MCUNetV2: Memory-Efficient Patch-based Inference for Tiny Deep Learning

0
🤯
Sign in to get full access
Overview
- Tiny deep learning on microcontrollers is challenging due to limited memory
- The memory bottleneck is caused by imbalanced memory distribution in convolutional neural network (CNN) designs
- Researchers propose a patch-by-patch inference scheduling and network redistribution to address the memory issue
Plain English Explanation
Deep learning models, which power many modern AI applications, are typically designed to run on powerful computers or servers. However, there is growing interest in running these models on tiny, low-power microcontroller units (MCUs) found in many everyday devices. This "tiny deep learning" is very challenging due to the severe memory constraints of MCUs.
The researchers identified a key reason for this memory challenge - the way convolutional neural network (CNN) models are structured leads to an imbalance in memory usage. The initial layers of the network require much more memory than the later layers. This memory bottleneck limits the ability to run complex deep learning models on MCUs.
To solve this problem, the researchers developed two key innovations. First, they created a "patch-by-patch" inference scheduling system. This breaks up the input image into smaller patches, and processes each patch independently. This dramatically reduces the peak memory usage compared to processing the entire image at once.
However, this patch-based approach introduced some new challenges, like overlapping computations between patches. To address this, the researchers then "redistributed" the network, shifting more of the computation and memory usage to the later layers of the network. This optimization reduced the overhead of the patch-based approach.
Manually redesigning the network architecture and inference scheduling is very difficult. So the researchers used an automated neural architecture search to jointly optimize both the network and the inference scheduling. This led to their MCUNetV2 model, which set new records for accuracy on MCUs while keeping memory usage extremely low.
Technical Explanation
The key technical insight is that the memory bottleneck in CNN models running on MCUs is caused by an imbalanced distribution of memory usage across the network layers. The initial convolutional blocks require significantly more memory than the later blocks.
To address this, the researchers proposed a "patch-by-patch" inference scheduling approach. This divides the input image into smaller spatial regions or "patches", and processes each patch independently. This dramatically reduces the peak memory usage compared to processing the entire image at once.
However, the naive patch-based approach introduces some challenges, like overlapping computations between neighboring patches. To mitigate this, the researchers further proposed "network redistribution" - shifting more of the receptive field and computation to the later layers of the network. This reduced the overhead of the patch-based inference.
Manually redesigning the network architecture and inference scheduling is extremely difficult. The researchers automated this process using neural architecture search (NAS). They jointly optimized the neural network structure and the inference scheduling, leading to their MCUNetV2 model.
Critical Analysis
The researchers have made significant progress in addressing the memory bottleneck that has limited the deployment of deep learning on microcontrollers. Their patch-based inference scheduling and network redistribution techniques are clever solutions that effectively reduce peak memory usage without sacrificing too much accuracy.
However, the paper does not discuss some potential limitations or tradeoffs. For example, the patch-based inference may introduce some accuracy degradation compared to processing the full image at once. The automated NAS process, while powerful, could also lead to models that are more complex or computationally intensive than necessary for the target MCU hardware.
Additionally, the experiments were mostly focused on image classification tasks. It's unclear how well these techniques would generalize to other vision tasks like object detection or segmentation, which have different memory and computational requirements.
Further research could explore the memory and latency tradeoffs of the patch-based inference in more detail, and investigate ways to make the NAS process even more efficient and hardware-aware. Validating the techniques on a broader set of vision tasks and hardware platforms would also help demonstrate their broader applicability.
Overall, this work represents an important step forward in enabling powerful deep learning capabilities on resource-constrained microcontrollers. The innovations described open up exciting possibilities for deploying advanced AI in a wide range of embedded devices and Internet of Things applications.
Conclusion
This research tackles a critical challenge in the field of "tiny machine learning" - how to run state-of-the-art deep learning models on microcontrollers with severely limited memory. By identifying the root cause of the memory bottleneck in CNN architectures, the researchers developed novel techniques to dramatically reduce peak memory usage without sacrificing too much accuracy.
Their patch-based inference scheduling and network redistribution approaches, coupled with automated neural architecture search, enabled them to set new records for ImageNet accuracy and visual wake word recognition on MCUs. This unlocks the potential for advanced AI capabilities in a wide range of embedded devices, from smart home gadgets to industrial sensors.
