Mesh2NeRF: Direct Mesh Supervision for Neural Radiance Field Representation and Generation

0
Sign in to get full access
Overview
- Mesh2NeRF: a method for generating Neural Radiance Fields (NeRFs) from 3D mesh data
- Directly supervises NeRF generation using the 3D mesh as a prior, improving performance compared to previous NeRF methods
- Enables high-quality novel view synthesis from 3D meshes without requiring multi-view images
Plain English Explanation
Mesh2NeRF is a new technique for creating Neural Radiance Fields (NeRFs) from 3D mesh data. NeRFs are a type of 3D representation that can be used for generating realistic images of objects or scenes from any viewpoint.
The key innovation of Mesh2NeRF is that it directly uses the 3D mesh as a form of supervision during the NeRF generation process. This means the NeRF model is trained to accurately recreate the underlying 3D mesh, which helps it learn a higher-quality 3D representation compared to previous NeRF methods that did not have this direct mesh supervision.
By leveraging the 3D mesh as a prior, Mesh2NeRF is able to generate NeRFs that can produce high-quality novel views of an object or scene, even if only a single 3D mesh is provided as input. This is a significant advantage over other NeRF approaches that typically require multiple images from different viewpoints to work well.
Technical Explanation
The core idea behind Mesh2NeRF is to directly supervise the NeRF generation process using the 3D mesh as a prior. Previous NeRF methods relied on multi-view images as the main source of supervision, which can be time-consuming and expensive to obtain.
Mesh2NeRF works by first encoding the 3D mesh into a latent representation using a graph neural network. This latent code is then used to condition the NeRF network, which learns to generate the radiance field that best matches the underlying mesh structure.
The authors propose several novel loss functions that encourage the NeRF to faithfully reproduce the 3D mesh, such as matching the surface geometry, normal vectors, and silhouette. This direct mesh supervision helps the NeRF learn a more accurate 3D representation compared to prior techniques.
Experiments show that Mesh2NeRF outperforms state-of-the-art NeRF methods on a variety of 3D reconstruction and novel view synthesis tasks, particularly when only a single 3D mesh is available as input. The authors also demonstrate that Mesh2NeRF can be used for interactive 3D editing by allowing users to modify the input mesh and see the corresponding changes in the generated NeRF.
Critical Analysis
One potential limitation of Mesh2NeRF is that it relies on the availability of high-quality 3D mesh data, which may not always be easy to obtain, especially for real-world objects and scenes. The authors note that their method may struggle with meshes that have topological or geometric errors, which could impact the quality of the generated NeRFs.
Additionally, the computational complexity of Mesh2NeRF may be higher than some other NeRF approaches, due to the additional steps required to encode and condition the NeRF on the 3D mesh data. This could impact the scalability of the method, especially for large or complex 3D models.
Further research could explore ways to make Mesh2NeRF more robust to imperfect mesh data, or investigate techniques to reduce the computational overhead of the mesh encoding and conditioning processes. Exploring the integration of Mesh2NeRF with other 3D reconstruction methods could also be a fruitful area for future work.
Conclusion
Mesh2NeRF represents a significant advancement in the field of neural radiance field generation by directly leveraging 3D mesh data as a source of supervision. This novel approach enables high-quality novel view synthesis from a single 3D mesh, without requiring multi-view image data.
The ability to generate NeRFs from 3D meshes has important implications for a wide range of applications, including interactive 3D content creation, virtual and augmented reality, and 3D reconstruction of indoor environments. As the field of neural rendering continues to advance, techniques like Mesh2NeRF will play an increasingly important role in bridging the gap between 3D geometry and photorealistic image synthesis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Mesh2NeRF: Direct Mesh Supervision for Neural Radiance Field Representation and Generation
Yujin Chen, Yinyu Nie, Benjamin Ummenhofer, Reiner Birkl, Michael Paulitsch, Matthias Muller, Matthias Nie{ss}ner
We present Mesh2NeRF, an approach to derive ground-truth radiance fields from textured meshes for 3D generation tasks. Many 3D generative approaches represent 3D scenes as radiance fields for training. Their ground-truth radiance fields are usually fitted from multi-view renderings from a large-scale synthetic 3D dataset, which often results in artifacts due to occlusions or under-fitting issues. In Mesh2NeRF, we propose an analytic solution to directly obtain ground-truth radiance fields from 3D meshes, characterizing the density field with an occupancy function featuring a defined surface thickness, and determining view-dependent color through a reflection function considering both the mesh and environment lighting. Mesh2NeRF extracts accurate radiance fields which provides direct supervision for training generative NeRFs and single scene representation. We validate the effectiveness of Mesh2NeRF across various tasks, achieving a noteworthy 3.12dB improvement in PSNR for view synthesis in single scene representation on the ABO dataset, a 0.69 PSNR enhancement in the single-view conditional generation of ShapeNet Cars, and notably improved mesh extraction from NeRF in the unconditional generation of Objaverse Mugs.
