MetaCloak: Preventing Unauthorized Subject-driven Text-to-image Diffusion-based Synthesis via Meta-learning
2311.13127
0
0
✨
Abstract
Text-to-image diffusion models allow seamless generation of personalized images from scant reference photos. Yet, these tools, in the wrong hands, can fabricate misleading or harmful content, endangering individuals. To address this problem, existing poisoning-based approaches perturb user images in an imperceptible way to render them unlearnable from malicious uses. We identify two limitations of these defending approaches: i) sub-optimal due to the hand-crafted heuristics for solving the intractable bilevel optimization and ii) lack of robustness against simple data transformations like Gaussian filtering. To solve these challenges, we propose MetaCloak, which solves the bi-level poisoning problem with a meta-learning framework with an additional transformation sampling process to craft transferable and robust perturbation. Specifically, we employ a pool of surrogate diffusion models to craft transferable and model-agnostic perturbation. Furthermore, by incorporating an additional transformation process, we design a simple denoising-error maximization loss that is sufficient for causing transformation-robust semantic distortion and degradation in a personalized generation. Extensive experiments on the VGGFace2 and CelebA-HQ datasets show that MetaCloak outperforms existing approaches. Notably, MetaCloak can successfully fool online training services like Replicate, in a black-box manner, demonstrating the effectiveness of MetaCloak in real-world scenarios. Our code is available at https://github.com/liuyixin-louis/MetaCloak.
Get summaries of the top AI research delivered straight to your inbox:
Overview
• Text-to-image diffusion models can generate personalized images from reference photos, but can also be used to create misleading or harmful content.
• Existing approaches try to defend against this by imperceptibly perturbing user images to make them unlearnable by malicious models.
• However, these approaches have limitations, such as using hand-crafted heuristics and lacking robustness to simple data transformations.
Plain English Explanation
Advances in AI have led to the development of powerful text-to-image diffusion models. These tools can take a written description and generate a custom image to match, like a digital artist painting from scratch. This opens up many interesting creative possibilities.
However, these same capabilities also raise concerns. In the wrong hands, these models could be used to fabricate images that are misleading or even harmful - for example, creating fake photos to defame someone. Existing defenses against this try to subtly alter users' images in a way that confuses the AI models, preventing them from learning the intended content. But these solutions have flaws - they rely on guesswork rather than systematic methods, and they can be defeated by simple image processing tricks.
The researchers propose a new approach called MetaCloak that aims to address these shortcomings. MetaCloak uses a more rigorous, learning-based technique to craft perturbations that are both effective at fooling malicious models and robust to common image transformations. This helps protect users from having their images exploited, while still allowing legitimate use of these powerful text-to-image tools.
Technical Explanation
The key technical contributions of MetaCloak are:
-
A meta-learning framework to solve the bilevel optimization problem of finding optimal perturbations, rather than relying on hand-crafted heuristics.
-
An additional transformation sampling process that makes the perturbations robust to common image manipulations like Gaussian filtering.
-
A denoising-error maximization loss that causes semantic distortion and degradation in the personalized image generation, even for transformed inputs.
Extensive experiments on facial image datasets show that MetaCloak outperforms prior poisoning-based defense approaches. It is also able to successfully fool real-world online AI services in a black-box manner, demonstrating its effectiveness in practical scenarios.
Critical Analysis
The paper identifies important limitations in existing defenses against malicious use of text-to-image models, and proposes a technically sophisticated solution in MetaCloak. However, a few potential issues are worth noting:
-
The paper does not explore the potential negative societal impacts of MetaCloak itself - if widely adopted, it could enable people to evade legitimate uses of these models, such as for content moderation.
-
The reliance on a pool of surrogate models may limit the real-world applicability if the attacker has knowledge of the specific models used.
-
The focus is on facial images, but the threat of malicious text-to-image generation extends to many other domains as well.
Further research is needed to fully understand the broader implications and potential misuses of both text-to-image models and defense techniques like MetaCloak.
