On Measuring Faithfulness or Self-consistency of Natural Language Explanations
2311.07466
0
0
🌿
Abstract
Large language models (LLMs) can explain their predictions through post-hoc or Chain-of-Thought (CoT) explanations. But an LLM could make up reasonably sounding explanations that are unfaithful to its underlying reasoning. Recent work has designed tests that aim to judge the faithfulness of post-hoc or CoT explanations. In this work we argue that these faithfulness tests do not measure faithfulness to the models' inner workings -- but rather their self-consistency at output level. Our contributions are three-fold: i) We clarify the status of faithfulness tests in view of model explainability, characterising them as self-consistency tests instead. This assessment we underline by ii) constructing a Comparative Consistency Bank for self-consistency tests that for the first time compares existing tests on a common suite of 11 open LLMs and 5 tasks -- including iii) our new self-consistency measure CC-SHAP. CC-SHAP is a fine-grained measure (not a test) of LLM self-consistency. It compares how a model's input contributes to the predicted answer and to generating the explanation. Our fine-grained CC-SHAP metric allows us iii) to compare LLM behaviour when making predictions and to analyse the effect of other consistency tests at a deeper level, which takes us one step further towards measuring faithfulness by bringing us closer to the internals of the model than strictly surface output-oriented tests. Our code is available at url{https://github.com/Heidelberg-NLP/CC-SHAP}
Create account to get full access
Overview
- Large language models (LLMs) can provide post-hoc or Chain-of-Thought (CoT) explanations for their predictions, but these explanations may not always be faithful to the model's underlying reasoning.
- Recent work has designed tests to judge the faithfulness of these explanations, but this paper argues that these tests actually measure the self-consistency of the model's outputs, rather than faithfulness to its inner workings.
- The paper makes three key contributions:
- Clarifying that the existing faithfulness tests are actually self-consistency tests
- Constructing a Comparative Consistency Bank to compare these self-consistency tests across 11 LLMs and 5 tasks
- Introducing a new self-consistency measure called CC-SHAP that examines how a model's inputs contribute to both its predictions and explanations
Plain English Explanation
Large language models (LLMs) like GPT-3 and InstructGPT can try to explain their predictions by providing post-hoc or Chain-of-Thought (CoT) explanations. However, these explanations may not always accurately reflect the model's true reasoning process.
Researchers have developed tests to evaluate how faithful these explanations are to the model's inner workings. But this paper argues that these "faithfulness tests" are actually just measuring how consistent the model's outputs are with each other, rather than how faithful they are to the model's actual decision-making process.
The paper makes three key contributions:
-
Clarifying the nature of faithfulness tests: The authors explain that the existing faithfulness tests are really just tests of the model's self-consistency, not its faithfulness to its internal logic.
-
Comparative Consistency Bank: The authors create a set of 11 different LLMs and 5 different tasks, and use a variety of self-consistency tests to compare the models' behaviors.
-
CC-SHAP: The authors introduce a new self-consistency measure called CC-SHAP. This metric looks at how the model's inputs contribute to both its final predictions and the explanations it provides. This gives a more fine-grained view of the model's self-consistency than the existing faithfulness tests.
By taking this more nuanced look at model consistency, the authors hope to bring us closer to truly understanding the faithfulness of LLM explanations and how they relate to the models' internal decision-making processes.
Technical Explanation
The paper addresses the challenge of evaluating the faithfulness of post-hoc or Chain-of-Thought (CoT) explanations provided by large language models (LLMs). Recent work has developed tests that aim to judge the faithfulness of these explanations, but the authors argue that these tests actually measure the self-consistency of the model's outputs, rather than their faithfulness to the model's inner workings.
The paper makes three key contributions:
-
Clarifying the status of faithfulness tests: The authors characterize the existing faithfulness tests as measures of self-consistency, rather than true faithfulness. They argue that these tests examine how well the model's outputs (predictions and explanations) align with each other, but do not necessarily reflect the model's actual reasoning process.
-
Comparative Consistency Bank: To further explore this issue, the authors construct a Comparative Consistency Bank that compares the behavior of 11 different LLMs across 5 different tasks. They use a variety of self-consistency tests to evaluate the models' outputs.
-
CC-SHAP: The authors introduce a new self-consistency measure called CC-SHAP (Comparative Consistency SHAP). This metric looks at how the model's inputs contribute to both its final predictions and the explanations it provides. By examining this fine-grained relationship between inputs, predictions, and explanations, CC-SHAP aims to bring us closer to understanding the faithfulness of LLM explanations.
The authors' key insight is that the existing faithfulness tests do not actually measure faithfulness to the model's internal reasoning, but rather its self-consistency at the output level. The introduction of CC-SHAP represents a step towards a more nuanced understanding of LLM explanations and their relationship to the models' underlying decision-making processes.
