Match, Compare, or Select? An Investigation of Large Language Models for Entity Matching
2405.16884
0
0

Abstract
Entity matching (EM) is a critical step in entity resolution (ER). Recently, entity matching based on large language models (LLMs) has shown great promise. However, current LLM-based entity matching approaches typically follow a binary matching paradigm that ignores the global consistency between record relationships. In this paper, we investigate various methodologies for LLM-based entity matching that incorporate record interactions from different perspectives. Specifically, we comprehensively compare three representative strategies: matching, comparing, and selecting, and analyze their respective advantages and challenges in diverse scenarios. Based on our findings, we further design a compound entity matching framework (ComEM) that leverages the composition of multiple strategies and LLMs. ComEM benefits from the advantages of different sides and achieves improvements in both effectiveness and efficiency. Experimental results on 8 ER datasets and 9 LLMs verify the superiority of incorporating record interactions through the selecting strategy, as well as the further cost-effectiveness brought by ComEM.
Create account to get full access
Overview
- This paper investigates the use of large language models (LLMs) for entity matching, which is the task of identifying when two pieces of text refer to the same real-world entity.
- The authors explore three different approaches: matching, comparison, and selection.
- They test these approaches on several benchmark datasets and provide insights into the strengths and limitations of each approach.
Plain English Explanation
The paper looks at how powerful language models, known as large language models (LLMs), can be used to automatically match up pieces of text that refer to the same real-world thing or "entity". This is an important task in many applications, like organizing databases or analyzing social media posts.
The researchers tried three different ways of using LLMs for this entity matching task:
- Matching: Directly comparing the text to see if it refers to the same thing.
- Comparison: Ranking how similar two pieces of text are to each other.
- Selection: Choosing the most relevant piece of text from a set of options.
They tested these approaches on standard datasets used for evaluating entity matching, to see how well each one performed. The paper provides insights into the pros and cons of each approach and gives guidance on when to use which method.
Technical Explanation
The paper explores the use of large language models (LLMs) for the task of entity matching. Entity matching is the problem of identifying when two pieces of text refer to the same real-world entity.
The authors investigate three different approaches for leveraging LLMs for this task:
- Matching: Directly comparing the text representations produced by an LLM to determine if they match.
- Comparison: Using the LLM to generate a similarity score between two text inputs, allowing them to be ranked.
- Selection: Framing entity matching as a selection task, where the LLM chooses the most relevant option from a set of candidates.
The authors evaluate these approaches on several benchmark datasets for entity matching, including FEVER, TACRED, and SciERC. They analyze the strengths and weaknesses of each approach, providing insights into when to use each method.
Critical Analysis
The paper provides a thorough and well-designed investigation of using LLMs for entity matching. The authors carefully consider multiple approaches and evaluate them on diverse datasets, generating valuable insights for practitioners.
One potential limitation is that the study is focused on English-language datasets. It would be interesting to see how the approaches perform on entity matching tasks in other languages or across multilingual settings.
Additionally, the paper does not delve deeply into the specific architectural choices or fine-tuning approaches used for the LLMs. Further research could explore how different LLM models or training regimes impact the entity matching performance.
Overall, this paper makes a strong contribution to the understanding of how LLMs can be effectively applied to entity matching, and provides a solid foundation for future work in this area.
Conclusion
This paper presents a comprehensive investigation of using large language models (LLMs) for the task of entity matching. The authors explore three different approaches - matching, comparison, and selection - and evaluate their performance on several benchmark datasets.
The findings provide valuable insights for practitioners looking to leverage LLMs in entity matching applications. The paper highlights the strengths and limitations of each approach, offering guidance on when to employ the different methods.
While the study is focused on the English language, the insights generated have broader implications for the use of LLMs in natural language processing tasks. The paper serves as an important reference for researchers and engineers working to advance the capabilities of LLMs in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Leveraging Large Language Models for Entity Matching
Qianyu Huang, Tongfang Zhao
0
0
Entity matching (EM) is a critical task in data integration, aiming to identify records across different datasets that refer to the same real-world entities. Traditional methods often rely on manually engineered features and rule-based systems, which struggle with diverse and unstructured data. The emergence of Large Language Models (LLMs) such as GPT-4 offers transformative potential for EM, leveraging their advanced semantic understanding and contextual capabilities. This vision paper explores the application of LLMs to EM, discussing their advantages, challenges, and future research directions. Additionally, we review related work on applying weak supervision and unsupervised approaches to EM, highlighting how LLMs can enhance these methods.
