MedPromptX: Grounded Multimodal Prompting for Chest X-ray Diagnosis

0

Sign in to get full access
Introduction
The provided text discusses how emerging machine learning and deep learning advancements are assisting radiologists in detecting chest X-ray abnormalities. While traditional diagnosis based solely on imaging data can be effective, incorporating patients' clinical history can significantly improve diagnostic outcomes, highlighting the importance of multimodal approaches.
The integration of electronic health records (EHR) has been challenged by its inherent incompleteness, with missing values and lack of normal ranges for laboratory tests complicating the interpretation of medical datasets. Large language models (LLMs) have shown promise in clinical prediction by fine-tuning with prompts leveraging structured EHR data.
The emergence of generalist models like BiomedGPT represents a major advancement in biomedical AI, handling various tasks across modalities and surpassing state-of-the-art results. Visual grounding techniques have also demonstrated progress in medical imaging, particularly in automating associations between image features and descriptive reports in CT imaging.
Despite these advancements, there remains a gap in the integration of multimodal data for enhancing diagnostic accuracy in chest X-ray analysis. The few-shot prompting technique enables rapid adaptation to new diagnostic tasks with minimal labeled data, empowering medical professionals to efficiently use accurate diagnostic solutions tailored to specific patient cases. However, the quality and quantity of the few-shot data play a pivotal role in influencing performance.
The text introduces MedPromptX, a novel diagnostic model for chest X-ray images that integrates multimodal LLMs, few-shot prompting, and visual grounding to address the challenge of incomplete EHR data and enhance diagnostic accuracy. Additionally, the authors propose a dynamic proximity selection (DPS) technique that refines the few-shot data in real-time, allowing the model to capture the nuanced relationships between patient history and patient outcomes.
Methodology
This paper presents MedPromptX, a framework for medical diagnosis using a four-phase process. The key components are:
Visual Grounding (VG): This module uses Grounding DINO to detect regions of interest in chest X-ray images and generate grounded image representations.
Dynamic Proximity Selection (DPS): This method refines the candidate samples by ordering them based on their proximity to the query sample, using a distance function like cosine similarity. This enhances the robustness and adaptability of the few-shot learning approach.
Multimodal Large Language Model (MLLM): The paper uses the Med-Flamingo model, based on the Flamingo framework, to process the interleaved image and text inputs and predict the likelihood of the text sequence conditioned on the accompanying image.
The authors also describe the creation of the MedPromptX-VQA dataset, which combines data from the MIMIC-IV and MIMIC-CXR databases to focus on patients with chest X-ray procedures. The dataset covers 12 pathological conditions and is structured to support in-context learning tasks.
Experimental Setup
The paper employed a randomized order strategy for the input sequences across several state-of-the-art models, including Med-Flamingo, OpenFlamingo, BioMedLM, and Clinical-T5-Large. The number of few-shot samples was consistent at 6 across all models, chosen randomly. For MedPromptX, the number of few-shot candidates is dynamically reduced by the DPS technique, resulting in a unique configuration for each query instance. The experiments were conducted using NVIDIA A100-SXM GPUs with 40GB of dedicated memory.
The paper describes the models used in the study. Med-Flamingo and OpenFlamingo ingest interleaved image and text, excluding electronic health record (EHR) data, while BioMedLM and Clinical-T5 use text, including EHR data. MedPromptX is the only model that processes interleaved grounded or original image and EHR text prompt.
The paper provides examples of the different prompt types used in the study: image and text, EHR text, and image with EHR text.
Results and Discussion
The results in this paper show the complexity of medical diagnosis, where combining multiple data sources like imaging and clinical text can lead to better model performance. The MedPromptX approach integrates these diverse data sources, but initial attempts faced challenges. The use of Data Prompt Synthesis (DPS) and Visual Guidance (VG) strategies helped overcome these obstacles.
DPS reduces the number of ambiguous examples, allowing the model to learn more effectively from limited data. In contrast, a random configuration of Feature Prompts (FP) can introduce biases. VG enables the model to focus on relevant regions within images by generating semantic output embeddings, rather than working with raw pixel data. However, the performance gap when using VG alone may be due to the model being trained on general domain data instead of chest X-ray images.