Critical Analysis
The authors make a compelling case that the existing "faithfulness tests" for LLM explanations are actually measures of self-consistency, rather than true faithfulness to the models' internal workings. This is an important distinction, as it highlights the limitations of these tests and the need for more sophisticated approaches to evaluating explanation faithfulness.
The authors' construction of the Comparative Consistency Bank and the introduction of the CC-SHAP metric are valuable contributions that can help advance the field. By providing a common framework for evaluating LLM self-consistency across a range of models and tasks, the Bank allows for more systematic comparisons. And the CC-SHAP metric's focus on the relationship between inputs, predictions, and explanations is a step towards a more fine-grained understanding of LLM behavior.
That said, the paper does not address some potential limitations and areas for further research. For example, it's unclear how well the CC-SHAP metric captures the full complexity of LLM explanations, or how it might be affected by factors like task difficulty or model architecture. Additionally, the paper does not explore potential ways to directly measure faithfulness to the models' internal reasoning, which remains an important challenge.
Overall, this paper makes a significant contribution by clarifying the limitations of existing faithfulness tests and proposing new approaches for evaluating LLM explanations. By encouraging a more critical and nuanced understanding of these models, the authors help pave the way for more robust and reliable explanation methods in the future.
Conclusion
This paper challenges the current understanding of faithfulness tests for large language model (LLM) explanations, arguing that these tests actually measure the self-consistency of the model's outputs rather than their faithfulness to the underlying reasoning process.
The authors make three key contributions to address this issue:
- Clarifying the status of faithfulness tests: They characterize existing tests as measures of self-consistency, not true faithfulness.
- Comparative Consistency Bank: They create a framework to compare the self-consistency of 11 LLMs across 5 tasks.
- CC-SHAP: They introduce a new fine-grained self-consistency metric that examines the relationship between model inputs, predictions, and explanations.
By taking this more nuanced approach, the authors bring us closer to understanding the true faithfulness of LLM explanations and their connection to the models' internal decision-making. This work represents an important step forward in evaluating and improving the transparency and reliability of these powerful language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Are self-explanations from Large Language Models faithful?
Andreas Madsen, Sarath Chandar, Siva Reddy
0
0
Instruction-tuned Large Language Models (LLMs) excel at many tasks and will even explain their reasoning, so-called self-explanations. However, convincing and wrong self-explanations can lead to unsupported confidence in LLMs, thus increasing risk. Therefore, it's important to measure if self-explanations truly reflect the model's behavior. Such a measure is called interpretability-faithfulness and is challenging to perform since the ground truth is inaccessible, and many LLMs only have an inference API. To address this, we propose employing self-consistency checks to measure faithfulness. For example, if an LLM says a set of words is important for making a prediction, then it should not be able to make its prediction without these words. While self-consistency checks are a common approach to faithfulness, they have not previously been successfully applied to LLM self-explanations for counterfactual, feature attribution, and redaction explanations. Our results demonstrate that faithfulness is explanation, model, and task-dependent, showing self-explanations should not be trusted in general. For example, with sentiment classification, counterfactuals are more faithful for Llama2, feature attribution for Mistral, and redaction for Falcon 40B.
5/20/2024

Chain-of-Thought Unfaithfulness as Disguised Accuracy
Oliver Bentham, Nathan Stringham, Ana Marasovi'c
0
0
Understanding the extent to which Chain-of-Thought (CoT) generations align with a large language model's (LLM) internal computations is critical for deciding whether to trust an LLM's output. As a proxy for CoT faithfulness, Lanham et al. (2023) propose a metric that measures a model's dependence on its CoT for producing an answer. Within a single family of proprietary models, they find that LLMs exhibit a scaling-then-inverse-scaling relationship between model size and their measure of faithfulness, and that a 13 billion parameter model exhibits increased faithfulness compared to models ranging from 810 million to 175 billion parameters in size. We evaluate whether these results generalize as a property of all LLMs. We replicate the experimental setup in their section focused on scaling experiments with three different families of models and, under specific conditions, successfully reproduce the scaling trends for CoT faithfulness they report. However, after normalizing the metric to account for a model's bias toward certain answer choices, unfaithfulness drops significantly for smaller less-capable models. This normalized faithfulness metric is also strongly correlated ($R^2$=0.74) with accuracy, raising doubts about its validity for evaluating faithfulness.
