A mathematical perspective on Transformers

57

Sign in to get full access
Overview
- Provides a mathematical perspective on Transformers, a popular neural network architecture for tasks like language modeling and machine translation.
- Explores Transformers through the lens of interacting particle systems, clustering, and gradient flows.
- Offers insights into the inner workings and success of Transformers.
Plain English Explanation
Transformers are a type of neural network that have become very popular for tasks like understanding and generating human language. This paper looks at Transformers from a mathematical point of view, using concepts like interacting particle systems, clustering, and gradient flows to try to understand why Transformers work so well.
The key idea is that the self-attention mechanism in Transformers can be viewed as a kind of interacting particle system, where the "particles" are the different parts of the input (like words in a sentence). These particles interact with each other and over time, they cluster together in ways that help the network understand the overall meaning. The authors show how this clustering process is related to optimization through gradient flows, which helps explain the success of Transformers.
By approaching Transformers from this mathematical angle, the paper provides new insights into how they work and why they perform so well on language tasks. This could lead to further developments and improvements in Transformer-based models.
Technical Explanation
The paper models the self-attention mechanism in Transformers as an interacting particle system. Each element in the input sequence (e.g. a word) is represented as a "particle" that interacts with the other particles through the attention computations.
The authors show that this particle system exhibits clustering behavior, where the particles organize themselves into groups that capture semantic relationships in the input. This clustering process is driven by optimization through gradient flows, which helps explain the success of Transformers in tasks like language modeling.
The paper provides a mathematical framework for understanding the inner workings of Transformers, connecting their self-attention mechanism to well-studied concepts in dynamical systems and optimization. This sheds light on why Transformers are able to capture the complex structure of human language so effectively.
Critical Analysis
The paper presents a novel and insightful mathematical perspective on Transformers, but it does have some limitations. The analysis is mostly theoretical, and the authors do not provide extensive empirical validation of their claims. While the connections to interacting particle systems, clustering, and gradient flows are intriguing, more work is needed to fully substantiate these ideas and understand their practical implications.
Additionally, the paper focuses primarily on the self-attention mechanism, but Transformers have other important components (e.g. feed-forward layers, residual connections) that are not as deeply explored. A more comprehensive mathematical treatment of the entire Transformer architecture would be valuable.
Further research could investigate how this particle system perspective relates to other theoretical frameworks for understanding neural networks, and whether it can lead to new architectural innovations or training techniques for Transformers.
Conclusion
This paper provides a fresh mathematical lens for studying the Transformer architecture, highlighting connections to interacting particle systems, clustering, and gradient flows. By modeling the self-attention mechanism in this way, the authors offer new insights into why Transformers are so effective at language tasks.
While the analysis is mostly theoretical, this work lays the groundwork for a deeper mathematical understanding of Transformers and could inspire further developments in this rapidly advancing field of deep learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
57
A mathematical perspective on Transformers
Borjan Geshkovski, Cyril Letrouit, Yury Polyanskiy, Philippe Rigollet
Transformers play a central role in the inner workings of large language models. We develop a mathematical framework for analyzing Transformers based on their interpretation as interacting particle systems, which reveals that clusters emerge in long time. Our study explores the underlying theory and offers new perspectives for mathematicians as well as computer scientists.
Read more8/13/2024

0
Why transformers are obviously good models of language
Felix Hill
Nobody knows how language works, but many theories abound. Transformers are a class of neural networks that process language automatically with more success than alternatives, both those based on neural computations and those that rely on other (e.g. more symbolic) mechanisms. Here, I highlight direct connections between the transformer architecture and certain theoretical perspectives on language. The empirical success of transformers relative to alternative models provides circumstantial evidence that the linguistic approaches that transformers embody should be, at least, evaluated with greater scrutiny by the linguistics community and, at best, considered to be the currently best available theories.
