FaithLM: Towards Faithful Explanations for Large Language Models
2402.04678
0
0
💬
Abstract
Large Language Models (LLMs) have become proficient in addressing complex tasks by leveraging their extensive internal knowledge and reasoning capabilities. However, the black-box nature of these models complicates the task of explaining their decision-making processes. While recent advancements demonstrate the potential of leveraging LLMs to self-explain their predictions through natural language (NL) explanations, their explanations may not accurately reflect the LLMs' decision-making process due to a lack of fidelity optimization on the derived explanations. Measuring the fidelity of NL explanations is a challenging issue, as it is difficult to manipulate the input context to mask the semantics of these explanations. To this end, we introduce FaithLM to explain the decision of LLMs with NL explanations. Specifically, FaithLM designs a method for evaluating the fidelity of NL explanations by incorporating the contrary explanations to the query process. Moreover, FaithLM conducts an iterative process to improve the fidelity of derived explanations. Experiment results on three datasets from multiple domains demonstrate that FaithLM can significantly improve the fidelity of derived explanations, which also provides a better alignment with the ground-truth explanations.
Create account to get full access
Overview
- Large language models (LLMs) have become adept at tackling complex tasks by leveraging their extensive knowledge and reasoning capabilities.
- However, the inner workings of these models are not easily explainable, making it difficult to understand their decision-making processes.
- Recent advancements show the potential of using LLMs to self-explain their predictions through natural language explanations.
- But these explanations may not accurately reflect the models' true decision-making process due to a lack of optimization for explanation fidelity.
- Measuring the fidelity of natural language explanations is challenging, as it is hard to manipulate the input context to mask the semantics of these explanations.
- To address this, the researchers introduce FaithLM, a method for evaluating and improving the fidelity of natural language explanations provided by LLMs.
Plain English Explanation
Large language models have become extremely capable at handling complex tasks, drawing on their vast internal knowledge and powerful reasoning abilities. However, these models operate like "black boxes" – it's not easy to understand the specific thought processes they use to arrive at their decisions.
Recent research has shown that these models can actually generate natural language explanations to describe their own predictions. This is an exciting development, as it could help make the models' decision-making more transparent. But there's a catch: the explanations may not truly reflect how the model is actually thinking.
Imagine you ask an LLM to explain why it made a certain prediction. The model might give you a reasonable-sounding explanation, but that explanation could be disconnected from the model's actual reasoning. This is a problem, because we want the explanations to be faithful to the model's internal decision-making.
Measuring the faithfulness, or fidelity, of these natural language explanations is challenging. It's hard to manipulate the input in a way that would let us see if the explanation is truly aligned with the model's thought process.
The researchers behind FaithLM have developed a new approach to address this challenge. Their method, FaithLM, evaluates the fidelity of natural language explanations by incorporating "contrary" explanations into the query process. Through an iterative process, FaithLM can then improve the fidelity of the explanations generated by the LLM.
Technical Explanation
The paper introduces FaithLM, a method for evaluating and enhancing the fidelity of natural language (NL) explanations generated by large language models (LLMs).
The key innovation of FaithLM is its approach to measuring explanation fidelity. Rather than relying on direct manipulations of the input context, which can be challenging, FaithLM incorporates "contrary" explanations into the query process. These contrary explanations are designed to be semantically distinct from the ground-truth explanation, allowing FaithLM to better assess whether the LLM's generated explanation truly aligns with its internal decision-making.
FaithLM then uses an iterative process to improve the fidelity of the derived explanations. By optimizing the fidelity of the explanations, the researchers aim to better capture the LLM's actual decision-making process, rather than just plausible-sounding rationalizations.
Experiments on three diverse datasets demonstrate that FaithLM can significantly improve the fidelity of the natural language explanations generated by LLMs, bringing them into closer alignment with ground-truth explanations. This suggests that FaithLM could be a valuable tool for enhancing the transparency and interpretability of LLM decision-making.
Critical Analysis
The research presented in this paper addresses an important challenge in the field of explainable AI: how to ensure that the natural language explanations provided by large language models faithfully reflect their underlying decision-making processes.
One key strength of the FaithLM approach is its innovative use of "contrary" explanations to assess explanation fidelity. This method avoids the pitfalls of directly manipulating input context, which can be technically challenging and may not fully capture the semantics of the explanations.
However, the paper does acknowledge some limitations of the FaithLM approach. For example, the researchers note that the iterative optimization process used to improve explanation fidelity may not always converge to the globally optimal solution. Additionally, the method assumes that the ground-truth explanations used for evaluation are themselves accurate representations of the LLM's decision-making, which may not always be the case.