6/24/2024
💬
FaithLM: Towards Faithful Explanations for Large Language Models
Yu-Neng Chuang, Guanchu Wang, Chia-Yuan Chang, Ruixiang Tang, Shaochen Zhong, Fan Yang, Mengnan Du, Xuanting Cai, Xia Hu
0
0
Large Language Models (LLMs) have become proficient in addressing complex tasks by leveraging their extensive internal knowledge and reasoning capabilities. However, the black-box nature of these models complicates the task of explaining their decision-making processes. While recent advancements demonstrate the potential of leveraging LLMs to self-explain their predictions through natural language (NL) explanations, their explanations may not accurately reflect the LLMs' decision-making process due to a lack of fidelity optimization on the derived explanations. Measuring the fidelity of NL explanations is a challenging issue, as it is difficult to manipulate the input context to mask the semantics of these explanations. To this end, we introduce FaithLM to explain the decision of LLMs with NL explanations. Specifically, FaithLM designs a method for evaluating the fidelity of NL explanations by incorporating the contrary explanations to the query process. Moreover, FaithLM conducts an iterative process to improve the fidelity of derived explanations. Experiment results on three datasets from multiple domains demonstrate that FaithLM can significantly improve the fidelity of derived explanations, which also provides a better alignment with the ground-truth explanations.
6/27/2024
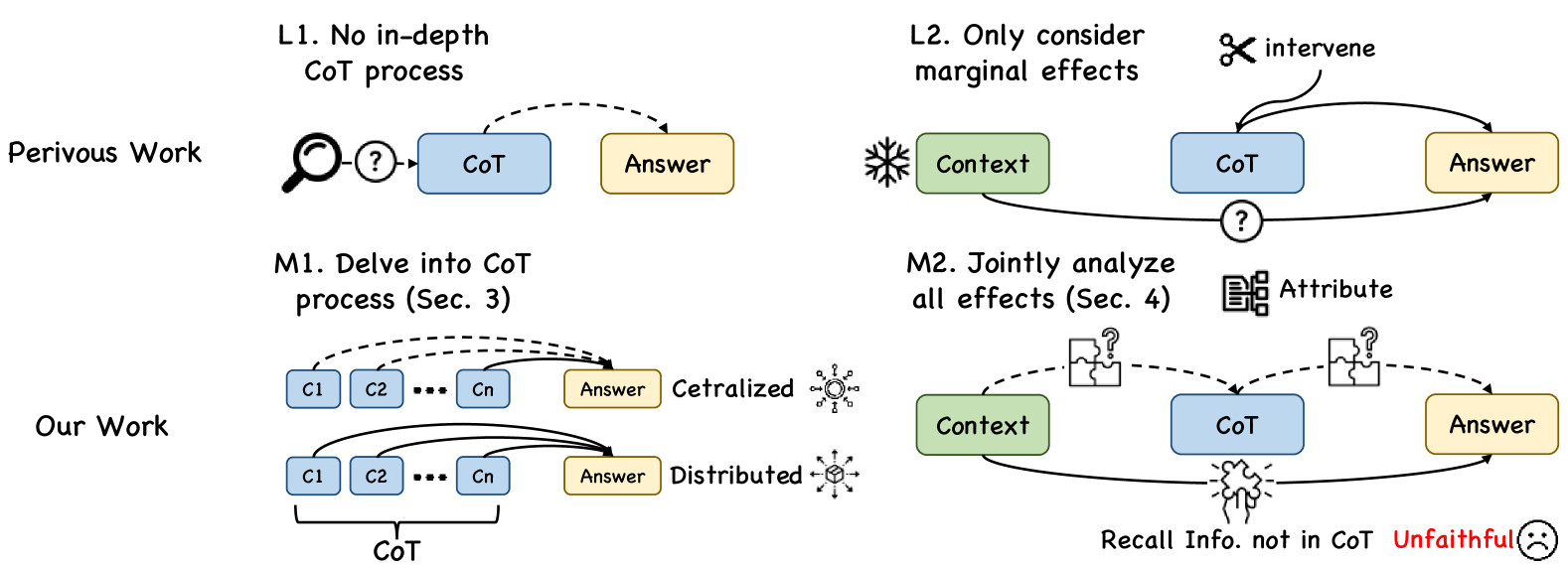
Towards Faithful Chain-of-Thought: Large Language Models are Bridging Reasoners
Jiachun Li, Pengfei Cao, Yubo Chen, Kang Liu, Jun Zhao
0
0
Large language models (LLMs) suffer from serious unfaithful chain-of-thought (CoT) issues. Previous work attempts to measure and explain it but lacks in-depth analysis within CoTs and does not consider the interactions among all reasoning components jointly. In this paper, we first study the CoT faithfulness issue at the granularity of CoT steps, identify two reasoning paradigms: centralized reasoning and distributed reasoning, and find their relationship with faithfulness. Subsequently, we conduct a joint analysis of the causal relevance among the context, CoT, and answer during reasoning. The result proves that, when the LLM predicts answers, it can recall correct information missing in the CoT from the context, leading to unfaithfulness issues. Finally, we propose the inferential bridging method to mitigate this issue, in which we use the attribution method to recall information as hints for CoT generation and filter out noisy CoTs based on their semantic consistency and attribution scores. Extensive experiments demonstrate that our approach effectively alleviates the unfaithful CoT problem.
5/30/2024