Read more8/9/2024
34
Large Language Models for Mathematicians
Simon Frieder, Julius Berner, Philipp Petersen, Thomas Lukasiewicz
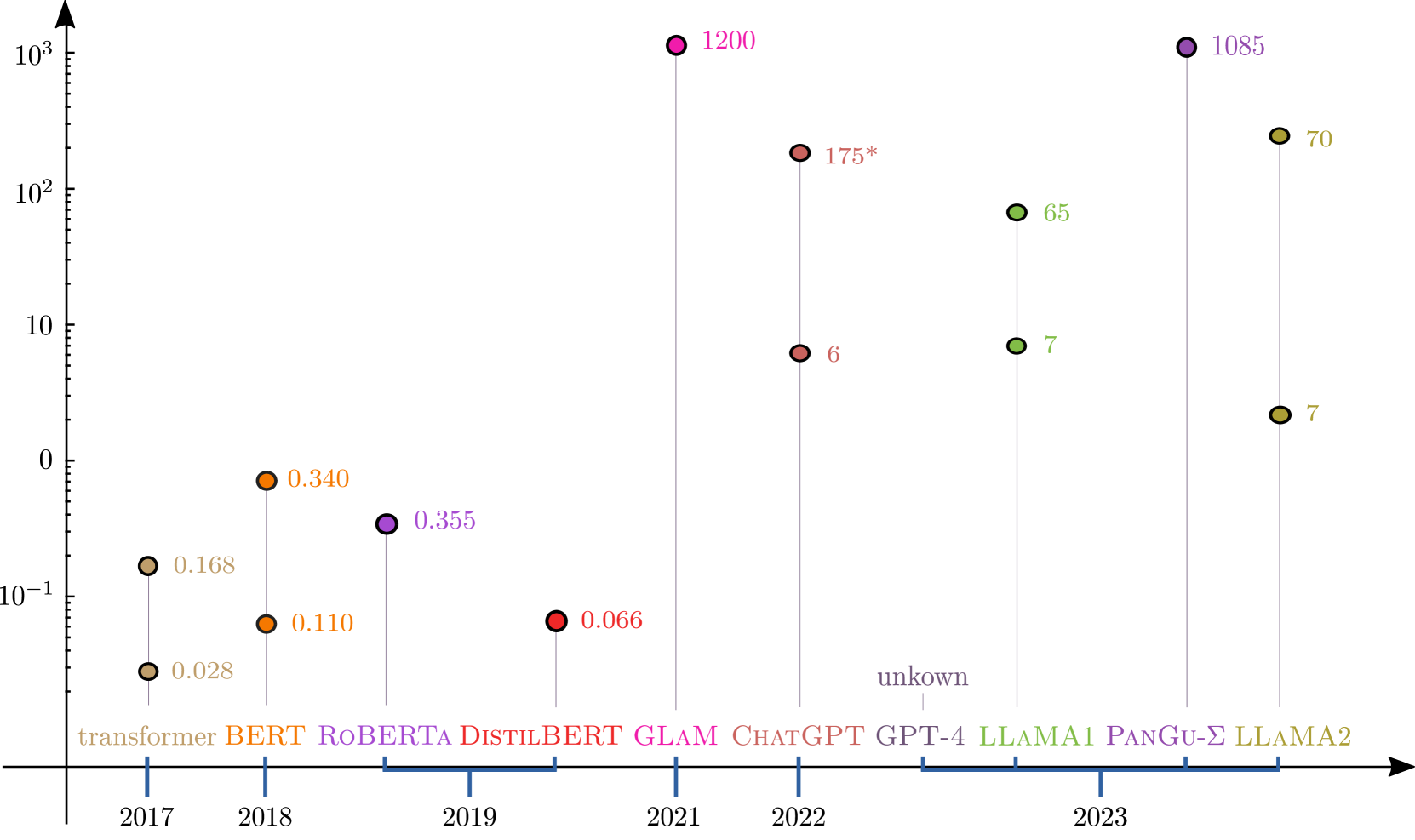
Large language models (LLMs) such as ChatGPT have received immense interest for their general-purpose language understanding and, in particular, their ability to generate high-quality text or computer code. For many professions, LLMs represent an invaluable tool that can speed up and improve the quality of work. In this note, we discuss to what extent they can aid professional mathematicians. We first provide a mathematical description of the transformer model used in all modern language models. Based on recent studies, we then outline best practices and potential issues and report on the mathematical abilities of language models. Finally, we shed light on the potential of LLMs to change how mathematicians work.