Further research could explore ways to address these limitations, such as investigating alternative optimization techniques or developing methods to validate the accuracy of ground-truth explanations. Expanding the evaluation to include a wider range of datasets and model architectures would also help to further assess the generalizability of the FaithLM approach.
Conclusion
This paper presents an important step forward in the quest to make large language models more transparent and interpretable. By introducing FaithLM, a method for evaluating and improving the fidelity of natural language explanations, the researchers have developed a valuable tool for enhancing the alignment between LLM decision-making and the explanations they provide.
As LLMs continue to become more influential in a wide range of applications, the ability to understand and trust their decision-making processes will become increasingly crucial. The insights and techniques developed in this paper could help pave the way for more trustworthy and accountable AI systems that can better explain their reasoning to human users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Are self-explanations from Large Language Models faithful?
Andreas Madsen, Sarath Chandar, Siva Reddy
0
0
Instruction-tuned Large Language Models (LLMs) excel at many tasks and will even explain their reasoning, so-called self-explanations. However, convincing and wrong self-explanations can lead to unsupported confidence in LLMs, thus increasing risk. Therefore, it's important to measure if self-explanations truly reflect the model's behavior. Such a measure is called interpretability-faithfulness and is challenging to perform since the ground truth is inaccessible, and many LLMs only have an inference API. To address this, we propose employing self-consistency checks to measure faithfulness. For example, if an LLM says a set of words is important for making a prediction, then it should not be able to make its prediction without these words. While self-consistency checks are a common approach to faithfulness, they have not previously been successfully applied to LLM self-explanations for counterfactual, feature attribution, and redaction explanations. Our results demonstrate that faithfulness is explanation, model, and task-dependent, showing self-explanations should not be trusted in general. For example, with sentiment classification, counterfactuals are more faithful for Llama2, feature attribution for Mistral, and redaction for Falcon 40B.
5/20/2024
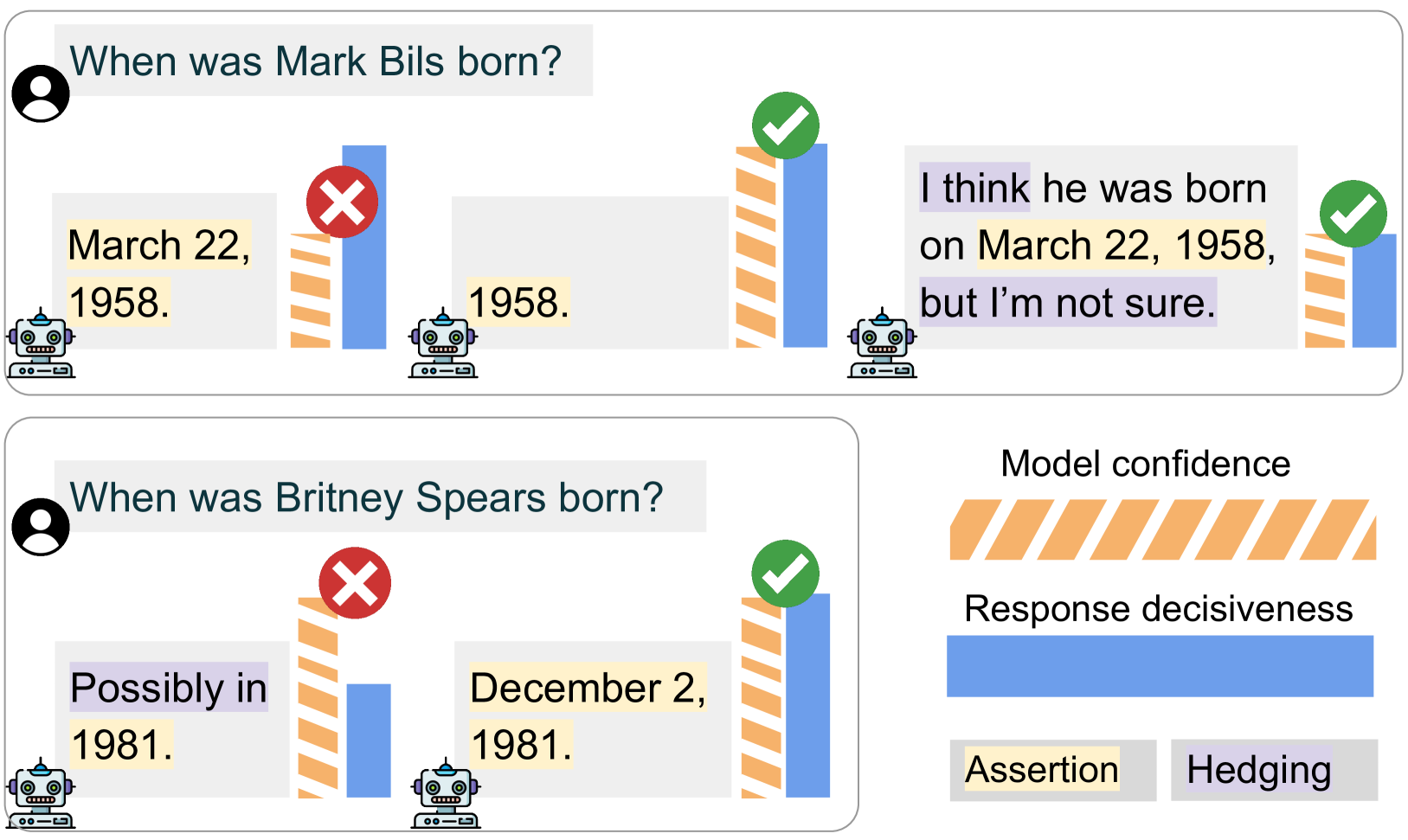
Can Large Language Models Faithfully Express Their Intrinsic Uncertainty in Words?