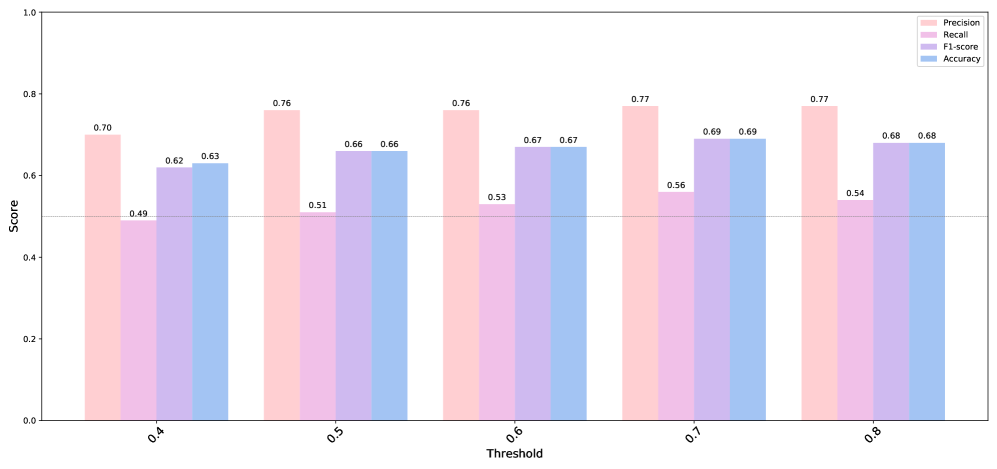
The paper's ablation studies show that initializing DPS with more examples improves generalization, though a 6-shot setting balances performance and class inclusion. Zero-shot assessment was not feasible due to model hallucination, underscoring the need for FP. Adjusting the DPS threshold can significantly impact performance, and using multimodal similarity enhances the instance selection process compared to single-modality approaches.
Conclusion
MedPromptX is a new model that combines a patient's clinical history with imaging data to accurately diagnose chest X-rays. The model addresses issues with incomplete medical data, adapting to new patients with limited labeled data, and detecting abnormalities in X-ray images. While the paper did not explore using fine-tuned backbones, which could further improve performance, future work may focus on accessing diverse, well-annotated datasets. Additionally, rigorous clinical trials and real-world deployment are necessary to validate the model's effectiveness and clinical usefulness.
Appendix 0.A Appendix
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MedPromptX: Grounded Multimodal Prompting for Chest X-ray Diagnosis
Mai A. Shaaban, Adnan Khan, Mohammad Yaqub
Chest X-ray images are commonly used for predicting acute and chronic cardiopulmonary conditions, but efforts to integrate them with structured clinical data face challenges due to incomplete electronic health records (EHR). This paper introduces MedPromptX, the first model to integrate multimodal large language models (MLLMs), few-shot prompting (FP) and visual grounding (VG) to combine imagery with EHR data for chest X-ray diagnosis. A pre-trained MLLM is utilized to complement the missing EHR information, providing a comprehensive understanding of patients' medical history. Additionally, FP reduces the necessity for extensive training of MLLMs while effectively tackling the issue of hallucination. Nevertheless, the process of determining the optimal number of few-shot examples and selecting high-quality candidates can be burdensome, yet it profoundly influences model performance. Hence, we propose a new technique that dynamically refines few-shot data for real-time adjustment to new patient scenarios. Moreover, VG aids in focusing the model's attention on relevant regions of interest in X-ray images, enhancing the identification of abnormalities. We release MedPromptX-VQA, a new in-context visual question answering dataset encompassing interleaved image and EHR data derived from MIMIC-IV and MIMIC-CXR databases. Results demonstrate the SOTA performance of MedPromptX, achieving an 11% improvement in F1-score compared to the baselines. Code and data are available at https://github.com/BioMedIA-MBZUAI/MedPromptX
Read more4/1/2024
🖼️
0
Pseudo-Prompt Generating in Pre-trained Vision-Language Models for Multi-Label Medical Image Classification
Yaoqin Ye, Junjie Zhang, Hongwei Shi
The task of medical image recognition is notably complicated by the presence of varied and multiple pathological indications, presenting a unique challenge in multi-label classification with unseen labels. This complexity underlines the need for computer-aided diagnosis methods employing multi-label zero-shot learning. Recent advancements in pre-trained vision-language models (VLMs) have showcased notable zero-shot classification abilities on medical images. However, these methods have limitations on leveraging extensive pre-trained knowledge from broader image datasets, and often depend on manual prompt construction by expert radiologists. By automating the process of prompt tuning, prompt learning techniques have emerged as an efficient way to adapt VLMs to downstream tasks. Yet, existing CoOp-based strategies fall short in performing class-specific prompts on unseen categories, limiting generalizability in fine-grained scenarios. To overcome these constraints, we introduce a novel prompt generation approach inspirited by text generation in natural language processing (NLP). Our method, named Pseudo-Prompt Generating (PsPG), capitalizes on the priori knowledge of multi-modal features. Featuring a RNN-based decoder, PsPG autoregressively generates class-tailored embedding vectors, i.e., pseudo-prompts. Comparative evaluations on various multi-label chest radiograph datasets affirm the superiority of our approach against leading medical vision-language and multi-label prompt learning methods. The source code is available at https://github.com/fallingnight/PsPG
