MedCalc-Bench: Evaluating Large Language Models for Medical Calculations
2406.12036
0
0
Abstract
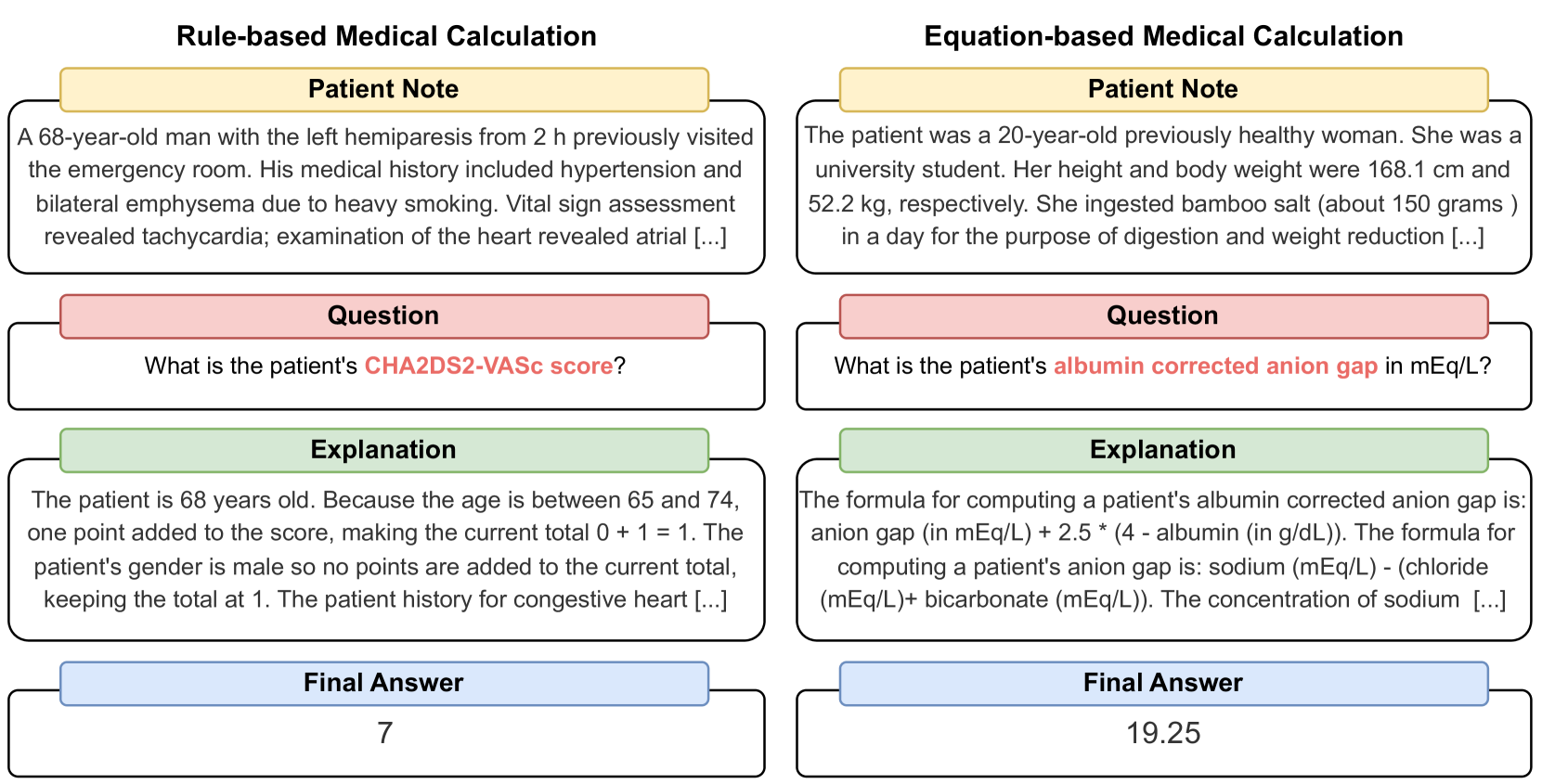
As opposed to evaluating computation and logic-based reasoning, current benchmarks for evaluating large language models (LLMs) in medicine are primarily focused on question-answering involving domain knowledge and descriptive reasoning. While such qualitative capabilities are vital to medical diagnosis, in real-world scenarios, doctors frequently use clinical calculators that follow quantitative equations and rule-based reasoning paradigms for evidence-based decision support. To this end, we propose MedCalc-Bench, a first-of-its-kind dataset focused on evaluating the medical calculation capability of LLMs. MedCalc-Bench contains an evaluation set of over 1000 manually reviewed instances from 55 different medical calculation tasks. Each instance in MedCalc-Bench consists of a patient note, a question requesting to compute a specific medical value, a ground truth answer, and a step-by-step explanation showing how the answer is obtained. While our evaluation results show the potential of LLMs in this area, none of them are effective enough for clinical settings. Common issues include extracting the incorrect entities, not using the correct equation or rules for a calculation task, or incorrectly performing the arithmetic for the computation. We hope our study highlights the quantitative knowledge and reasoning gaps in LLMs within medical settings, encouraging future improvements of LLMs for various clinical calculation tasks.
