MedFuzz: Exploring the Robustness of Large Language Models in Medical Question Answering
2406.06573
0
0

Abstract
Large language models (LLM) have achieved impressive performance on medical question-answering benchmarks. However, high benchmark accuracy does not imply that the performance generalizes to real-world clinical settings. Medical question-answering benchmarks rely on assumptions consistent with quantifying LLM performance but that may not hold in the open world of the clinic. Yet LLMs learn broad knowledge that can help the LLM generalize to practical conditions regardless of unrealistic assumptions in celebrated benchmarks. We seek to quantify how well LLM medical question-answering benchmark performance generalizes when benchmark assumptions are violated. Specifically, we present an adversarial method that we call MedFuzz (for medical fuzzing). MedFuzz attempts to modify benchmark questions in ways aimed at confounding the LLM. We demonstrate the approach by targeting strong assumptions about patient characteristics presented in the MedQA benchmark. Successful attacks modify a benchmark item in ways that would be unlikely to fool a medical expert but nonetheless trick the LLM into changing from a correct to an incorrect answer. Further, we present a permutation test technique that can ensure a successful attack is statistically significant. We show how to use performance on a MedFuzzed benchmark, as well as individual successful attacks. The methods show promise at providing insights into the ability of an LLM to operate robustly in more realistic settings.
Create account to get full access
Overview
- This paper, "MedFuzz: Exploring the Robustness of Large Language Models in Medical Question Answering," investigates the reliability and resilience of large language models (LLMs) in answering medical questions.
- The researchers assess the performance of LLMs on the MedExpQA and MedReQA datasets, which are medical question-answering benchmarks.
- They explore the impact of adversarial attacks, which are small, carefully crafted changes to the input that can cause LLMs to produce incorrect or nonsensical outputs.
Plain English Explanation
Large language models (LLMs) are powerful artificial intelligence systems that can understand and generate human-like text. These models have shown impressive performance on various tasks, including answering medical questions. However, it's important to understand how robust and reliable these models are, especially in sensitive domains like healthcare.
In this research, the authors investigate the resilience of LLMs to adversarial attacks in the context of medical question answering. Adversarial attacks are small, intentional modifications to the input that can cause LLMs to produce incorrect or nonsensical outputs. The researchers assess the performance of LLMs on two medical question-answering datasets, MedExpQA and MedReQA, and then apply various adversarial attacks to see how the models respond.
By understanding the vulnerabilities of LLMs in medical question answering, the researchers aim to help develop more robust and reliable AI systems for healthcare applications. This is crucial, as patients and healthcare providers need to be able to trust the outputs of these models, especially when making important medical decisions.
Technical Explanation
The researchers evaluate the robustness of large language models (LLMs) in the domain of medical question answering using the MedExpQA and MedReQA datasets. These datasets test the ability of LLMs to answer medical questions and provide explanations for their answers.
The researchers first assess the baseline performance of several state-of-the-art LLMs, including BERT, RoBERTa, and GPT-3, on the MedExpQA and MedReQA tasks. They then apply a range of adversarial attacks to the input questions, such as adding or removing words, synonymous substitutions, and paraphrasing. These attacks are designed to test the resilience of the LLMs to small perturbations in the input.
The results show that the LLMs generally perform well on the medical question-answering tasks, but their performance degrades significantly when faced with adversarial attacks. The models struggle to maintain their accuracy and the quality of their explanations, suggesting that they may not be as robust as previously thought.
The researchers also investigate the relationship between the LLMs' performance and the type of adversarial attack, as well as the model architecture and size. They find that larger models tend to be more resilient to certain types of attacks, but are still vulnerable to more sophisticated adversarial techniques.
Overall, the findings of this study highlight the importance of evaluating the robustness of LLMs, especially in sensitive domains like healthcare. The researchers suggest that future work should focus on developing more robust and secure AI systems for medical applications, to ensure that patients and healthcare providers can trust the outputs of these models.
Critical Analysis
The researchers in this paper have made a valuable contribution to understanding the robustness of large language models (LLMs) in the context of medical question answering. By applying adversarial attacks to the MedExpQA and MedReQA datasets, they have uncovered important vulnerabilities in the performance of these models.
One limitation of the study is that it focuses solely on the robustness of LLMs, without addressing the broader question of their reliability and trustworthiness in medical applications. While adversarial attacks are a crucial concern, there may be other factors, such as dataset bias, model transparency, and the interpretability of explanations, that also impact the suitability of LLMs for healthcare tasks.
Additionally, the researchers do not provide a detailed analysis of the types of errors made by the LLMs under adversarial attacks, or the potential consequences of such errors in a real-world medical setting. Further investigation into the specific failure modes and their implications could help inform the design of more robust and reliable AI systems for healthcare.