Read more9/16/2024

0
PM2: A New Prompting Multi-modal Model Paradigm for Few-shot Medical Image Classification
Zhenwei Wang, Qiule Sun, Bingbing Zhang, Pengfei Wang, Jianxin Zhang, Qiang Zhang
Few-shot learning has been successfully applied to medical image classification as only very few medical examples are available for training. Due to the challenging problem of limited number of annotated medical images, image representations should not be solely derived from a single image modality which is insufficient for characterizing concept classes. In this paper, we propose a new prompting multi-modal model paradigm on medical image classification based on multi-modal foundation models, called PM2. Besides image modality,PM2 introduces another supplementary text input, known as prompt, to further describe corresponding image or concept classes and facilitate few-shot learning across diverse modalities. To better explore the potential of prompt engineering, we empirically investigate five distinct prompt schemes under the new paradigm. Furthermore, linear probing in multi-modal models acts as a linear classification head taking as input only class token, which ignores completely merits of rich statistics inherent in high-level visual tokens. Thus, we alternatively perform a linear classification on feature distribution of visual tokens and class token simultaneously. To effectively mine such rich statistics, a global covariance pooling with efficient matrix power normalization is used to aggregate visual tokens. Then we study and combine two classification heads. One is shared for class token of image from vision encoder and prompt representation encoded by text encoder. The other is to classification on feature distribution of visual tokens from vision encoder. Extensive experiments on three medical datasets show that our PM2 significantly outperforms counterparts regardless of prompt schemes and achieves state-of-the-art performance.
Read more5/28/2024

0
MMGPL: Multimodal Medical Data Analysis with Graph Prompt Learning
Liang Peng, Songyue Cai, Zongqian Wu, Huifang Shang, Xiaofeng Zhu, Xiaoxiao Li
Prompt learning has demonstrated impressive efficacy in the fine-tuning of multimodal large models to a wide range of downstream tasks. Nonetheless, applying existing prompt learning methods for the diagnosis of neurological disorder still suffers from two issues: (i) existing methods typically treat all patches equally, despite the fact that only a small number of patches in neuroimaging are relevant to the disease, and (ii) they ignore the structural information inherent in the brain connection network which is crucial for understanding and diagnosing neurological disorders. To tackle these issues, we introduce a novel prompt learning model by learning graph prompts during the fine-tuning process of multimodal large models for diagnosing neurological disorders. Specifically, we first leverage GPT-4 to obtain relevant disease concepts and compute semantic similarity between these concepts and all patches. Secondly, we reduce the weight of irrelevant patches according to the semantic similarity between each patch and disease-related concepts. Moreover, we construct a graph among tokens based on these concepts and employ a graph convolutional network layer to extract the structural information of the graph, which is used to prompt the pre-trained multimodal large models for diagnosing neurological disorders. Extensive experiments demonstrate that our method achieves superior performance for neurological disorder diagnosis compared with state-of-the-art methods and validated by clinicians.
Read more6/28/2024