Create account to get full access
Overview
- This paper introduces MedCalc-Bench, a benchmark for evaluating the performance of large language models (LLMs) on medical calculation tasks.
- The authors aim to assess the ability of LLMs to perform accurate medical calculations, which is crucial for their deployment in healthcare applications.
- The benchmark includes a diverse set of medical calculation problems spanning different medical domains and task complexities.
Plain English Explanation
The researchers have created a new benchmark called MedCalc-Bench to test how well large language models (LLMs) can perform medical calculations. LLMs are AI systems that can understand and generate human-like text, and they are being explored for use in healthcare applications. However, it's important to ensure these models can accurately handle the numerical calculations that are essential for many medical tasks, such as dosage calculations or risk assessments.
MedCalc-Bench provides a comprehensive set of medical calculation problems that LLMs can be tested on. This allows researchers to evaluate the models' capabilities in this critical area and identify any limitations or areas for improvement. By developing this benchmark, the authors aim to help advance the use of LLMs in real-world healthcare settings, where accurate calculations are crucial for patient safety and effective treatment.
Technical Explanation
The paper introduces the MedCalc-Bench benchmark, which is designed to evaluate the performance of large language models (LLMs) on a diverse set of medical calculation tasks. The benchmark includes problems spanning various medical domains, such as pharmacology, radiology, and epidemiology, and with varying levels of complexity.
The authors curated a dataset of over 2,000 medical calculation problems from existing resources, such as medical textbooks and online reference materials. The problems cover a wide range of medical calculations, including dosage calculations, body mass index (BMI) calculations, and risk assessment formulae.
To establish a baseline, the authors evaluated the performance of several state-of-the-art LLMs, including GPT-3, PaLM, and Chinook, on the MedCalc-Bench dataset. The results show that while these models perform well on certain types of medical calculations, they struggle with more complex or domain-specific problems, highlighting the need for further research and development in this area.
Critical Analysis
The authors acknowledge that the MedCalc-Bench benchmark has some limitations. The dataset may not capture the full breadth and complexity of medical calculations encountered in real-world clinical practice, and the benchmark does not evaluate the models' ability to handle uncertainty or interact with human clinicians.
Additionally, the paper does not provide a detailed analysis of the specific strengths and weaknesses of the evaluated LLMs, which could have offered more insights into the current state of the technology and areas for improvement.
Further research is needed to understand the factors that contribute to the models' performance, such as the impact of task complexity, medical domain knowledge, and the integration of numerical reasoning capabilities. Expanding the benchmark to include a wider range of medical calculation tasks and testing the models' ability to handle real-world clinical data would also be valuable.
Conclusion
The MedCalc-Bench benchmark represents an important step towards evaluating the suitability of large language models for medical applications, particularly in the realm of medical calculations. By providing a standardized dataset and evaluation framework, the authors have laid the groundwork for further research and development in this critical area.