Read more9/6/2024

0
$R^2$-Mesh: Reinforcement Learning Powered Mesh Reconstruction via Geometry and Appearance Refinement
Haoyang Wang, Liming Liu, Quanlu Jia, Jiangkai Wu, Haodan Zhang, Peiheng Wang, Xinggong Zhang
Mesh reconstruction based on Neural Radiance Fields (NeRF) is popular in a variety of applications such as computer graphics, virtual reality, and medical imaging due to its efficiency in handling complex geometric structures and facilitating real-time rendering. However, existing works often fail to capture fine geometric details accurately and struggle with optimizing rendering quality. To address these challenges, we propose a novel algorithm that progressively generates and optimizes meshes from multi-view images. Our approach initiates with the training of a NeRF model to establish an initial Signed Distance Field (SDF) and a view-dependent appearance field. Subsequently, we iteratively refine the SDF through a differentiable mesh extraction method, continuously updating both the vertex positions and their connectivity based on the loss from mesh differentiable rasterization, while also optimizing the appearance representation. To further leverage high-fidelity and detail-rich representations from NeRF, we propose an online-learning strategy based on Upper Confidence Bound (UCB) to enhance viewpoints by adaptively incorporating images rendered by the initial NeRF model into the training dataset. Through extensive experiments, we demonstrate that our method delivers highly competitive and robust performance in both mesh rendering quality and geometric quality.
Read more8/20/2024
🧠
0
Points2NeRF: Generating Neural Radiance Fields from 3D point cloud
Dominik Zimny, Joanna Waczy'nska, Tomasz Trzci'nski, Przemys{l}aw Spurek
Contemporary registration devices for 3D visual information, such as LIDARs and various depth cameras, capture data as 3D point clouds. In turn, such clouds are challenging to be processed due to their size and complexity. Existing methods address this problem by fitting a mesh to the point cloud and rendering it instead. This approach, however, leads to the reduced fidelity of the resulting visualization and misses color information of the objects crucial in computer graphics applications. In this work, we propose to mitigate this challenge by representing 3D objects as Neural Radiance Fields (NeRFs). We leverage a hypernetwork paradigm and train the model to take a 3D point cloud with the associated color values and return a NeRF network's weights that reconstruct 3D objects from input 2D images. Our method provides efficient 3D object representation and offers several advantages over the existing approaches, including the ability to condition NeRFs and improved generalization beyond objects seen in training. The latter we also confirmed in the results of our empirical evaluation.
Read more6/13/2024
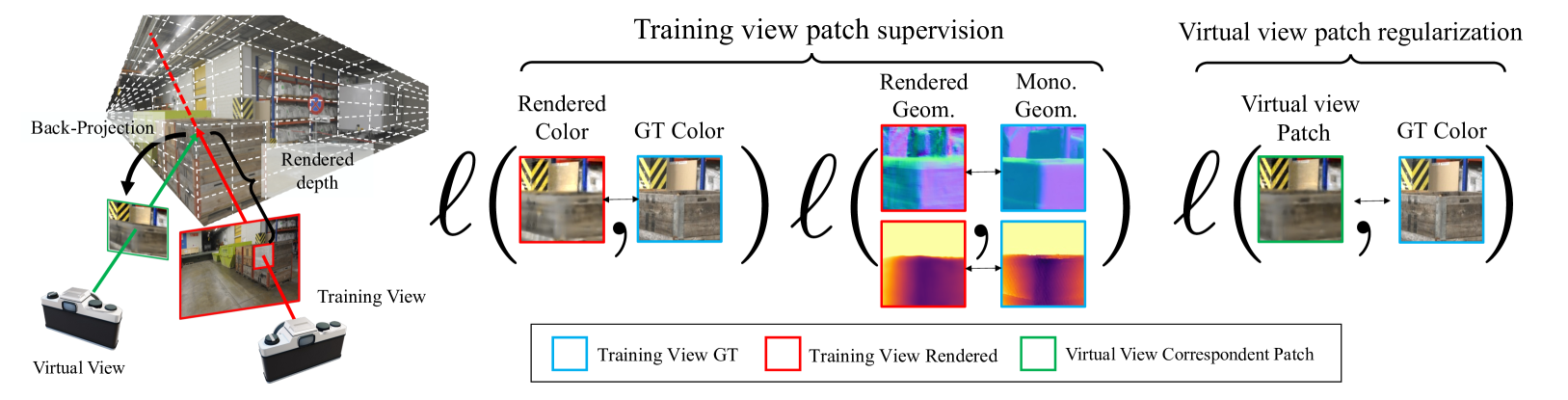
0
MonoPatchNeRF: Improving Neural Radiance Fields with Patch-based Monocular Guidance
Yuqun Wu, Jae Yong Lee, Chuhang Zou, Shenlong Wang, Derek Hoiem
The latest regularized Neural Radiance Field (NeRF) approaches produce poor geometry and view extrapolation for large scale sparse view scenes, such as ETH3D. Density-based approaches tend to be under-constrained, while surface-based approaches tend to miss details. In this paper, we take a density-based approach, sampling patches instead of individual rays to better incorporate monocular depth and normal estimates and patch-based photometric consistency constraints between training views and sampled virtual views. Loosely constraining densities based on estimated depth aligned to sparse points further improves geometric accuracy. While maintaining similar view synthesis quality, our approach significantly improves geometric accuracy on the ETH3D benchmark, e.g. increasing the F1@2cm score by 4x-8x compared to other regularized density-based approaches, with much lower training and inference time than other approaches.
Read more8/23/2024