It would also be interesting to see the researchers explore approaches to improving the resilience of LLMs, such as adversarial training or the use of specialized architectures and loss functions. This could help bridge the gap between the current limitations of these models and the high standards required for their deployment in critical domains like medicine.
Overall, this paper represents an important step towards understanding the challenges and risks associated with the use of LLMs in medical question answering. By continuing to explore these issues, the research community can work towards developing AI systems that are truly trustworthy and suitable for deployment in healthcare applications.
Conclusion
The paper "MedFuzz: Exploring the Robustness of Large Language Models in Medical Question Answering" investigates the resilience of large language models (LLMs) to adversarial attacks in the context of medical question answering. The researchers assess the performance of various LLMs on the MedExpQA and MedReQA datasets, and then apply a range of adversarial techniques to uncover the vulnerabilities of these models.
The findings suggest that while LLMs can perform well on medical question-answering tasks, their performance is significantly degraded when faced with adversarial attacks. This raises important concerns about the reliability and trustworthiness of these models in sensitive domains like healthcare, where patients and providers need to have confidence in the outputs.
The paper highlights the need for further research into developing more robust and secure AI systems for medical applications. This could involve exploring approaches to improving the resilience of LLMs, as well as investigating other factors that may impact their suitability for healthcare tasks, such as dataset bias, model interpretability, and the potential consequences of errors.
By continuing to study the limitations and vulnerabilities of LLMs, the research community can work towards creating AI systems that are truly trustworthy and capable of providing reliable support to healthcare professionals and patients alike.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
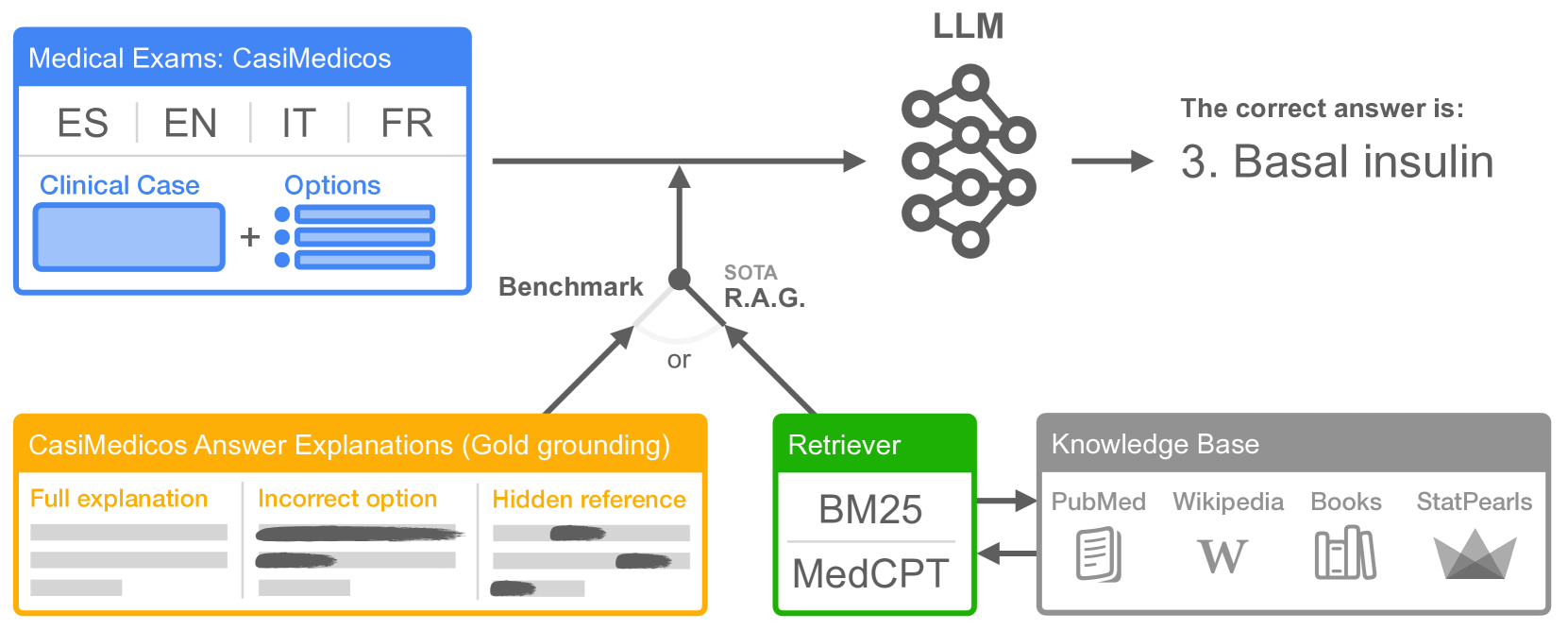
MedExpQA: Multilingual Benchmarking of Large Language Models for Medical Question Answering
I~nigo Alonso, Maite Oronoz, Rodrigo Agerri
0
0
Large Language Models (LLMs) have the potential of facilitating the development of Artificial Intelligence technology to assist medical experts for interactive decision support, which has been demonstrated by their competitive performances in Medical QA. However, while impressive, the required quality bar for medical applications remains far from being achieved. Currently, LLMs remain challenged by outdated knowledge and by their tendency to generate hallucinated content. Furthermore, most benchmarks to assess medical knowledge lack reference gold explanations which means that it is not possible to evaluate the reasoning of LLMs predictions. Finally, the situation is particularly grim if we consider benchmarking LLMs for languages other than English which remains, as far as we know, a totally neglected topic. In order to address these shortcomings, in this paper we present MedExpQA, the first multilingual benchmark based on medical exams to evaluate LLMs in Medical Question Answering. To the best of our knowledge, MedExpQA includes for the first time reference gold explanations written by medical doctors which can be leveraged to establish various gold-based upper-bounds for comparison with LLMs performance. Comprehensive multilingual experimentation using both the gold reference explanations and Retrieval Augmented Generation (RAG) approaches show that performance of LLMs still has large room for improvement, especially for languages other than English. Furthermore, and despite using state-of-the-art RAG methods, our results also demonstrate the difficulty of obtaining and integrating readily available medical knowledge that may positively impact results on downstream evaluations for Medical Question Answering. So far the benchmark is available in four languages, but we hope that this work may encourage further development to other languages.