As LLMs continue to advance, the insights gained from MedCalc-Bench can help guide the integration of these models into healthcare systems, ensuring that they can reliably and accurately perform the numerical tasks necessary for effective patient care.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
CliBench: Multifaceted Evaluation of Large Language Models in Clinical Decisions on Diagnoses, Procedures, Lab Tests Orders and Prescriptions
Mingyu Derek Ma, Chenchen Ye, Yu Yan, Xiaoxuan Wang, Peipei Ping, Timothy S Chang, Wei Wang
0
0
The integration of Artificial Intelligence (AI), especially Large Language Models (LLMs), into the clinical diagnosis process offers significant potential to improve the efficiency and accessibility of medical care. While LLMs have shown some promise in the medical domain, their application in clinical diagnosis remains underexplored, especially in real-world clinical practice, where highly sophisticated, patient-specific decisions need to be made. Current evaluations of LLMs in this field are often narrow in scope, focusing on specific diseases or specialties and employing simplified diagnostic tasks. To bridge this gap, we introduce CliBench, a novel benchmark developed from the MIMIC IV dataset, offering a comprehensive and realistic assessment of LLMs' capabilities in clinical diagnosis. This benchmark not only covers diagnoses from a diverse range of medical cases across various specialties but also incorporates tasks of clinical significance: treatment procedure identification, lab test ordering and medication prescriptions. Supported by structured output ontologies, CliBench enables a precise and multi-granular evaluation, offering an in-depth understanding of LLM's capability on diverse clinical tasks of desired granularity. We conduct a zero-shot evaluation of leading LLMs to assess their proficiency in clinical decision-making. Our preliminary results shed light on the potential and limitations of current LLMs in clinical settings, providing valuable insights for future advancements in LLM-powered healthcare.
6/17/2024
💬
Evaluating large language models in medical applications: a survey
Xiaolan Chen, Jiayang Xiang, Shanfu Lu, Yexin Liu, Mingguang He, Danli Shi
0
0
Large language models (LLMs) have emerged as powerful tools with transformative potential across numerous domains, including healthcare and medicine. In the medical domain, LLMs hold promise for tasks ranging from clinical decision support to patient education. However, evaluating the performance of LLMs in medical contexts presents unique challenges due to the complex and critical nature of medical information. This paper provides a comprehensive overview of the landscape of medical LLM evaluation, synthesizing insights from existing studies and highlighting evaluation data sources, task scenarios, and evaluation methods. Additionally, it identifies key challenges and opportunities in medical LLM evaluation, emphasizing the need for continued research and innovation to ensure the responsible integration of LLMs into clinical practice.
5/14/2024

Benchmarking Large Language Models on Answering and Explaining Challenging Medical Questions
Hanjie Chen, Zhouxiang Fang, Yash Singla, Mark Dredze
0
0
LLMs have demonstrated impressive performance in answering medical questions, such as achieving passing scores on medical licensing examinations. However, medical board exam or general clinical questions do not capture the complexity of realistic clinical cases. Moreover, the lack of reference explanations means we cannot easily evaluate the reasoning of model decisions, a crucial component of supporting doctors in making complex medical decisions. To address these challenges, we construct two new datasets: JAMA Clinical Challenge and Medbullets. JAMA Clinical Challenge consists of questions based on challenging clinical cases, while Medbullets comprises simulated clinical questions. Both datasets are structured as multiple-choice question-answering tasks, accompanied by expert-written explanations. We evaluate seven LLMs on the two datasets using various prompts. Experiments demonstrate that our datasets are harder than previous benchmarks. Human and automatic evaluations of model-generated explanations provide insights into the promise and deficiency of LLMs for explainable medical QA.
6/27/2024
🤯
D-NLP at SemEval-2024 Task 2: Evaluating Clinical Inference Capabilities of Large Language Models
Duygu Altinok
0
0
Large language models (LLMs) have garnered significant attention and widespread usage due to their impressive performance in various tasks. However, they are not without their own set of challenges, including issues such as hallucinations, factual inconsistencies, and limitations in numerical-quantitative reasoning. Evaluating LLMs in miscellaneous reasoning tasks remains an active area of research. Prior to the breakthrough of LLMs, Transformers had already proven successful in the medical domain, effectively employed for various natural language understanding (NLU) tasks. Following this trend, LLMs have also been trained and utilized in the medical domain, raising concerns regarding factual accuracy, adherence to safety protocols, and inherent limitations. In this paper, we focus on evaluating the natural language inference capabilities of popular open-source and closed-source LLMs using clinical trial reports as the dataset. We present the performance results of each LLM and further analyze their performance on a development set, particularly focusing on challenging instances that involve medical abbreviations and require numerical-quantitative reasoning. Gemini, our leading LLM, achieved a test set F1-score of 0.748, securing the ninth position on the task scoreboard. Our work is the first of its kind, offering a thorough examination of the inference capabilities of LLMs within the medical domain.
5/8/2024