Mapping High-level Semantic Regions in Indoor Environments without Object Recognition
Roberto Bigazzi, Lorenzo Baraldi, Shreyas Kousik, Rita Cucchiara, Marco Pavone
0
0
Robots require a semantic understanding of their surroundings to operate in an efficient and explainable way in human environments. In the literature, there has been an extensive focus on object labeling and exhaustive scene graph generation; less effort has been focused on the task of purely identifying and mapping large semantic regions. The present work proposes a method for semantic region mapping via embodied navigation in indoor environments, generating a high-level representation of the knowledge of the agent. To enable region identification, the method uses a vision-to-language model to provide scene information for mapping. By projecting egocentric scene understanding into the global frame, the proposed method generates a semantic map as a distribution over possible region labels at each location. This mapping procedure is paired with a trained navigation policy to enable autonomous map generation. The proposed method significantly outperforms a variety of baselines, including an object-based system and a pretrained scene classifier, in experiments in a photorealistic simulator.
4/16/2024
🔮
Collaborative Semantic Occupancy Prediction with Hybrid Feature Fusion in Connected Automated Vehicles
Rui Song, Chenwei Liang, Hu Cao, Zhiran Yan, Walter Zimmer, Markus Gross, Andreas Festag, Alois Knoll
0
0
Collaborative perception in automated vehicles leverages the exchange of information between agents, aiming to elevate perception results. Previous camera-based collaborative 3D perception methods typically employ 3D bounding boxes or bird's eye views as representations of the environment. However, these approaches fall short in offering a comprehensive 3D environmental prediction. To bridge this gap, we introduce the first method for collaborative 3D semantic occupancy prediction. Particularly, it improves local 3D semantic occupancy predictions by hybrid fusion of (i) semantic and occupancy task features, and (ii) compressed orthogonal attention features shared between vehicles. Additionally, due to the lack of a collaborative perception dataset designed for semantic occupancy prediction, we augment a current collaborative perception dataset to include 3D collaborative semantic occupancy labels for a more robust evaluation. The experimental findings highlight that: (i) our collaborative semantic occupancy predictions excel above the results from single vehicles by over 30%, and (ii) models anchored on semantic occupancy outpace state-of-the-art collaborative 3D detection techniques in subsequent perception applications, showcasing enhanced accuracy and enriched semantic-awareness in road environments.
4/26/2024

MapVision: CVPR 2024 Autonomous Grand Challenge Mapless Driving Tech Report
Zhongyu Yang, Mai Liu, Jinluo Xie, Yueming Zhang, Chen Shen, Wei Shao, Jichao Jiao, Tengfei Xing, Runbo Hu, Pengfei Xu
0
0
Autonomous driving without high-definition (HD) maps demands a higher level of active scene understanding. In this competition, the organizers provided the multi-perspective camera images and standard-definition (SD) maps to explore the boundaries of scene reasoning capabilities. We found that most existing algorithms construct Bird's Eye View (BEV) features from these multi-perspective images and use multi-task heads to delineate road centerlines, boundary lines, pedestrian crossings, and other areas. However, these algorithms perform poorly at the far end of roads and struggle when the primary subject in the image is occluded. Therefore, in this competition, we not only used multi-perspective images as input but also incorporated SD maps to address this issue. We employed map encoder pre-training to enhance the network's geometric encoding capabilities and utilized YOLOX to improve traffic element detection precision. Additionally, for area detection, we innovatively introduced LDTR and auxiliary tasks to achieve higher precision. As a result, our final OLUS score is 0.58.
6/17/2024