While there are still some open questions and areas for further research, this work represents a major advancement in the field of tiny deep learning. It lays the groundwork for future innovations that could bring powerful AI to the very edges of the computing landscape.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤯
0
MCUNetV2: Memory-Efficient Patch-based Inference for Tiny Deep Learning
Ji Lin, Wei-Ming Chen, Han Cai, Chuang Gan, Song Han
Tiny deep learning on microcontroller units (MCUs) is challenging due to the limited memory size. We find that the memory bottleneck is due to the imbalanced memory distribution in convolutional neural network (CNN) designs: the first several blocks have an order of magnitude larger memory usage than the rest of the network. To alleviate this issue, we propose a generic patch-by-patch inference scheduling, which operates only on a small spatial region of the feature map and significantly cuts down the peak memory. However, naive implementation brings overlapping patches and computation overhead. We further propose network redistribution to shift the receptive field and FLOPs to the later stage and reduce the computation overhead. Manually redistributing the receptive field is difficult. We automate the process with neural architecture search to jointly optimize the neural architecture and inference scheduling, leading to MCUNetV2. Patch-based inference effectively reduces the peak memory usage of existing networks by 4-8x. Co-designed with neural networks, MCUNetV2 sets a record ImageNet accuracy on MCU (71.8%), and achieves >90% accuracy on the visual wake words dataset under only 32kB SRAM. MCUNetV2 also unblocks object detection on tiny devices, achieving 16.9% higher mAP on Pascal VOC compared to the state-of-the-art result. Our study largely addressed the memory bottleneck in tinyML and paved the way for various vision applications beyond image classification.
Read more4/4/2024

0
Designing Extremely Memory-Efficient CNNs for On-device Vision Tasks
Jaewook Lee, Yoel Park, Seulki Lee
In this paper, we introduce a memory-efficient CNN (convolutional neural network), which enables resource-constrained low-end embedded and IoT devices to perform on-device vision tasks, such as image classification and object detection, using extremely low memory, i.e., only 63 KB on ImageNet classification. Based on the bottleneck block of MobileNet, we propose three design principles that significantly curtail the peak memory usage of a CNN so that it can fit the limited KB memory of the low-end device. First, 'input segmentation' divides an input image into a set of patches, including the central patch overlapped with the others, reducing the size (and memory requirement) of a large input image. Second, 'patch tunneling' builds independent tunnel-like paths consisting of multiple bottleneck blocks per patch, penetrating through the entire model from an input patch to the last layer of the network, maintaining lightweight memory usage throughout the whole network. Lastly, 'bottleneck reordering' rearranges the execution order of convolution operations inside the bottleneck block such that the memory usage remains constant regardless of the size of the convolution output channels. The experiment result shows that the proposed network classifies ImageNet with extremely low memory (i.e., 63 KB) while achieving competitive top-1 accuracy (i.e., 61.58%). To the best of our knowledge, the memory usage of the proposed network is far smaller than state-of-the-art memory-efficient networks, i.e., up to 89x and 3.1x smaller than MobileNet (i.e., 5.6 MB) and MCUNet (i.e., 196 KB), respectively.
Read more8/9/2024

0
vMCU: Coordinated Memory Management and Kernel Optimization for DNN Inference on MCUs
Size Zheng, Renze Chen, Meng Li, Zihao Ye, Luis Ceze, Yun Liang
IoT devices based on microcontroller units (MCU) provide ultra-low power consumption and ubiquitous computation for near-sensor deep learning models (DNN). However, the memory of MCU is usually 2-3 orders of magnitude smaller than mobile devices, which makes it challenging to map DNNs onto MCUs. Previous work separates memory management and kernel implementation for MCU and relies on coarse-grained memory management techniques such as inplace update to reduce memory consumption. In this paper, we propose to coordinate memory management and kernel optimization for DNN inference on MCUs to enable fine-grained memory management. The key idea is to virtualize the limited memory of MCU as a large memory pool. Each kernel divides the memory pool into kernel-specific segments and handles segment load and store while computing DNN layers. Memory consumption can be reduced because using the fine-grained segment-level memory control, we can overlap the memory footprint of different tensors without the need to materialize them at the same time. Following this idea, we implement ours{} for DNN inference on MCU. Evaluation for single layers on ARM Cortex-M4 and Cortex-M7 processors shows that ours{} can reduce from $12.0%$ to $49.5%$ RAM usage and from $20.6%$ to $53.0%$ energy consumption compared to state-of-the-art work. For full DNN evaluation, ours{} can reduce the memory bottleneck by $61.5%$, enabling more models to be deployed on low-end MCUs.