Gal Yona, Roee Aharoni, Mor Geva
0
0
We posit that large language models (LLMs) should be capable of expressing their intrinsic uncertainty in natural language. For example, if the LLM is equally likely to output two contradicting answers to the same question, then its generated response should reflect this uncertainty by hedging its answer (e.g., I'm not sure, but I think...). We formalize faithful response uncertainty based on the gap between the model's intrinsic confidence in the assertions it makes and the decisiveness by which they are conveyed. This example-level metric reliably indicates whether the model reflects its uncertainty, as it penalizes both excessive and insufficient hedging. We evaluate a variety of aligned LLMs at faithfully communicating uncertainty on several knowledge-intensive question answering tasks. Our results provide strong evidence that modern LLMs are poor at faithfully conveying their uncertainty, and that better alignment is necessary to improve their trustworthiness.
5/28/2024
Evaluating Readability and Faithfulness of Concept-based Explanations
Meng Li, Haoran Jin, Ruixuan Huang, Zhihao Xu, Defu Lian, Zijia Lin, Di Zhang, Xiting Wang
0
0
Despite the surprisingly high intelligence exhibited by Large Language Models (LLMs), we are somehow intimidated to fully deploy them into real-life applications considering their black-box nature. Concept-based explanations arise as a promising avenue for explaining what the LLMs have learned, making them more transparent to humans. However, current evaluations for concepts tend to be heuristic and non-deterministic, e.g. case study or human evaluation, hindering the development of the field. To bridge the gap, we approach concept-based explanation evaluation via faithfulness and readability. We first introduce a formal definition of concept generalizable to diverse concept-based explanations. Based on this, we quantify faithfulness via the difference in the output upon perturbation. We then provide an automatic measure for readability, by measuring the coherence of patterns that maximally activate a concept. This measure serves as a cost-effective and reliable substitute for human evaluation. Finally, based on measurement theory, we describe a meta-evaluation method for evaluating the above measures via reliability and validity, which can be generalized to other tasks as well. Extensive experimental analysis has been conducted to validate and inform the selection of concept evaluation measures.
5/1/2024
💬
Large Language Models Help Humans Verify Truthfulness -- Except When They Are Convincingly Wrong
Chenglei Si, Navita Goyal, Sherry Tongshuang Wu, Chen Zhao, Shi Feng, Hal Daum'e III, Jordan Boyd-Graber
0
0
Large Language Models (LLMs) are increasingly used for accessing information on the web. Their truthfulness and factuality are thus of great interest. To help users make the right decisions about the information they get, LLMs should not only provide information but also help users fact-check it. Our experiments with 80 crowdworkers compare language models with search engines (information retrieval systems) at facilitating fact-checking. We prompt LLMs to validate a given claim and provide corresponding explanations. Users reading LLM explanations are significantly more efficient than those using search engines while achieving similar accuracy. However, they over-rely on the LLMs when the explanation is wrong. To reduce over-reliance on LLMs, we ask LLMs to provide contrastive information - explain both why the claim is true and false, and then we present both sides of the explanation to users. This contrastive explanation mitigates users' over-reliance on LLMs, but cannot significantly outperform search engines. Further, showing both search engine results and LLM explanations offers no complementary benefits compared to search engines alone. Taken together, our study highlights that natural language explanations by LLMs may not be a reliable replacement for reading the retrieved passages, especially in high-stakes settings where over-relying on wrong AI explanations could lead to critical consequences.
4/3/2024