4/9/2024
Large Language Models in Healthcare: A Comprehensive Benchmark
Andrew Liu, Hongjian Zhou, Yining Hua, Omid Rohanian, Anshul Thakur, Lei Clifton, David A. Clifton
0
0
The adoption of large language models (LLMs) to assist clinicians has attracted remarkable attention. Existing works mainly adopt the close-ended question-answering (QA) task with answer options for evaluation. However, many clinical decisions involve answering open-ended questions without pre-set options. To better understand LLMs in the clinic, we construct a benchmark ClinicBench. We first collect eleven existing datasets covering diverse clinical language generation, understanding, and reasoning tasks. Furthermore, we construct six novel datasets and complex clinical tasks that are close to real-world practice, i.e., referral QA, treatment recommendation, hospitalization (long document) summarization, patient education, pharmacology QA and drug interaction for emerging drugs. We conduct an extensive evaluation of twenty-two LLMs under both zero-shot and few-shot settings. Finally, we invite medical experts to evaluate the clinical usefulness of LLMs.
6/27/2024

Benchmarking Large Language Models on Answering and Explaining Challenging Medical Questions
Hanjie Chen, Zhouxiang Fang, Yash Singla, Mark Dredze
0
0
LLMs have demonstrated impressive performance in answering medical questions, such as achieving passing scores on medical licensing examinations. However, medical board exam or general clinical questions do not capture the complexity of realistic clinical cases. Moreover, the lack of reference explanations means we cannot easily evaluate the reasoning of model decisions, a crucial component of supporting doctors in making complex medical decisions. To address these challenges, we construct two new datasets: JAMA Clinical Challenge and Medbullets. JAMA Clinical Challenge consists of questions based on challenging clinical cases, while Medbullets comprises simulated clinical questions. Both datasets are structured as multiple-choice question-answering tasks, accompanied by expert-written explanations. We evaluate seven LLMs on the two datasets using various prompts. Experiments demonstrate that our datasets are harder than previous benchmarks. Human and automatic evaluations of model-generated explanations provide insights into the promise and deficiency of LLMs for explainable medical QA.
6/27/2024

MedExQA: Medical Question Answering Benchmark with Multiple Explanations
Yunsoo Kim, Jinge Wu, Yusuf Abdulle, Honghan Wu
0
0
This paper introduces MedExQA, a novel benchmark in medical question-answering, to evaluate large language models' (LLMs) understanding of medical knowledge through explanations. By constructing datasets across five distinct medical specialties that are underrepresented in current datasets and further incorporating multiple explanations for each question-answer pair, we address a major gap in current medical QA benchmarks which is the absence of comprehensive assessments of LLMs' ability to generate nuanced medical explanations. Our work highlights the importance of explainability in medical LLMs, proposes an effective methodology for evaluating models beyond classification accuracy, and sheds light on one specific domain, speech language pathology, where current LLMs including GPT4 lack good understanding. Our results show generation evaluation with multiple explanations aligns better with human assessment, highlighting an opportunity for a more robust automated comprehension assessment for LLMs. To diversify open-source medical LLMs (currently mostly based on Llama2), this work also proposes a new medical model, MedPhi-2, based on Phi-2 (2.7B). The model outperformed medical LLMs based on Llama2-70B in generating explanations, showing its effectiveness in the resource-constrained medical domain. We will share our benchmark datasets and the trained model.
6/11/2024