Conclusion
Text-to-image diffusion models hold great creative potential, but also pose risks of misuse. MetaCloak represents an important technical advance in defending against malicious applications, using principled machine learning techniques to craft robust perturbations. However, the broader societal impacts of both the original models and the defense mechanisms merit careful consideration. As these technologies continue to evolve, ongoing dialogue and collaboration between researchers, developers, and the public will be crucial.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
DIAGNOSIS: Detecting Unauthorized Data Usages in Text-to-image Diffusion Models
Zhenting Wang, Chen Chen, Lingjuan Lyu, Dimitris N. Metaxas, Shiqing Ma
0
0
Recent text-to-image diffusion models have shown surprising performance in generating high-quality images. However, concerns have arisen regarding the unauthorized data usage during the training or fine-tuning process. One example is when a model trainer collects a set of images created by a particular artist and attempts to train a model capable of generating similar images without obtaining permission and giving credit to the artist. To address this issue, we propose a method for detecting such unauthorized data usage by planting the injected memorization into the text-to-image diffusion models trained on the protected dataset. Specifically, we modify the protected images by adding unique contents on these images using stealthy image warping functions that are nearly imperceptible to humans but can be captured and memorized by diffusion models. By analyzing whether the model has memorized the injected content (i.e., whether the generated images are processed by the injected post-processing function), we can detect models that had illegally utilized the unauthorized data. Experiments on Stable Diffusion and VQ Diffusion with different model training or fine-tuning methods (i.e, LoRA, DreamBooth, and standard training) demonstrate the effectiveness of our proposed method in detecting unauthorized data usages. Code: https://github.com/ZhentingWang/DIAGNOSIS.
4/10/2024
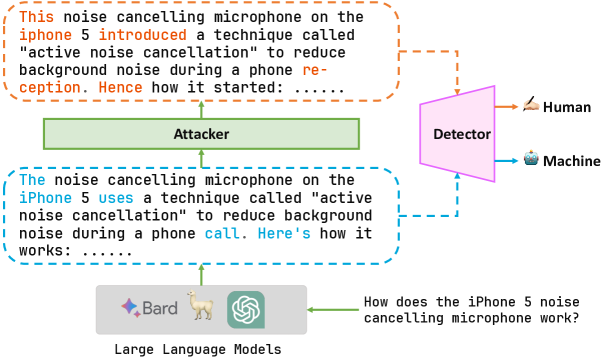
Humanizing Machine-Generated Content: Evading AI-Text Detection through Adversarial Attack
Ying Zhou, Ben He, Le Sun
0
0
With the development of large language models (LLMs), detecting whether text is generated by a machine becomes increasingly challenging in the face of malicious use cases like the spread of false information, protection of intellectual property, and prevention of academic plagiarism. While well-trained text detectors have demonstrated promising performance on unseen test data, recent research suggests that these detectors have vulnerabilities when dealing with adversarial attacks such as paraphrasing. In this paper, we propose a framework for a broader class of adversarial attacks, designed to perform minor perturbations in machine-generated content to evade detection. We consider two attack settings: white-box and black-box, and employ adversarial learning in dynamic scenarios to assess the potential enhancement of the current detection model's robustness against such attacks. The empirical results reveal that the current detection models can be compromised in as little as 10 seconds, leading to the misclassification of machine-generated text as human-written content. Furthermore, we explore the prospect of improving the model's robustness over iterative adversarial learning. Although some improvements in model robustness are observed, practical applications still face significant challenges. These findings shed light on the future development of AI-text detectors, emphasizing the need for more accurate and robust detection methods.