6/3/2024
💬
Entity Matching using Large Language Models
Ralph Peeters, Christian Bizer
0
0
Entity Matching is the task of deciding whether two entity descriptions refer to the same real-world entity and is a central step in most data integration pipelines. Many state-of-the-art entity matching methods rely on pre-trained language models (PLMs) such as BERT or RoBERTa. Two major drawbacks of these models for entity matching are that (i) the models require significant amounts of task-specific training data and (ii) the fine-tuned models are not robust concerning out-of-distribution entities. This paper investigates using generative large language models (LLMs) as a less task-specific training data-dependent and more robust alternative to PLM-based matchers. Our study covers hosted and open-source LLMs, which can be run locally. We evaluate these models in a zero-shot scenario and a scenario where task-specific training data is available. We compare different prompt designs and the prompt sensitivity of the models and show that there is no single best prompt but needs to be tuned for each model/dataset combination. We further investigate (i) the selection of in-context demonstrations, (ii) the generation of matching rules, as well as (iii) fine-tuning a hosted LLM using the same pool of training data. Our experiments show that the best LLMs require no or only a few training examples to perform similarly to PLMs that were fine-tuned using thousands of examples. LLM-based matchers further exhibit higher robustness to unseen entities. We show that GPT4 can generate structured explanations for matching decisions. The model can automatically identify potential causes of matching errors by analyzing explanations of wrong decisions. We demonstrate that the model can generate meaningful textual descriptions of the identified error classes, which can help data engineers improve entity matching pipelines.
6/6/2024
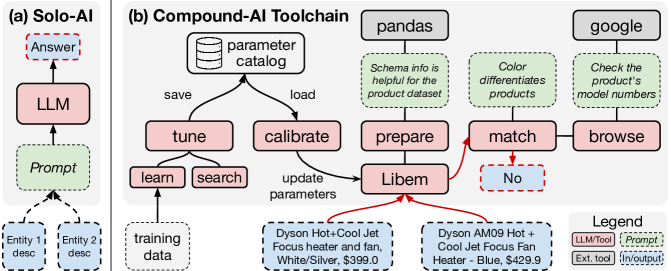
Liberal Entity Matching as a Compound AI Toolchain
Silvery D. Fu, David Wang, Wen Zhang, Kathleen Ge
0
0
Entity matching (EM), the task of identifying whether two descriptions refer to the same entity, is essential in data management. Traditional methods have evolved from rule-based to AI-driven approaches, yet current techniques using large language models (LLMs) often fall short due to their reliance on static knowledge and rigid, predefined prompts. In this paper, we introduce Libem, a compound AI system designed to address these limitations by incorporating a flexible, tool-oriented approach. Libem supports entity matching through dynamic tool use, self-refinement, and optimization, allowing it to adapt and refine its process based on the dataset and performance metrics. Unlike traditional solo-AI EM systems, which often suffer from a lack of modularity that hinders iterative design improvements and system optimization, Libem offers a composable and reusable toolchain. This approach aims to contribute to ongoing discussions and developments in AI-driven data management.
6/18/2024
Disambiguate Entity Matching using Large Language Models through Relation Discovery
Zezhou Huang
0
0
Entity matching is a critical challenge in data integration and cleaning, central to tasks like fuzzy joins and deduplication. Traditional approaches have focused on overcoming fuzzy term representations through methods such as edit distance, Jaccard similarity, and more recently, embeddings and deep neural networks, including advancements from large language models (LLMs) like GPT. However, the core challenge in entity matching extends beyond term fuzziness to the ambiguity in defining what constitutes a match, especially when integrating with external databases. This ambiguity arises due to varying levels of detail and granularity among entities, complicating exact matches. We propose a novel approach that shifts focus from purely identifying semantic similarities to understanding and defining the relations between entities as crucial for resolving ambiguities in matching. By predefining a set of relations relevant to the task at hand, our method allows analysts to navigate the spectrum of similarity more effectively, from exact matches to conceptually related entities.
5/30/2024