Read more6/12/2024
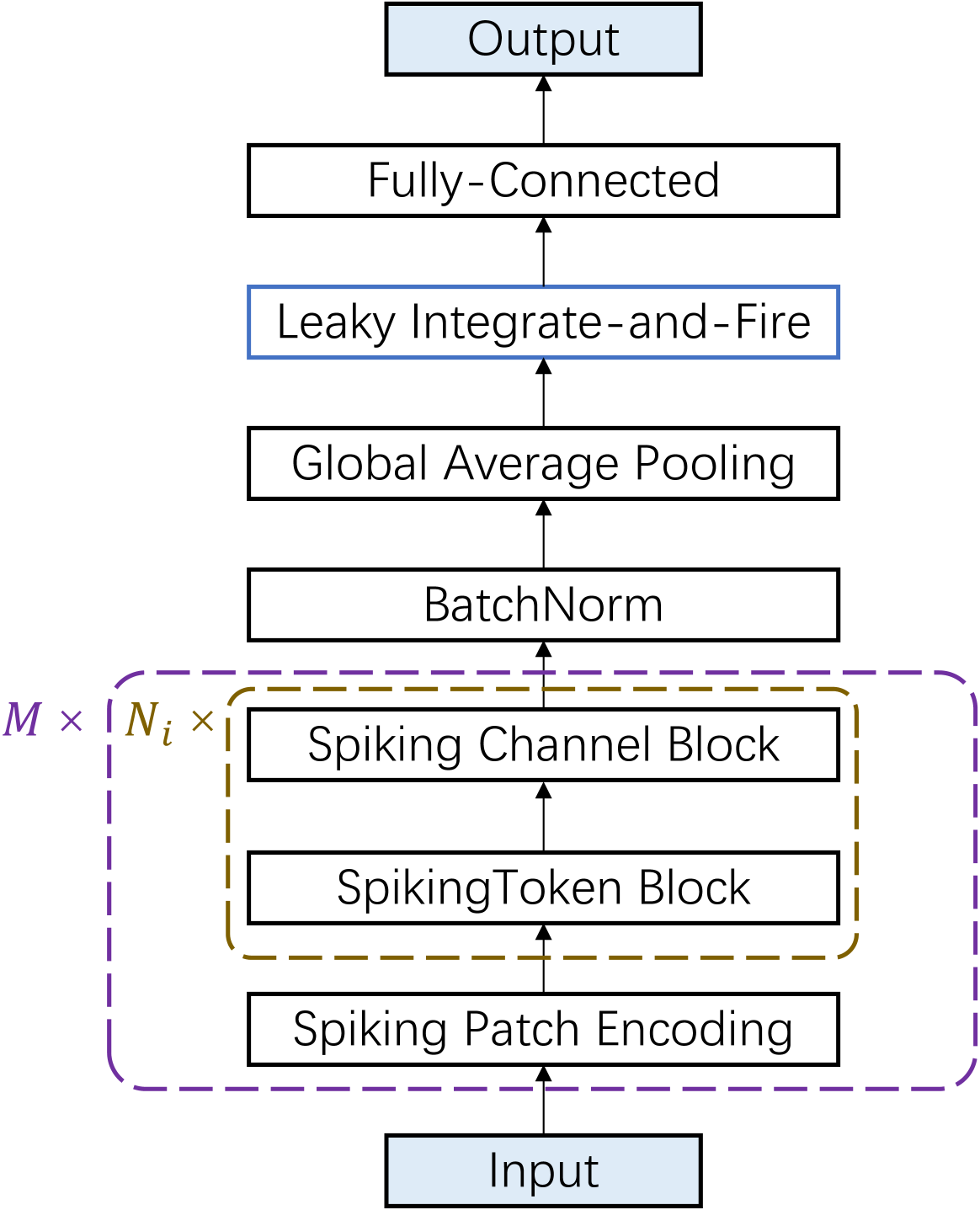
0
Efficient Deep Spiking Multi-Layer Perceptrons with Multiplication-Free Inference
Boyan Li, Luziwei Leng, Shuaijie Shen, Kaixuan Zhang, Jianguo Zhang, Jianxing Liao, Ran Cheng
Advancements in adapting deep convolution architectures for Spiking Neural Networks (SNNs) have significantly enhanced image classification performance and reduced computational burdens. However, the inability of Multiplication-Free Inference (MFI) to align with attention and transformer mechanisms, which are critical to superior performance on high-resolution vision tasks, imposing limitations on these gains. To address this, our research explores a new pathway, drawing inspiration from the progress made in Multi-Layer Perceptrons (MLPs). We propose an innovative spiking MLP architecture that uses batch normalization to retain MFI compatibility and introducing a spiking patch encoding layer to enhance local feature extraction capabilities. As a result, we establish an efficient multi-stage spiking MLP network that blends effectively global receptive fields with local feature extraction for comprehensive spike-based computation. Without relying on pre-training or sophisticated SNN training techniques, our network secures a top-1 accuracy of 66.39% on the ImageNet-1K dataset, surpassing the directly trained spiking ResNet-34 by 2.67%. Furthermore, we curtail computational costs, model parameters, and simulation steps. An expanded version of our network compares with the performance of the spiking VGG-16 network with a 71.64% top-1 accuracy, all while operating with a model capacity 2.1 times smaller. Our findings highlight the potential of our deep SNN architecture in effectively integrating global and local learning abilities. Interestingly, the trained receptive field in our network mirrors the activity patterns of cortical cells. Source codes are publicly accessible at https://github.com/EMI-Group/mixer-snn.
Read more4/29/2024