4/3/2024
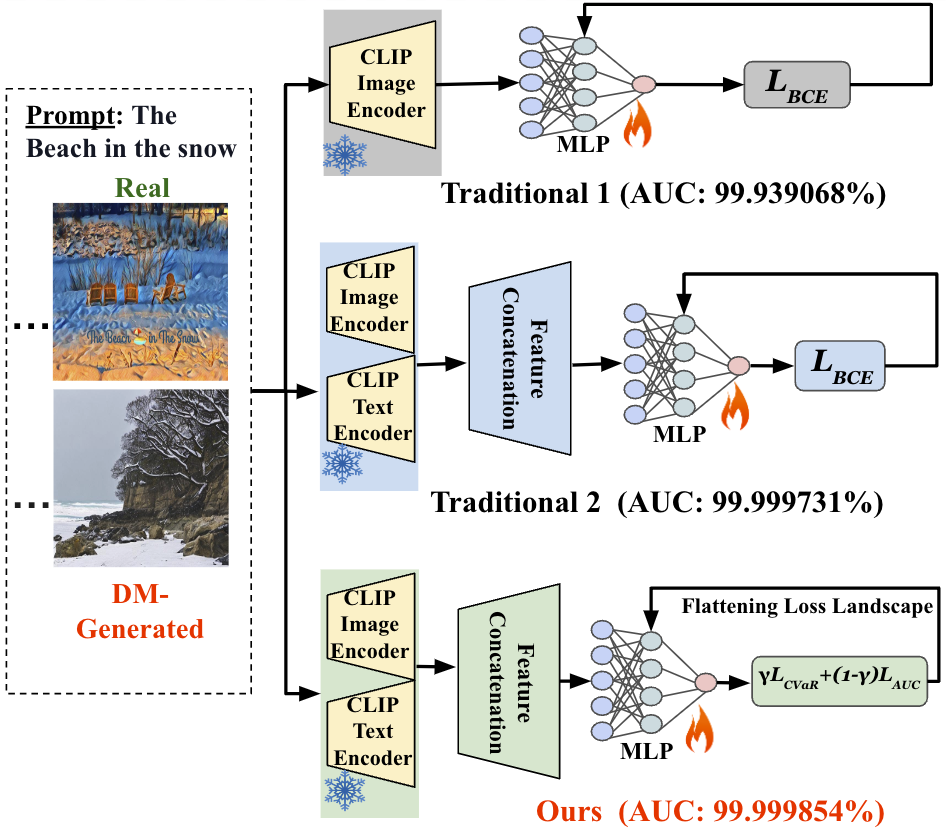
Robust CLIP-Based Detector for Exposing Diffusion Model-Generated Images
Santosh, Li Lin, Irene Amerini, Xin Wang, Shu Hu
0
0
Diffusion models (DMs) have revolutionized image generation, producing high-quality images with applications spanning various fields. However, their ability to create hyper-realistic images poses significant challenges in distinguishing between real and synthetic content, raising concerns about digital authenticity and potential misuse in creating deepfakes. This work introduces a robust detection framework that integrates image and text features extracted by CLIP model with a Multilayer Perceptron (MLP) classifier. We propose a novel loss that can improve the detector's robustness and handle imbalanced datasets. Additionally, we flatten the loss landscape during the model training to improve the detector's generalization capabilities. The effectiveness of our method, which outperforms traditional detection techniques, is demonstrated through extensive experiments, underscoring its potential to set a new state-of-the-art approach in DM-generated image detection. The code is available at https://github.com/Purdue-M2/Robust_DM_Generated_Image_Detection.
4/22/2024

SimAC: A Simple Anti-Customization Method for Protecting Face Privacy against Text-to-Image Synthesis of Diffusion Models
Feifei Wang, Zhentao Tan, Tianyi Wei, Yue Wu, Qidong Huang
0
0
Despite the success of diffusion-based customization methods on visual content creation, increasing concerns have been raised about such techniques from both privacy and political perspectives. To tackle this issue, several anti-customization methods have been proposed in very recent months, predominantly grounded in adversarial attacks. Unfortunately, most of these methods adopt straightforward designs, such as end-to-end optimization with a focus on adversarially maximizing the original training loss, thereby neglecting nuanced internal properties intrinsic to the diffusion model, and even leading to ineffective optimization in some diffusion time steps.In this paper, we strive to bridge this gap by undertaking a comprehensive exploration of these inherent properties, to boost the performance of current anti-customization approaches. Two aspects of properties are investigated: 1) We examine the relationship between time step selection and the model's perception in the frequency domain of images and find that lower time steps can give much more contributions to adversarial noises. This inspires us to propose an adaptive greedy search for optimal time steps that seamlessly integrates with existing anti-customization methods. 2) We scrutinize the roles of features at different layers during denoising and devise a sophisticated feature-based optimization framework for anti-customization.Experiments on facial benchmarks demonstrate that our approach significantly increases identity disruption, thereby protecting user privacy and copyright. Our code is available at: https://github.com/somuchtome/SimAC.
5/1/2024