Read more4/3/2024
2
A Primer on the Inner Workings of Transformer-based Language Models
Javier Ferrando, Gabriele Sarti, Arianna Bisazza, Marta R. Costa-juss`a
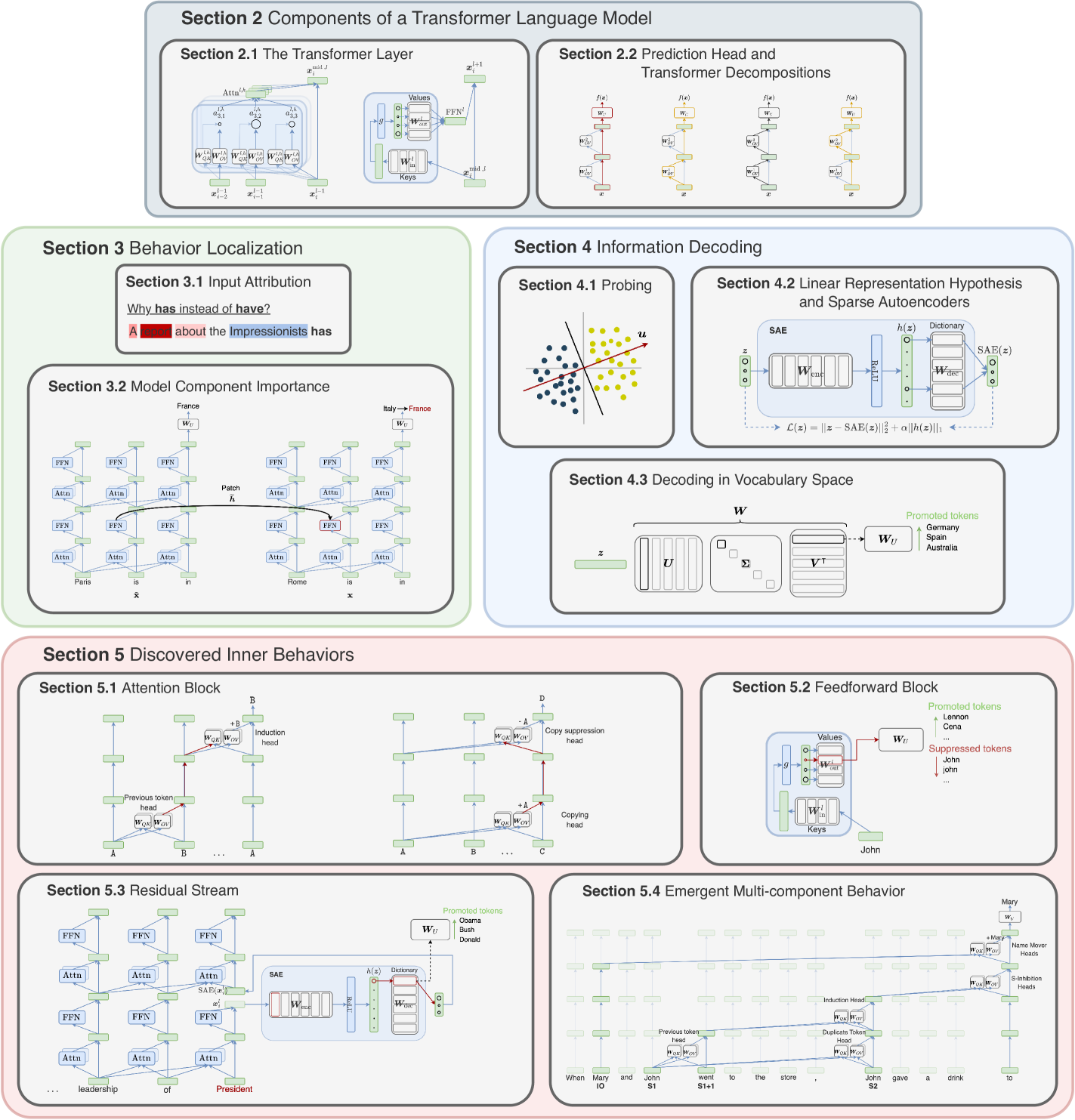
The rapid progress of research aimed at interpreting the inner workings of advanced language models has highlighted a need for contextualizing the insights gained from years of work in this area. This primer provides a concise technical introduction to the current techniques used to interpret the inner workings of Transformer-based language models, focusing on the generative decoder-only architecture. We conclude by presenting a comprehensive overview of the known internal mechanisms implemented by these models, uncovering connections across popular approaches and active research directions in this area.
Read more5/3/2024